.svg)
Product
e6data’s Hybrid Data Lakehouse: 10x Faster Queries, Near-Zero Egress, Sub-Second Latency

%20(1).svg)
Today,
- 92% of enterprises already run multi‑cloud
- 80% worry about over‑relying on one cloud
- BFSI firms face region‑locked data rules, while needing global insight
But, most of these enterprises still end up copying data between regions and providers incurring hefty egress charges, and juggling inconsistent security controls in each environment leading to policy drift and compliance nightmares.
The hard truth is that most cloud data warehouses and lakehouses weren’t designed for hybrid agility, often being single cloud-dependent and lacking interoperability across regions, new formats like Iceberg, and more. The result: lock‑in, surprise costs, governance gaps, and poor performance at peak load for enterprises, especially in highly regulated industries like BFSI and healthcare.
TLDR; We ventured to solve this, and came up with our hybrid data lakehouse which queries 10x faster, with ~0% egress fee. Details below.
What We Did Differently: Federated SQL Engine with Hybrid Cluster Architecture
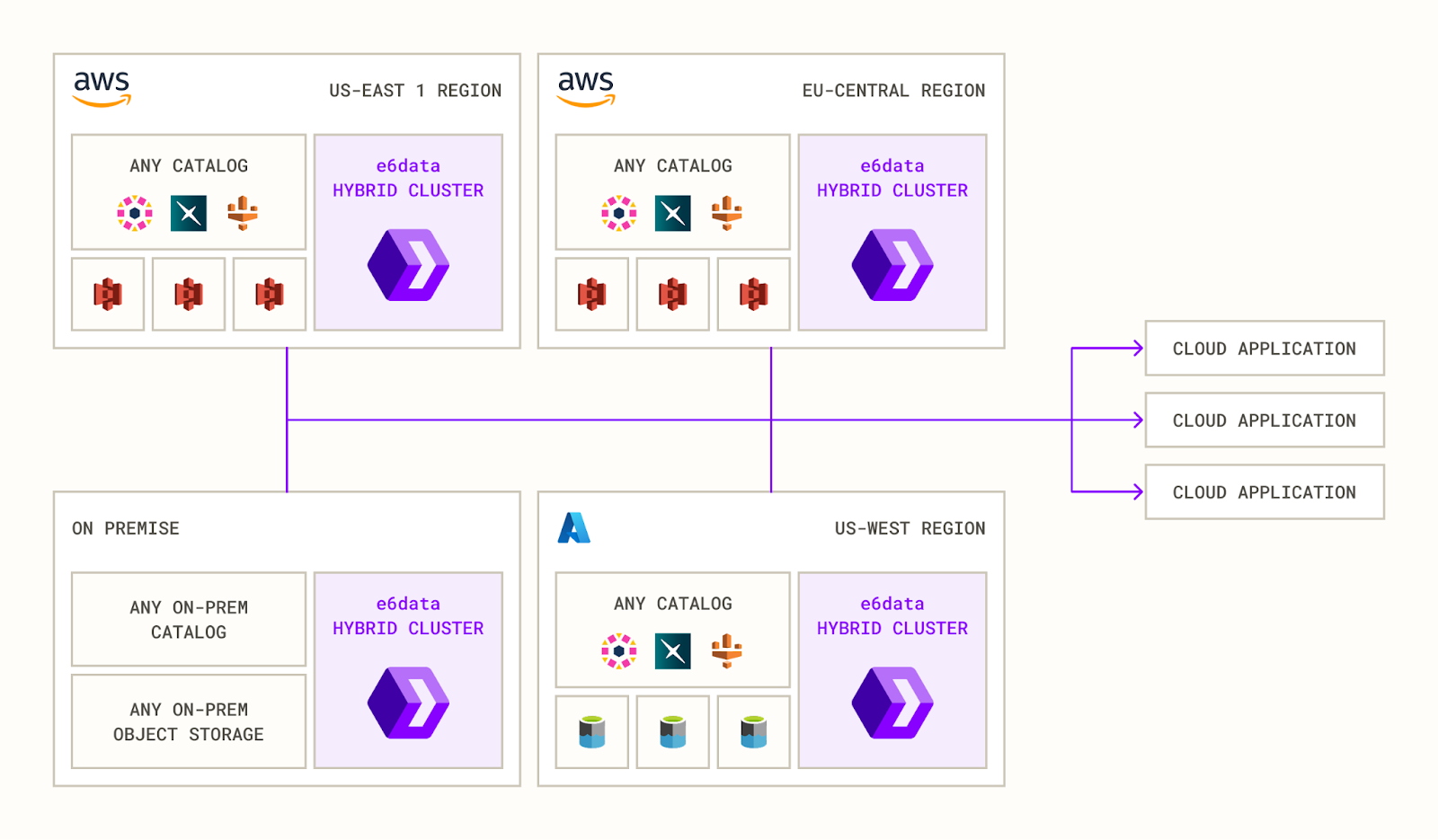
The architecture is designed such that the hybrid cluster is abstracted out from the end user's querying experience, and they get to write queries as though there were a single cluster talking to all these data sources. Here’s a brief breakdown on how it works:
- Federated SQL engine: Unifies queries across different clouds, regions, and on-prem silos without forcing data migration.
- Hybrid cluster layout: One “main” entry-point cluster receives the query. Many “ancillary” clusters sit next to each data domain.
- Smart task routing: The main cluster pushes each compute task to the ancillary cluster closest to the requested data, minimising egress and latency.
- Secure peer-to-peer gateway: Encrypts traffic between clusters and keeps every data hand-off compliant with enterprise policies.
- Governance built in: Central IAM and policy definitions propagate automatically to every cluster.
Benchmarks: 10x Faster Speed, ~0% Egress Fee, and Another ~40% Off Latency With Caching
Our engineering team went out to battle test this several times around on production data. One of the experiments relied on a TPCDS 1TB synthetic dataset, split across two: 720 M rows in AWS, 2.75 B rows on-prem with configurations as below:
- Environment
- On-prem environment is simulated using e6data’s GCP cloud account
- Cloud environment is simulated using e6data’s AWS cloud account
- Catalogs
- Hive Catalog on-premises
- Unity Catalog on cloud
- Clusters (all executors are standard e6data executors (30 cores))
- “on-prem-only” - 2 executors, 1 planner, workspace components all running on-premises
- “hybrid” - 1 executor in on-premises, 1 executor in cloud, planner and all workspace components in on-premises
- “hybrid-caching” - same as (b) , but has data caching enabled
- Queries
- Q1: Full table scan + filter, unions cloud and on-prem sales.
- Q2: Scan + filter + aggregate, same union.
Results: 0.097% latency, 0.01% egress costs (with no caching)
- 10x speed by keeping compute local.
- ~100x less data shuffled; egress fees practically disappear.
- Adding cache reduces another ~40% off latency with no extra data movement.
What it Enables: Complex, High-speed Analytics with Zero Egress Fee, and One Policy Governance
e6data's hybrid data lakehouse is supported on all major cloud providers, integrating with most popular metastores and object storage. It is used in production across customers, with one of the major US global bank saving 95% egress costs on it. Here are the list of features we support:
- No egress fee – every task runs on compute co‑located with the source, therefore eliminating the need to move data anywhere.
- One policy everywhere – Regulators expect identical ACLs in every zone; copy-pasting rules don't scale. e6data’s hybrid data lakehouse shares one catalog and IAM hook. If you set a rule once, it applies across the cluster.
- Affinity‑aware scheduler – bind workers and tasks to resources closest to your data, so only the tiny result set crosses the wire, maintaining latency and performance SLAs .
- Speaks open formats – compatible with all formats, like Parquet, Iceberg, Delta with no lock-in, and migrations.
- Single logical cluster – one control plane, yet nodes live across all clouds (AWS, Azure, GCP), regions, and on‑prem.
What’s Next: Agent-facing Analytics on Hybrid Data Lakehouses
The future of analytics belongs to AI data analysts that never log off. They hammer databases with multiple queries, demanding sub-second answers around the clock. In cloud-only setups, this creates runaway spend. A hybrid lakehouse flips the economics. Each agent prompt is handled on the node sitting beside the data, so no cross-region transfers, no egress bills, and governance rules stay intact. As agent-driven analytics becomes a standard practice, a hybrid lakehouse is the only architecture that can keep up with both the speed and the costs of analytics.
Check out our documentation to dive deeper and see how e6data’s hybrid data lakehouse can fit into your architecture.

.png)
.jpg)
Frequently asked questions (FAQs)
How do I integrate e6data with my existing data infrastructure?
We are universally interoperable and open-source friendly. We can integrate across any object store, table format, data catalog, governance tools, BI tools, and other data applications.
How does billing work?
We use a usage-based pricing model based on vCPU consumption. Your billing is determined by the number of vCPUs used, ensuring you only pay for the compute power you actually consume.
What kind of file formats does e6data support?
We support all types of file formats, like Parquet, ORC, JSON, CSV, AVRO, and others.
What kind of performance improvements can I expect with e6data?
e6data promises a 5 to 10 times faster querying speed across any concurrency at over 50% lower total cost of ownership across the workloads as compared to any compute engine in the market.
What kinds of deployment models are available at e6data ?
We support serverless and in-VPC deployment models.
How does e6data handle data governance rules?
We can integrate with your existing governance tool, and also have an in-house offering for data governance, access control, and security.
.svg)
.svg)
.svg)
Available at
.png)

.svg)
.svg)
.svg)
.svg)
.svg)
.svg)
.svg)