.svg)
.svg)
.svg)
Subscribe to our newsletter - Data Engineering ACID
Share this article
.svg)
.svg)
The Lock Nobody Held: Deadlocking a Tokio Mutex Without Holding a Lock
March 23, 2026
/
Engineering
Deadlocks usually occur under very specific scenarios: someone grabs a lock and tries to acquire another lock (which is held by someone else). This scenario only had one lock. In a Rust app running on Tokio, we guarded a shared state with a single mutex. Under a specific workload, four futures would start, three would complete and the fourth would hang forever. Our logs showed that the lock had been released, but no future had acquired it. So what were the futures waiting for?
One obvious thing to look for is whether we were holding a std mutex across an .await. That’s such a classic mistake that clippy has a warning for it. But we were not doing that. We used a tokio::sync::Mutex to avoid exactly such issues. The explanation ended up being inside tokio’s internals. To be clear, this is not a tokio bug – we were holding these futures incorrectly.
Let’s start by breaking down the problem from our production code to a simple reproducer that can run on the Rust playground.
The Issue
The reproducer is relatively small. We have one tokio mutex being used by 4 workers concurrently. There’s a special PausableFuture that stops polling the inner future when it gets a signal. Also note that we’re using the current_thread flavour of tokio, which is single-threaded. Similar behavior is seen with a multi_thread runtime with 4 worker threads.
//! Reproducer: tokio::sync::Mutex deadlock with a single, unlocked mutex.
//!
//! Cargo.toml:
//! [dependencies]
//! tokio = { version = "1", features = ["full"] }
use std::future::Future;
use std::pin::Pin;
use std::sync::Arc;
use std::sync::atomic::{AtomicBool, Ordering};
use std::task::{Context, Poll};
use std::time::Duration;
use tokio::sync::Mutex;
/// Future wrapper that stops forwarding polls when `stopped` is set.
struct PausableFuture<F> {
inner: Pin<Box<F>>,
stopped: Arc<AtomicBool>,
}
impl<F: Future> Future for PausableFuture<F> {
type Output = F::Output;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
if self.stopped.load(Ordering::Acquire) {
return Poll::Pending;
}
self.inner.as_mut().poll(cx)
}
}
#[tokio::main(flavor = "current_thread")]
async fn main() {
let mutex = Arc::new(Mutex::new(()));
// Hold the lock so workers queue up.
let guard = mutex.lock().await;
println!("main acquired the lock");
// Spawn 4 workers, each wrapped in a PausableFuture.
// Each worker gets its own flag - whether to stop or not.
let stop_flags: Vec<_> = (0..4).map(|_| Arc::new(AtomicBool::new(false))).collect();
let mut handles = Vec::new();
for id in 0..4u32 {
let mutex = Arc::clone(&mutex);
let stopped = Arc::clone(&stop_flags[id as usize]);
handles.push(tokio::spawn(PausableFuture {
stopped,
inner: Box::pin(async move {
let guard = mutex.lock().await;
println!("worker {id}: acquired lock");
tokio::time::sleep(Duration::from_millis(100)).await;
drop(guard);
println!("worker {id}: released lock");
}),
}));
}
// Yield so all workers poll lock() and start waiting.
tokio::task::yield_now().await;
// Stop polling worker 1.
stop_flags[1].store(true, Ordering::Release);
// Release the lock. The mutex is now UNLOCKED.
drop(guard);
println!("main released the lock");
for (id, h) in handles.into_iter().enumerate() {
match tokio::time::timeout(std::time::Duration::from_secs(2), h).await {
Ok(Ok(())) => println!("worker {id}: done"),
Ok(Err(e)) => println!("worker {id}: error: {e}"),
Err(_) => println!("worker {id}: DEADLOCKED"),
}
}
}
Running it gives the following logs:
main acquired the lock
main released the lock
worker 0: acquired lock
worker 0: released lock
worker 0: done
worker 1: DEADLOCKED
worker 2: DEADLOCKED
worker 3: DEADLOCKED
We can see that both main and worker 0 have released the locks. No one is holding the lock, yet the other threads get deadlocked!
In our actual production code where we saw this behavior, it was not as straightforward. It’s a query engine built on DataFusion, which internally uses tokio. We were pausing some streams to resume them at a later point. The tokio mutex was only present in certain workloads, which means the stream was running fine in most cases. Instead of a PausableFuture that always returns Pending, we had a stream that ended itself cleanly.
Let’s now try to debug this deadlock.
Coffman conditions
One of the ways to figure out whether a given piece of code can deadlock is to check whether it satisfies all of the Coffman conditions:
- Mutual exclusion (only one process may use one resource at a time): this is the definition of a mutex. We are using a mutex, so this condition is satisfied.
- Hold and wait (one process is already holding a resource and waiting for another): there’s only one resource (one mutex), so this condition is not satisfied.
- No pre-emption (resources need to be voluntarily released by a process, it can’t be pre-empted forcefully from it): mutex lock can’t be pre-empted, hence satisfied.
- Circular wait (one process is waiting for a resource held by another process, which is in-turn waiting for the first process): all four workers are waiting for the same resource. There is no cycle. This condition is not satisfied.
Two of the four conditions aren’t met, so we should not run into a deadlock. To understand what's really going on, we need to look at how Rust futures and tokio's mutex actually work under the hood.
A short primer to async in Rust
For an in-depth explanation of async in Rust, see this tutorial by tokio. But for our purposes, we only need to know a few things. You can skip this section if you’re already familiar with async Rust.
Rust futures
Unlike async primitives of some other languages, futures in Rust are lazy. They do not perform any computation/action unless they are polled. Looking at the definition of the Future trait, we see that it has only one method called poll, which can either return Poll::Ready(_) with some return value or Poll::Pending indicating that it’s not complete yet. The future only makes progress if this poll method is called. For async work like a network call, or waiting for a mutex to unlock, it would be inefficient to busy poll i.e., calling the poll method repeatedly in a loop until it returns Ready. To avoid busy polling, Rust has a concept of wakers. Whenever a future returns Poll::Pending, it needs to register a waker that will get woken up once the condition it’s waiting on is satisfied.
An interesting side-effect of this is that cancellation becomes very easy. You can just drop a future instead of polling it and it’s cancelled.
Mutexes
In Rust, you’ll generally reach for one of these mutex implementations:
std::sync::Mutex(std mutex): a blocking mutex from the standard library. If it’s contended, it blocks the current OS thread. It works best for synchronous code, and it’s only safe in async code when you can guarantee the guard won’t be held across an.await.tokio::sync::Mutex(tokio mutex): an async-aware mutex. Acquiring it islock().await, so a contended lock yields instead of blocking an executor thread. Its core feature is that its guard can be held across.awaitpoints.
We chose the Tokio Mutex because we needed to call an async function while holding the lock. We were also careful about cancellation: dropping async work mid-flight can leave things in a weird state, and Tokio mutexes are not ‘cancellation safe’ by default, so you need to design around that. Even with that care, we still hit a hang.
What causes the deadlock?
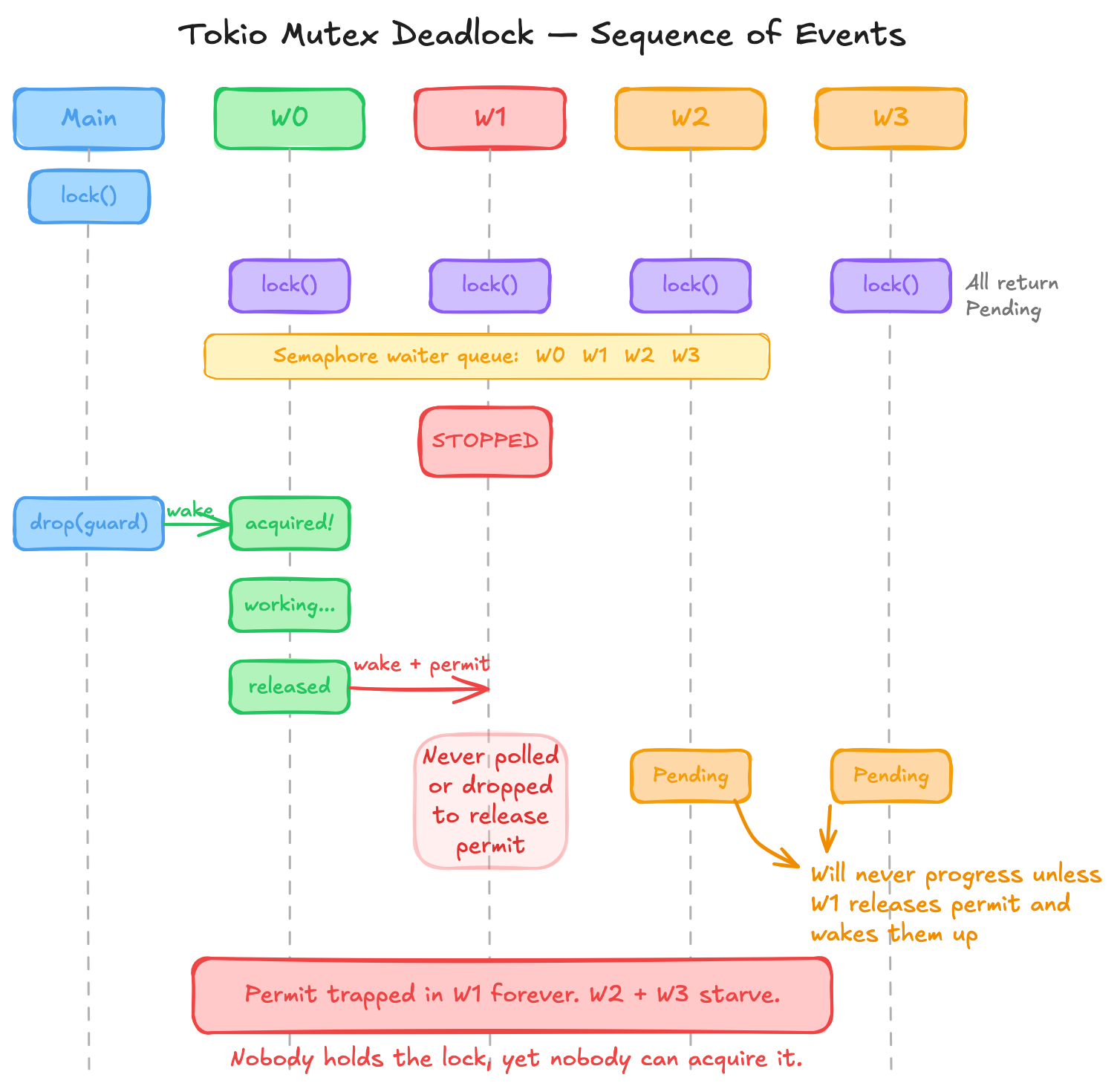
Sequence of events leading to the “deadlock”
The explanation lives inside Tokio internals, but the bug was in PausableFuture. Internally, tokio mutex uses a custom semaphore that in turn stores a queue of waiters. The semaphore stores 1 permit in case of a mutex. When a future finds no available permits, it gets added to the queue, along with a waker for that future. Once a future releases a permit, it consults the queue and wakes up one of the waiting futures immediately.
The sequence of operations goes like this:
- When our main function acquires the lock, the permits in the semaphore go down to 0 and the permit is held by the mutex guard.
- The workers then try to poll the lock, see that there’s no permits available and they get added to the waiters list (the latest waiters go to the front of the linked list using
push_front). The waker for each future is registered inside the semaphore waiter. - Once the main function releases the lock (by dropping the guard), it releases the semaphore permit. When it does so, it also gets the last waiter (oldest waiter) and wakes it.
- This wakes the future of worker 0 (or whichever worker first tried to acquire the mutex). It gets the semaphore permit and thus the mutex guard. Worker 0 completes its task and releases the mutex and the permit. Same as before, the last waiter gets woken up when the permit is released.
- Now, we wake up the future of worker 1. The
stopped flagfor this future is set to true. Any normal future would poll its inner future, butPausableFuturereturns aPoll::Pendingwhen it gets woken up. So the inner future, which got the semaphore permit, never gets polled. - The permit is held by the inner future forever. It can only acquire the lock and release the permit if it's either polled or dropped.
The issue is that tokio semaphore assigns the permit eagerly to the first waiter, even if that future is not polled again. But that’s not the core issue. There’s a contract violation here. PausableFuture got woken up by its inner future’s waker, but it never polled that inner future. The contract of a waker is that calling wake() will result in at least one poll of the future that registered the waker. Tokio’s semaphore assumes this is true, whereas PausableFuture violates it.
In this case, “pausing” a future is similar to cancelling it, except that the inner future is never dropped. There’s no chance to perform a clean up. Specifically, when a future containing a semaphore permit is dropped, the permit is released. If PausableFuture instead dropped its inner future when self.stopped became true, it would work just fine.
So what about the Coffman conditions?
We can look at acquiring the permit as acquiring the lock. Although the future never got a chance to log this, it does technically have the permit, and hence the lock as well. The logs were misleading.
With this information, we can see that it's not actually a deadlock at all! It's simply a case of one process not releasing the lock and holding on to it forever.
Practical Fixes
Fix 1: Don’t pause futures that use a tokio mutex; stop them at safe boundaries
If a future might touch tokio::sync::Mutex, don’t pause it at arbitrary points.
Instead:
- Let futures run to completion.
- If it’s a stream, let it run until it yields the next item/result, and only then pause/cancel it.
- Drop the future to cancel it instead of pausing. Of course, this is assuming the future is cancel safe.
In our codebase, it was a stream that was being paused, so we fixed it by polling more (i.e., until it yields an item or ends) before pausing it.
For the reproducer, the PausableFuture is the problem. We should not be keeping a future around without polling it. We need to either always poll it (get rid of PausableFuture) or drop the inner future once it’s paused. Here’s the updated reproducer where the inner future is dropped: fixed reproducer.
Fix 2: Prefer std::sync::Mutex by refactoring critical sections to avoid .await
This is about asking yourself: do you actually need to hold a lock across an .await?
std::sync::Mutex avoids this issue by not having such an intermediate state where a mutex lock is provided, but the thread does not or cannot take it. Either the thread is blocked, or it has the lock. If you can restructure your critical section to avoid await while holding the lock, you sidestep the entire class of problems. This can be done by replacing the tokio mutex with a std::sync::Mutex plus a signaling primitive like tokio::sync::Notify. Notify::notify_waiters wakes up all the waiting futures, instead of just the oldest waiter. This helps prevent one unused permit from blocking others.
Here’s one example: before (with tokio mutex) and after (with std mutex + Notify). This example shows the implementation of a synchronization abstraction called OnceCompute<T> which is like tokio::sync::OnceCell<T> except that it returns an error on cancellation instead of retrying. We use this internally to implement common table expressions (CTEs).
Takeaway
A tokio mutex isn’t a drop-in async version of a std mutex. The waiter queue is part of the correctness story, and it can turn unpolled futures into what looks like a deadlock. If you need tokio::sync::Mutex, use it deliberately: minimize how often you contend on it, and design cancellation/pause so tasks stop at safe boundaries.
When writing a wrapper future or a wrapper stream, always remember the waker contract. When a future registers a waker and that waker fires, the runtime polls the outermost future, which eventually polls the wrapper. If your future swallows the poll without forwarding it, you’ll run into the same class of problems. So, either forward every poll to the inner future, or drop the inner future so it can clean up. There is no safe middle ground.
Listen to the full podcast
Share this article
FAQs
What causes a Tokio Mutex deadlock without holding a lock?
A deadlock can occur when futures using a tokio::sync::Mutex stop being polled due to a custom wrapper (like PausableFuture) even after the mutex is unlocked. The mutex itself isn't held, but the futures are waiting indefinitely to be polled again.
How do Rust futures contribute to the deadlock?
Rust futures are lazy and require polling to make progress. If a future is paused or dropped improperly, it can prevent other tasks from acquiring resources, as the executor never resumes polling that future.
Does this deadlock happen on both single-threaded and multi-threaded Tokio runtimes?
Yes, the issue has been observed on both current_thread (single-threaded) and multi_thread Tokio runtimes when multiple futures contend for the same mutex and some stop being polled.
Why doesn’t the Coffman deadlock analysis predict this issue?
Traditional Coffman conditions assume resource holding. In this Tokio scenario, no thread holds the mutex when the deadlock occurs. Futures stop polling, which isn’t captured by standard deadlock analysis, making the deadlock unintuitive.
What is the difference between std mutex and tokio mutex?
std::sync::Mutex is blocking and should not be held across .await points. tokio::sync::Mutex is async-aware, yielding control when contended, allowing it to be held across .await safely, and is used in asynchronous Rust code.
How can Rust futures cancellation affect mutex behavior?
Dropping a future cancels it immediately. If a future holding a mutex lock is dropped, the mutex gets unlocked. This can lead to the data being left in an inconsistent state.
What practical steps can avoid this type of deadlock?
Avoid pausing or dropping futures that are waiting on a mutex. Ensure all futures continue polling, or redesign async flows so that futures do not depend on others resuming for progress.
Why do some workers deadlock while others complete successfully?
Workers that keep polling the mutex progress normally, while those paused by PausableFuture stop being polled. This selective pause causes some workers to hang indefinitely despite the mutex being free.
Why use tokio Mutex instead of std Mutex?
Tokio mutex is async-aware, allowing tasks to yield instead of blocking threads when contended. It can safely be held across .await points, unlike std mutex, which blocks the OS thread.
How can one debug such deadlocks in Tokio?
Debugging requires understanding futures polling, mutex internals, and executor behavior. Logging alone may not reveal paused tasks. Observing which futures are polled and which remain pending is key.
.svg)
.svg)
.svg)
.svg)
Available at
.png)

.svg)