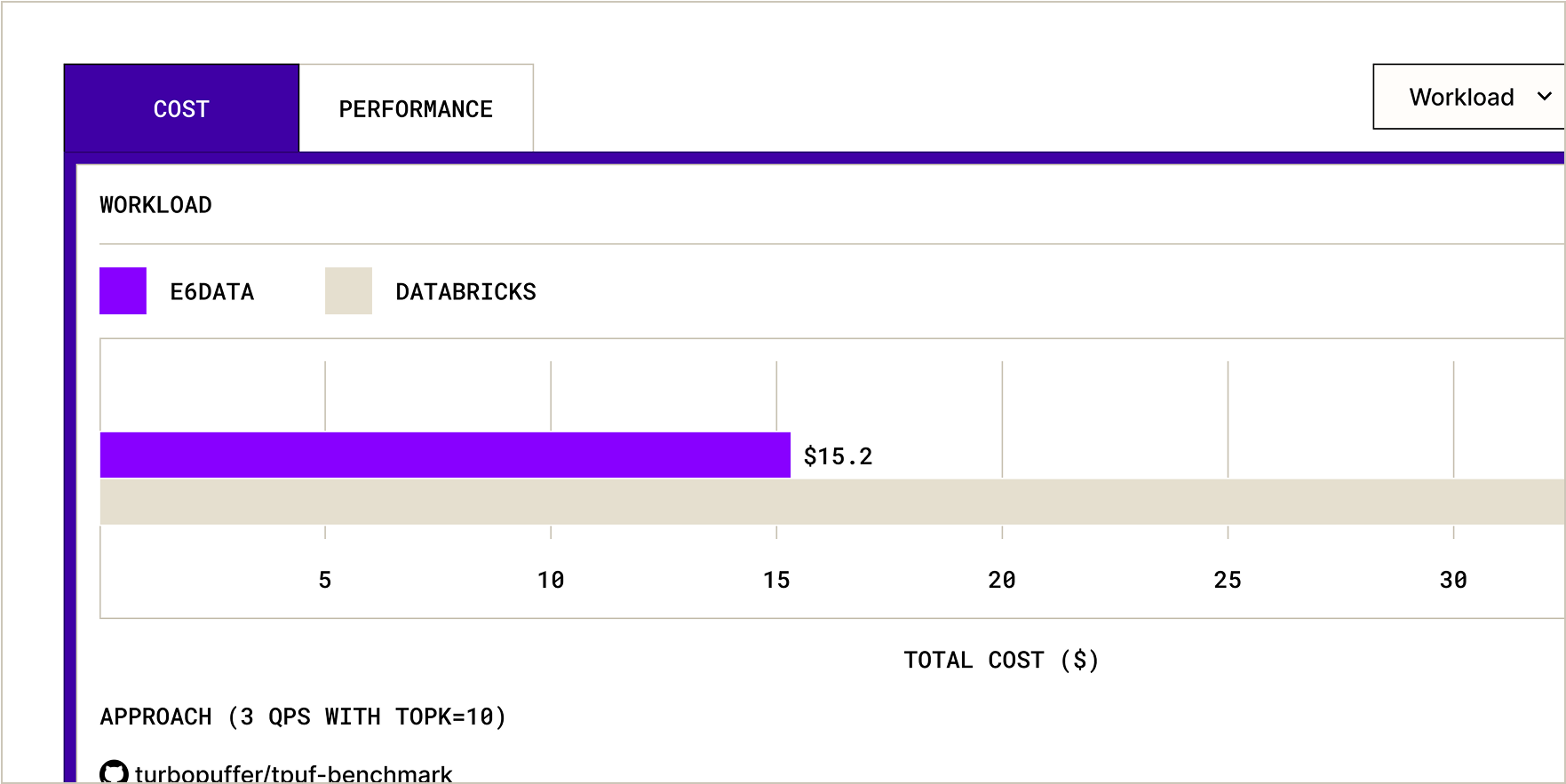
.svg)
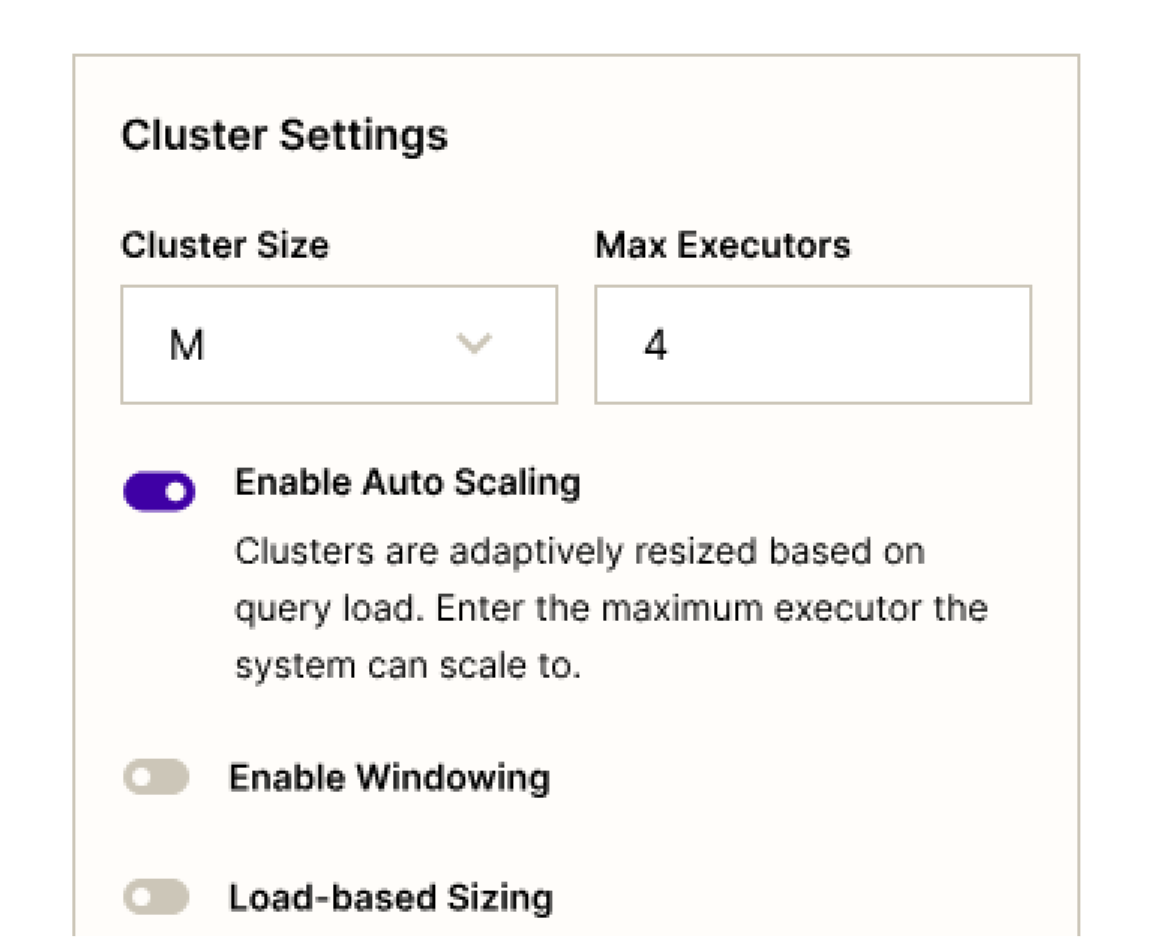
.png)
.png)
Enables fast query responses for interactive dashboards and ad-hoc analysis, even under sustained load.

Supports hundreds to thousands of simultaneous users without query queuing or performance degradation.

Handles large scans, joins, and aggregations across lakehouse storage while maintaining consistent performance.

Query structured and unstructured data with cosine similarity. No vector DBs. Just pure vector search.
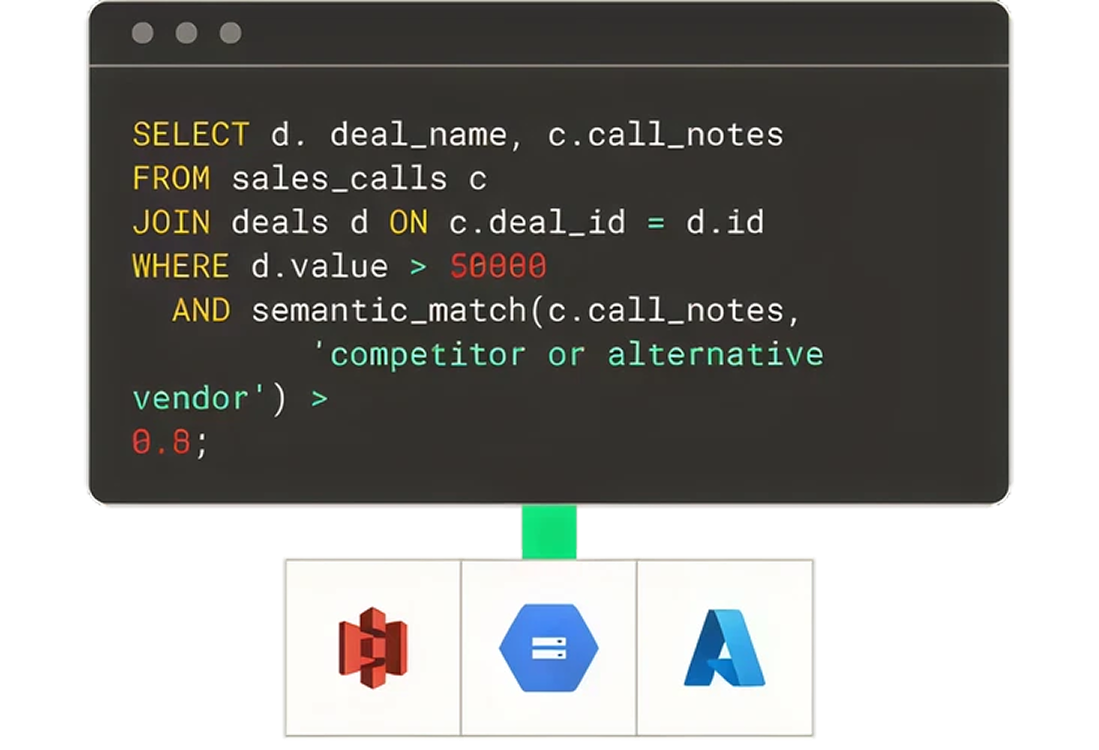
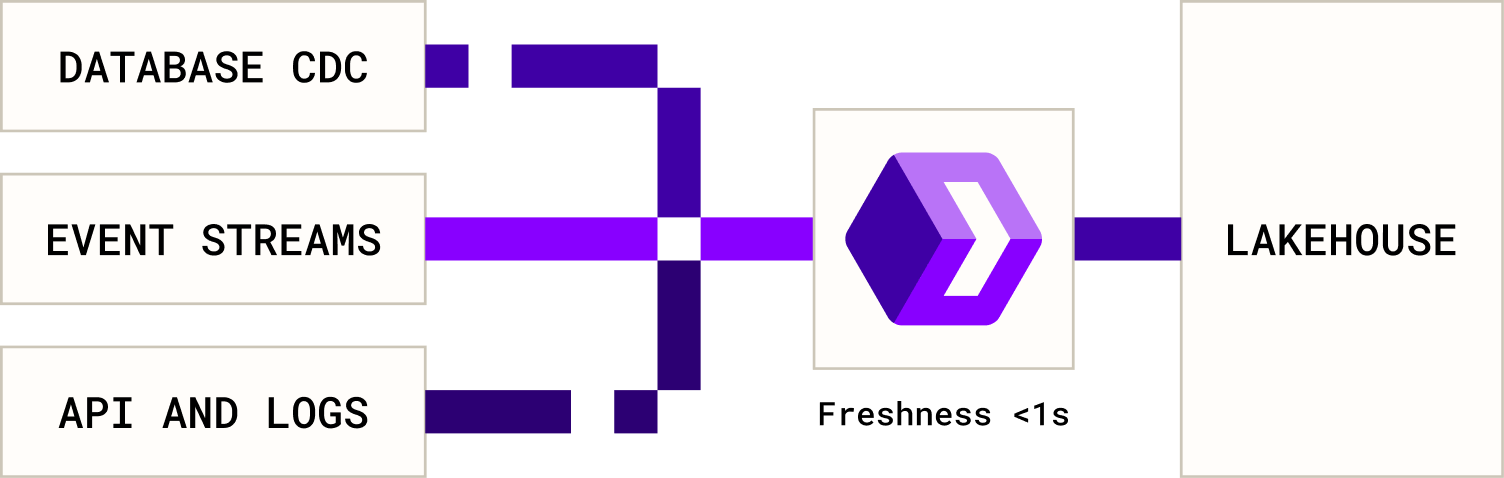
Stream directly to your lakehouse, query with sub-second latency- query with SQL/Python. No Flink, no ETL, no learning curve.
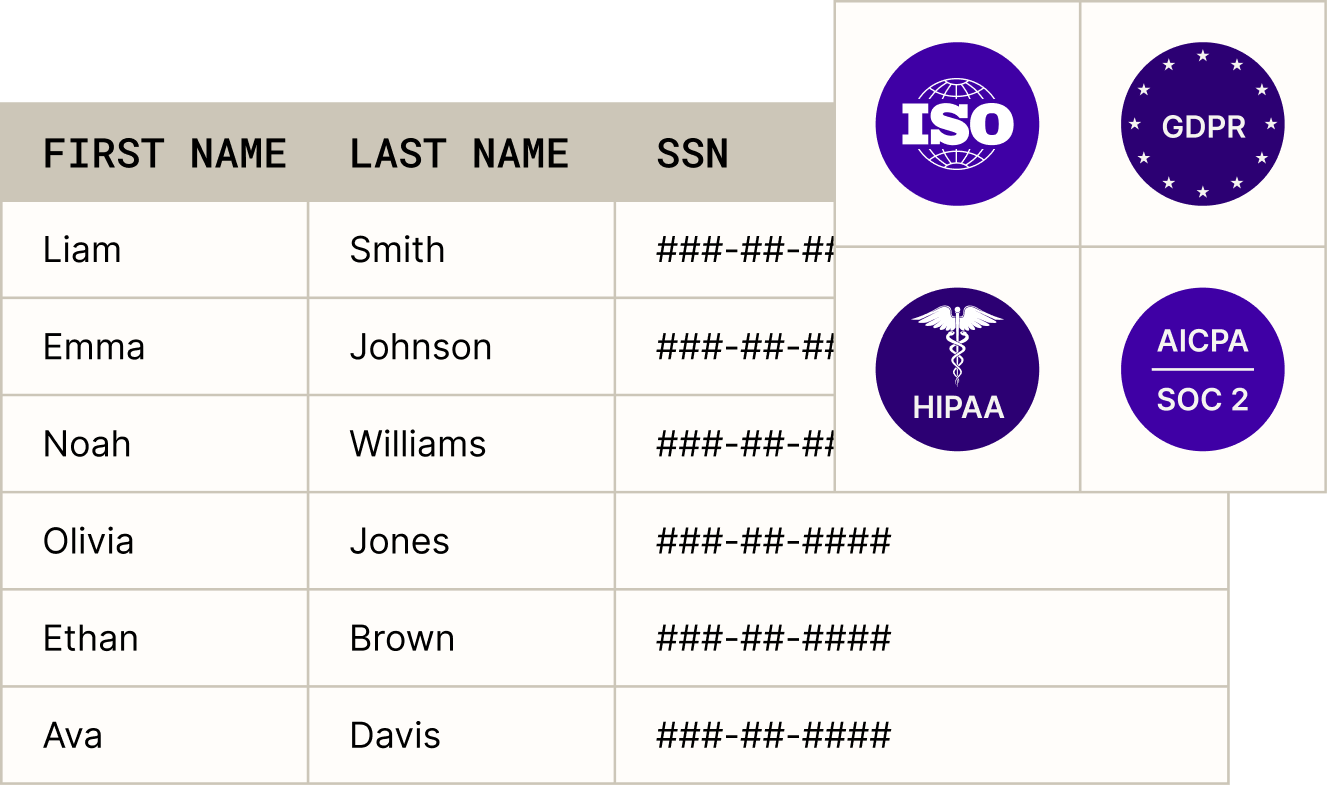
Row/column-level control, IAM integration, and audit-ready logs. SOC 2, ISO, HIPAA, and GDPR—secure by design, with no slowdown.
.svg)
.svg)
.svg)
.png)

.svg)
.svg)
.svg)