.svg)
A real-time analytics engine processes and analyzes continuously updating data with minimal latency, enabling organizations to monitor events, power live dashboards, and react to changes instantly.
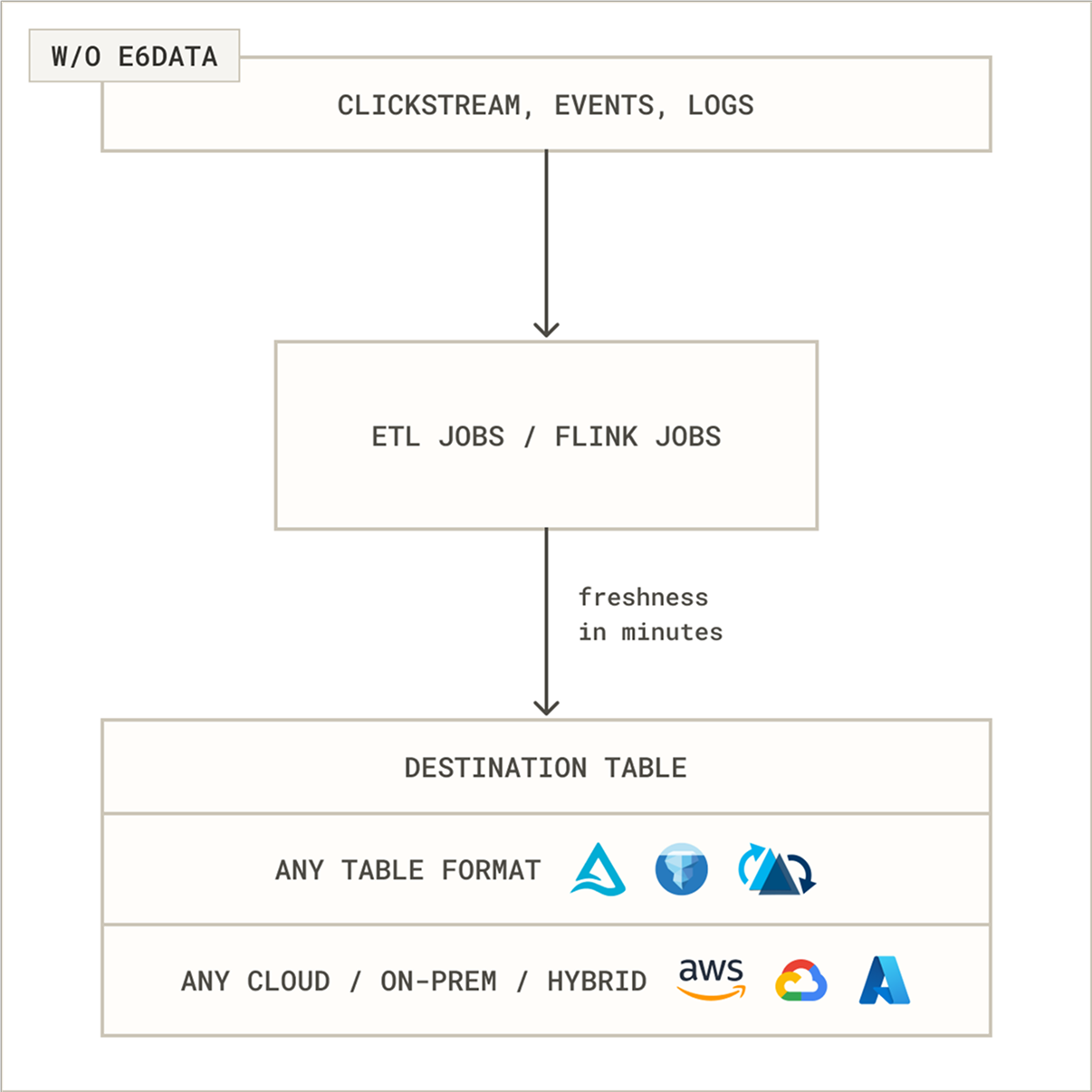
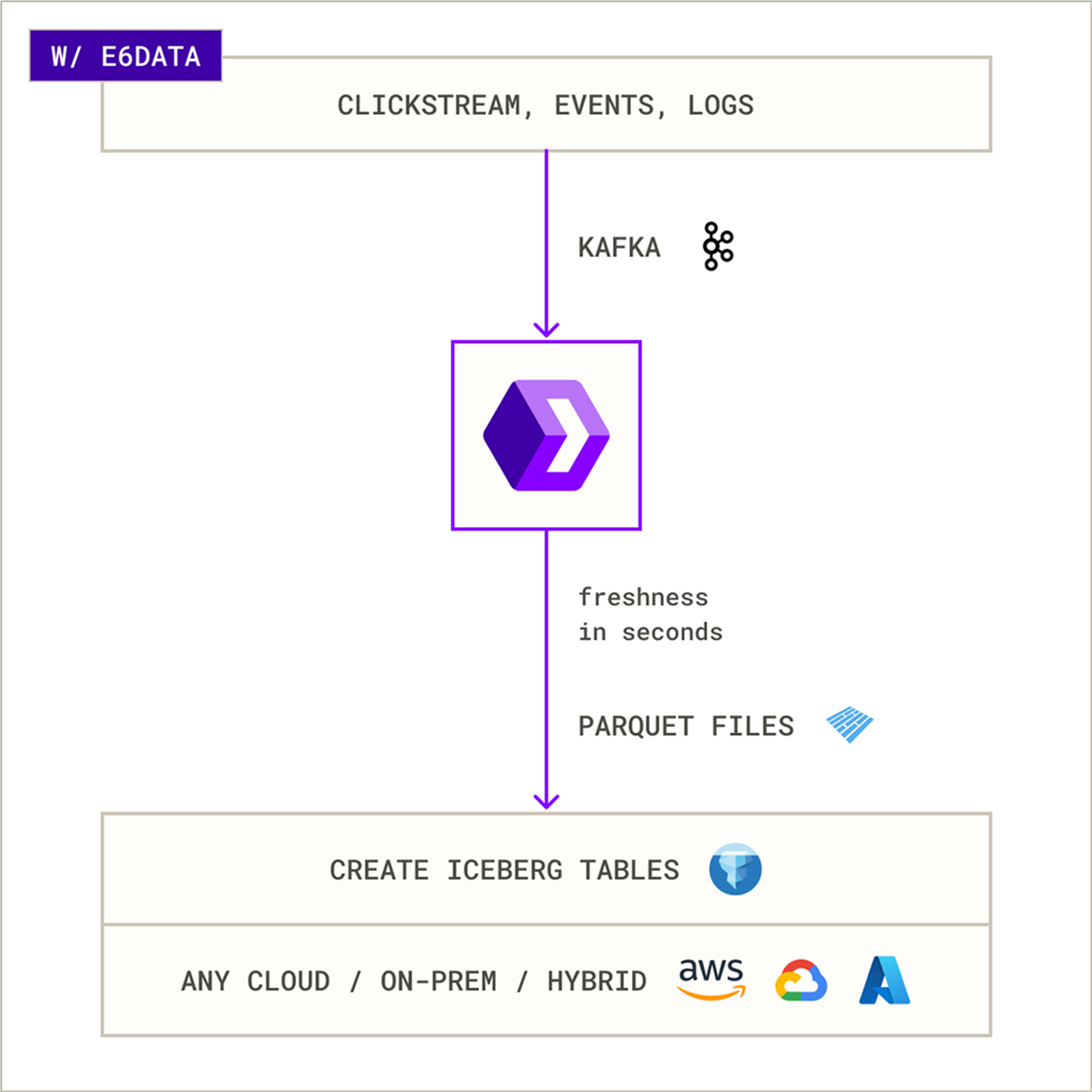
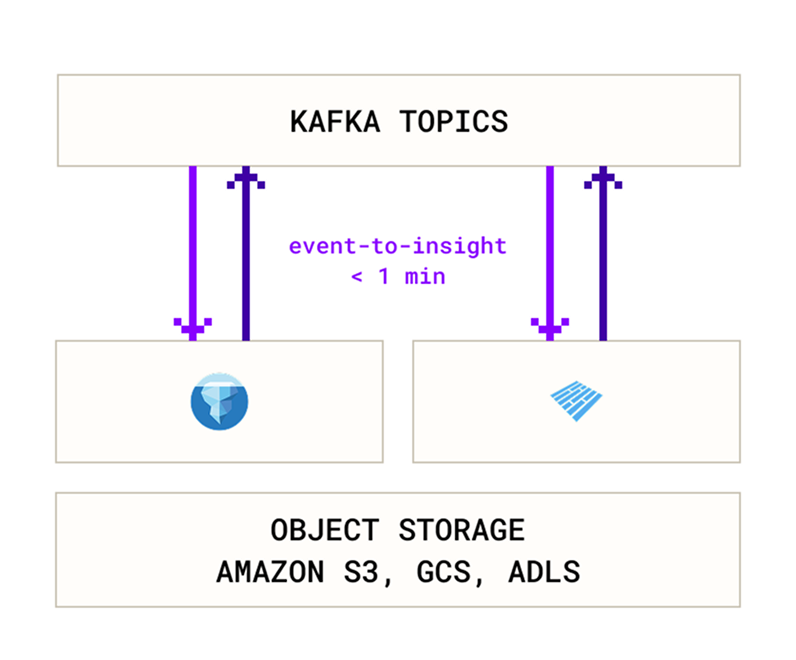
Unlike traditional batch systems, modern architectures combine scalable compute with a real-time data lake to deliver real-time lakehouse analytics directly on open data storage.
This approach enables teams to run low-latency queries on streaming and historical data from a single platform without building separate real-time pipelines.






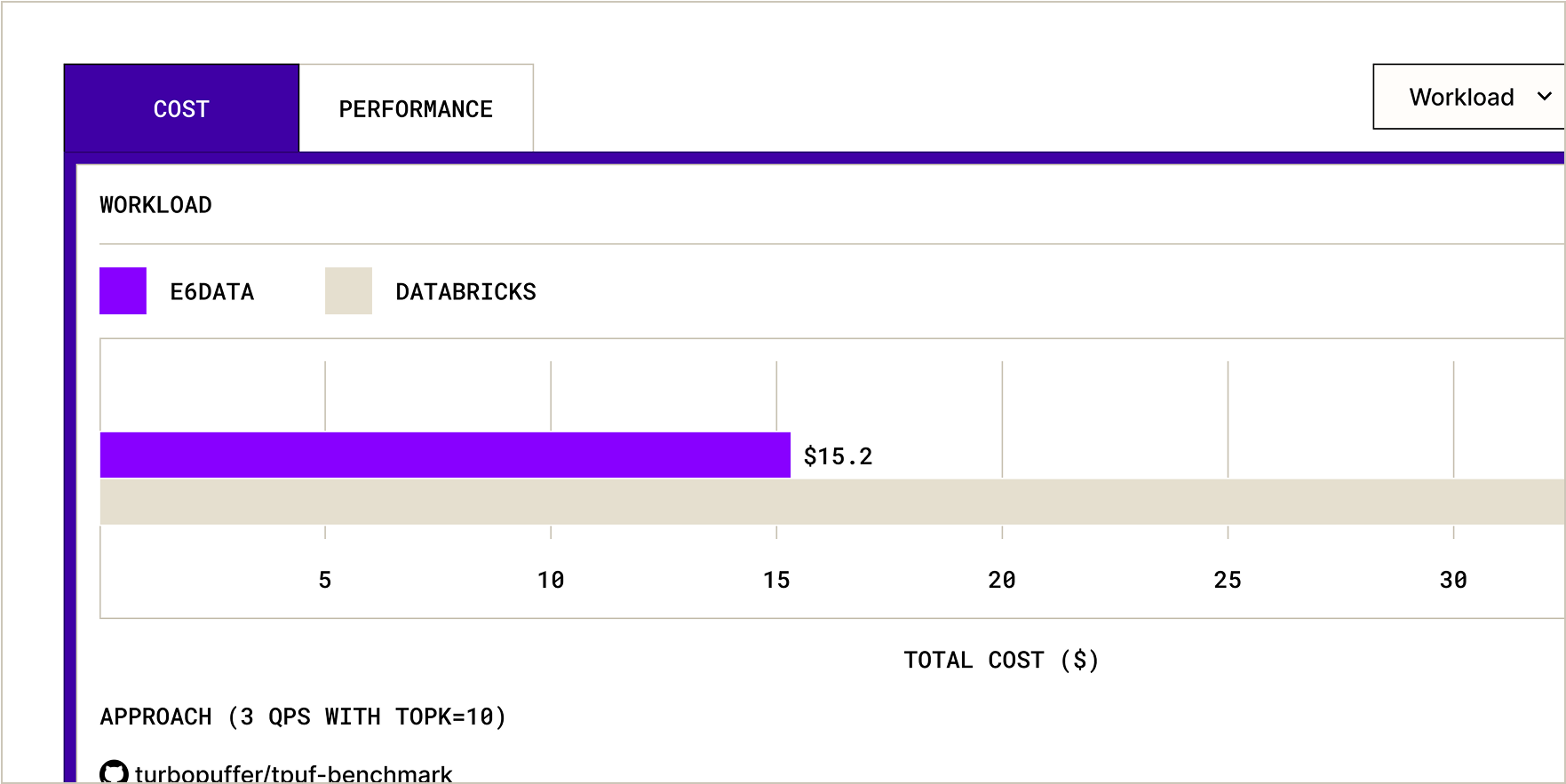
“We achieved 1,000 QPS concurrencies with p95 SLAs of < 2s onnear real-time data & complex queries. Other industry leaders couldn’t meet this even at a far higher TCO.”
Chief Operating Officer
faster speed
lower costs
queries/sec
.svg)
.svg)
.svg)
.png)

.svg)
.svg)