.svg)
.svg)
.svg)
Subscribe to our newsletter - Data Engineering ACID
Share this article
.svg)
.svg)
Data Warehouse Cost Optimization: A Complete Guide for Engineering and FinOps Teams
April 21, 2026
/
General
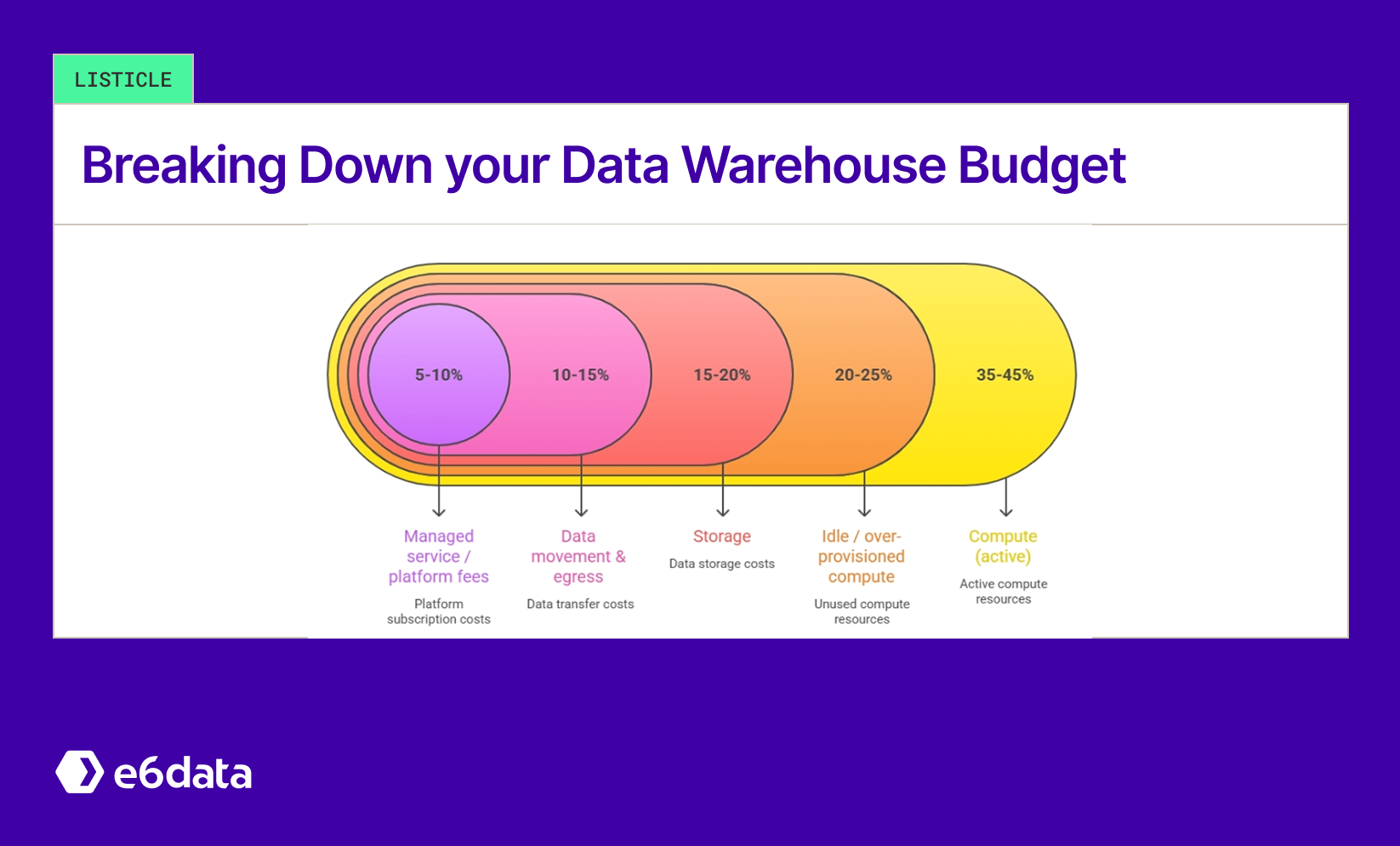
Introduction
If you run analytics on a cloud data warehouse today, you almost certainly have a cost problem. The pricing architecture of traditional data warehouses was designed for a different era, before petabyte-scale lakehouses, before 1,000-QPS concurrency, and before FinOps teams started holding engineering accountable for every dollar of compute spend. The result: bills that grow faster than business value, clusters left running overnight, and budgets that cannot survive a single complex ad-hoc analysis. Industry estimates suggest enterprises waste 30% to 50% of cloud data warehouse spend on idle compute, over-provisioned clusters, and avoidable data movement.
This guide gives you a framework for understanding where your money is actually going, which levers produce the biggest savings, and how modern architectures like e6data's Atomic Architecture eliminate the structural inefficiencies that query tuning alone cannot fix. Whether you run Snowflake, BigQuery, Redshift, Azure Synapse, or a hybrid lakehouse, these strategies apply.
TL;DR
- Data warehouse costs are driven by compute, storage, data movement, query inefficiency, and idle resources.
- The five major pricing models (consumption-based, reserved capacity, cluster-based, serverless, and per-vCPU) behave very differently under real workloads, and misaligning models to workload is one of the most common and expensive mistakes.
- Optimizing costs requires an eight-step process. They are: audit your baseline, identify drivers, right-size compute, optimize queries, manage storage, align pricing models, introduce governance, and evaluate architecture.
- The most overlooked cost driver is structural with traditional engines scale at the node level, which forces over-provisioning by design. Atomic scaling at the vCPU level removes this structural waste.
- e6data's Atomic Architecture delivers up to 60% lower compute costs and 10x faster query performance by scaling independently at the vCPU level, charging only for vCPU seconds consumed, and querying data in place with zero data movement.
- Tools that enforce per-cluster query thresholds, real-time cost alerts, and usage-based billing give engineering and FinOps teams the visibility and control they need to make optimization a continuous practice.
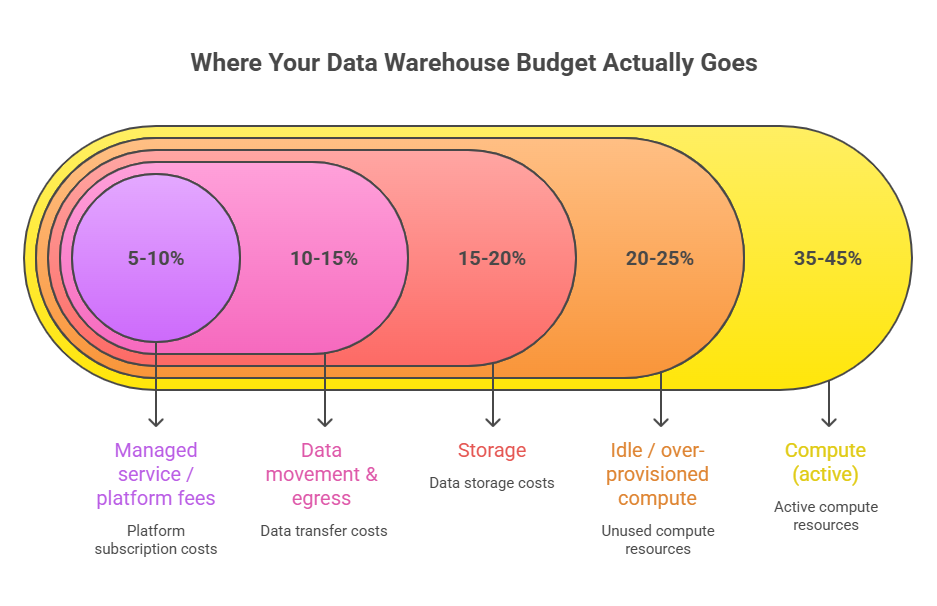
What Is Data Warehouse Cost Optimization?
Data warehouse cost optimization is the practice of systematically reducing the total cost of operating a cloud data warehouse while preserving or improving query performance, reliability, and analytics quality. It spans compute management, storage efficiency, query engineering, pricing model selection, governance, and architectural decisions. The core goal is eliminating waste. Compute running when nothing is executing, storage holding data no one queries, queries scanning far more data than necessary, and pricing models charging for capacity that sits idle 60% of the time.
Aggressive cost-cutting without a structured framework often trades savings for performance regressions or engineering debt that costs more to unwind than the savings were worth. True optimization finds and removes structural inefficiency while keeping the analytics experience intact. For most organizations, this touches three layers: the architectural layer (how compute and storage are structured), the operational layer (how resources are provisioned and governed), and the engineering layer (how queries are written and executed). Sustainable savings require improvements at all three.
Why Data Warehouse Costs Are Spiraling Out of Control
Compute: The Biggest and Most Volatile Cost Driver
Compute is almost always the dominant line item. Most traditional engines scale at the node or cluster level. When you provision for peak demand, you pay for the full cluster even when utilization is 15%. Teams running a mix of dashboards, batch jobs, and ad-hoc queries see enormous demand swings throughout the day, but coarse-grained node scaling means you pay for the valley as if it were the peak, all day, every day. Add overnight clusters, oversized dev environments, and the habit of provisioning "just to be safe," and compute waste becomes the single largest opportunity in any optimization initiative.
Storage Costs That Silently Compound
Cloud storage is cheap per terabyte, but costs compound silently. Raw data grows. Transformed datasets duplicate raw data. ETL pipelines create intermediate copies. Snapshots accumulate. Without active retention policies, none of it gets cleaned up. For many organizations, storage is 20-30% of total warehouse spend, and a meaningful share is data that hasn't been queried in months.
Data Movement and Egress Fees
Egress fees, cross-region transfers, and the cost of copying data between systems can represent 10-20% of total spend in multi-cloud or hybrid architectures. The traditional ETL approach, extract from the lakehouse, load into the warehouse, transform there, creates data movement costs that accumulate with every refresh cycle. Many of these costs could be entirely eliminated with a query-in-place architecture.
Idle Resources and Structural Over-Provisioning
Idle resources are the most invisible cost driver. A cluster left overnight doesn't feel expensive at the moment. Multiply that across teams, environments, and weeks, and it dominates the bill. Structural over-provisioning is different. It's the gap between what you provision and what you actually need. Because traditional engines scale in node increments, a query needing 2 nodes of compute will consume 4, 8, or 16 because those are the available sizes. The waste is architectural.
Query Inefficiency at Scale
Full-table scans, missing partition filters, repeated expensive computations, and uncached results force the compute engine to do far more work than necessary. In consumption-based pricing, this translates directly into extra spend on every execution. A query scanning 10 TB when it should scan 100 GB is a 100x cost multiplier. Multiplied again by hundreds of daily executions across dozens of analysts and pipelines.
Understanding Data Warehouse Pricing Models
Consumption-Based Pricing
Charges only for measurable usage. Spend scales with activity, when queries stop, spending stops. The risk: without guardrails, inefficient queries or unexpected spikes produce surprising bills. Governance and query review are essential companions.
Best fit: Variable workloads, ad-hoc analytics, experimentation environments.
Reserved Capacity Pricing
Commit to fixed compute for a defined period in exchange for lower unit costs and predictable billing. The risk: underutilized reserved capacity becomes pure waste if workload patterns shift after commitment.
Best fit: Stable production analytics, enterprises prioritizing budget certainty.
Cluster-Based Pricing
Bills for provisioned compute regardless of utilization. Offers performance consistency and full infrastructure control, but structural over-provisioning is most visible here. A cluster sized for peak demand runs at partial utilization during off-peak hours. You pay for the full thing producing nothing.
Best fit: Always-on workloads with genuinely high and consistent utilization.
Serverless Pricing
Removes infrastructure management entirely. Compute appear on demand and disappear when idle. Minimizes operational overhead, but poorly governed query workloads drive spend upward quickly. The governance requirement is identical to consumption-based pricing.
Best fit: Elastic or spiky workloads, teams prioritizing operational simplicity.
Per-vCPU Usage-Based Pricing
The most granular billing model. Charges only for vCPU seconds consumed per query. If a query needs 3.7 vCPUs for 4 seconds, that's exactly what you pay for enabled by Atomic Architecture, which e6data pioneered. You never pay for compute headroom that exists only to absorb potential peaks.
Best fit: Mixed workloads at any concurrency level, teams that have exhausted cluster tuning as an optimization lever.
Choosing the Right Model for Your Workload
Sophisticated teams run multiple simultaneously: reserved capacity for high-utilization batch pipelines, consumption-based or serverless for ad-hoc analytics, per-vCPU for interactive dashboards and high-concurrency SQL. The key is intentional alignment between workload pattern and pricing model.
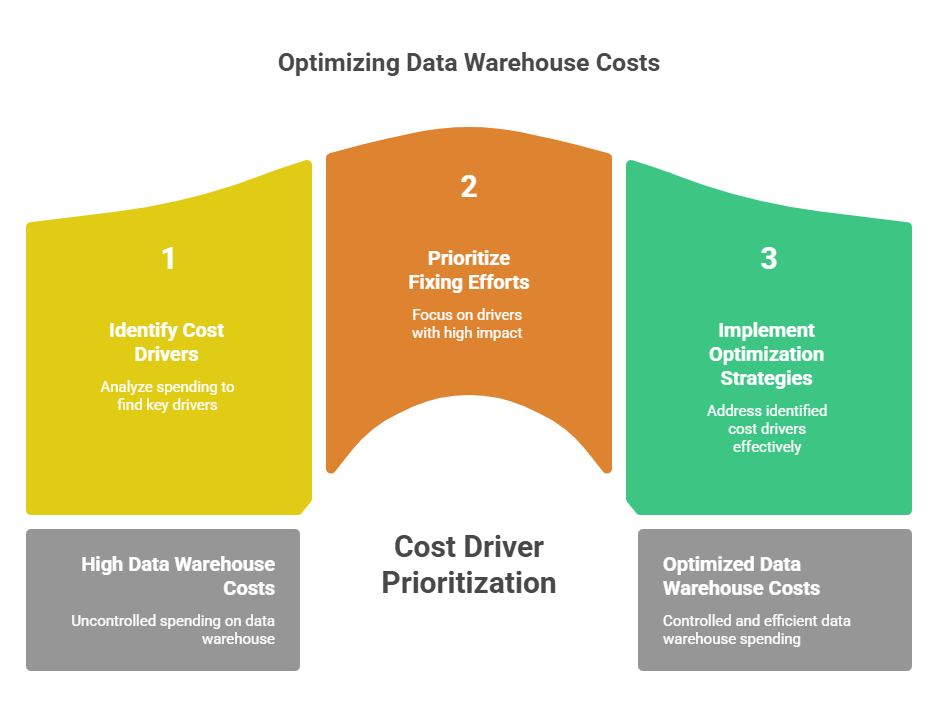
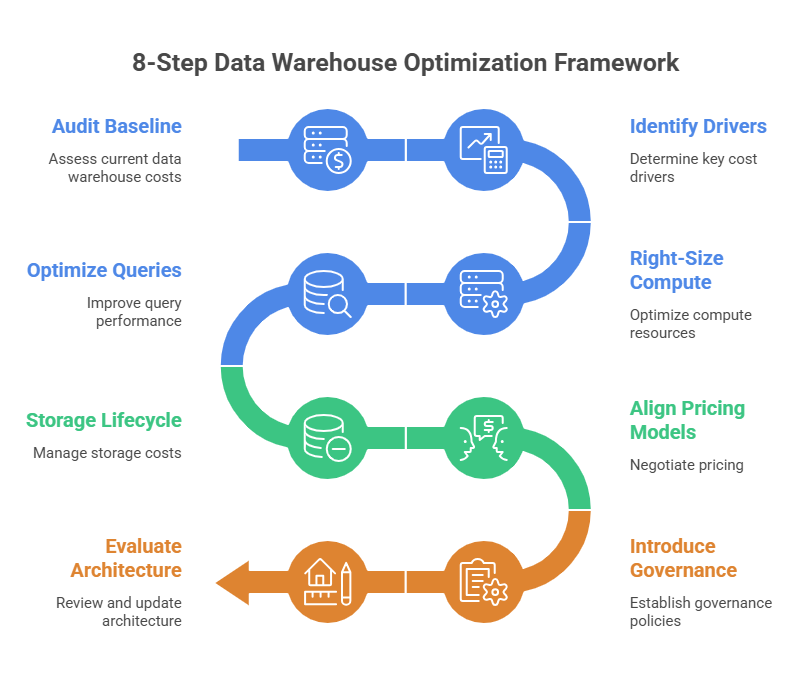
How to Optimize Your Data Warehouse Costs: Step-by-Step
Step 1: Audit Your Current Spending Baseline
Pull billing data covering at least the last three months. Segment spend into compute, storage, networking and egress, and managed service fees. Identify the top contributors in each category. This baseline is your benchmark, every savings claim should be traceable back to a specific line item here.
Step 2: Identify Your Biggest Cost Drivers
Diagnose root causes. For compute, pull utilization metrics and compare peak to average. A cluster peaking at 80% but averaging 20% is a candidate for auto-suspend or workload migration. For queries, sort by cumulative cost impact, a $0.50 query running 500 times daily matters more than a $10 query running monthly. For storage, flag data not queried in 90-plus days. For egress, map every cross-region or cross-cloud data flow.
Step 3: Right-Size Your Compute Resources
Most organizations provision for peak and leave it there indefinitely. If a cluster regularly operates below 40% utilization, it's over-provisioned. Reduce cluster size incrementally, a 25% reduction on a workload with 35% average utilization typically has no performance impact. Implement auto-suspend policies: 5-10 minutes for non-production environments, 10-15 minutes for production. This alone reduces idle compute costs by 30-50%.
Step 4: Optimize Query Performance
Reduce the data each query must read. Add partition filters and WHERE clauses to eliminate full-table scans. Replace SELECT * with only the columns needed. Introduce materialized views for queries recalculating the same expensive result repeatedly. Reorder joins to filter early and start with the most selective predicates. Establish a query review process before new analytical workflows reach production.
Step 5: Implement Storage Lifecycle Management
Classify data into hot, warm, and cold tiers based on query frequency. Implement automated lifecycle policies in your object store to transition data to lower-cost tiers after defined periods of inactivity. Review pipeline architecture for unnecessary duplication, ETL pipelines creating raw, cleaned, transformed, and reporting layers often retain intermediate copies far longer than necessary.
Step 6: Align Workloads with the Right Pricing Model
Don't force all workloads into a single model. Production batch pipelines with predictable compute requirements belong in reserved capacity. Interactive dashboards and ad-hoc queries belong in consumption-based, serverless, or per-vCPU models. Development environments should never run on production-scale infrastructure with production pricing. Treat workload-to-pricing-model alignment as an ongoing practice.
Step 7: Introduce Governance and Cost Controls
Cost optimization doesn't scale without governance. The foundation is attribution. The ability to see which team, project, or pipeline is consuming what. Without it, no one feels responsible for the costs they generate. Set budget alerts that notify owners before spend exceeds targets. Enforce query policies at the platform level, specifically per-cluster thresholds that cancel runaway queries before they complete. Real-time cancellation is materially more powerful than after-the-fact billing review.
Step 8: Evaluate Architectural Alternatives
If you've worked through the previous seven steps and costs still grow faster than data and query volumes, the problem is architectural. Alternatives worth evaluating include decoupled storage and compute architectures, query-in-place engines that read data directly from your object store, and Atomic Architecture engines that scale at the vCPU level and bill per vCPU second. Modern engines are designed for zero-migration adoption. They read your existing data in place, support existing table formats, require no query rewrites, and deploy alongside your existing warehouse.
Best Data Warehouse Cost Optimization Strategies That Actually Move the Bill
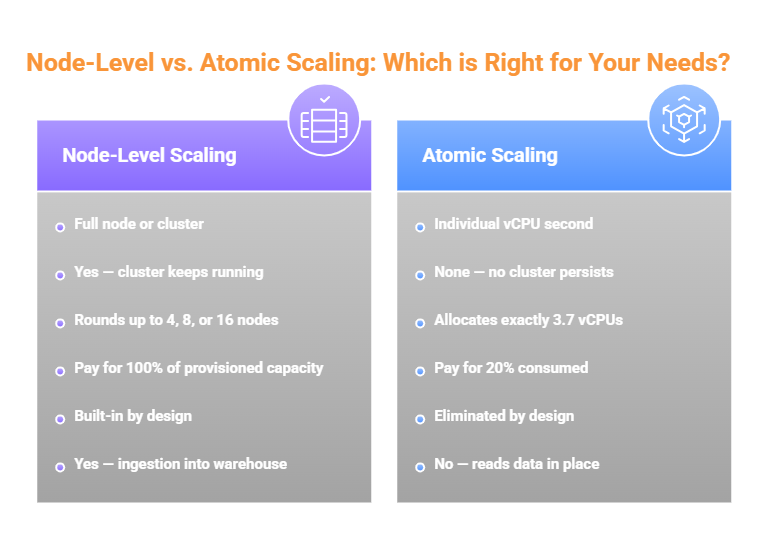
Atomic Scaling vs. Node-Level Scaling
In node-level scaling, every query consumes a full node's resources regardless of actual need. At low concurrency, most of that node sits idle. At high concurrency, the system adds nodes in large increments even when additional demand could be served with a fraction of one. Atomic scaling eliminates this. A query needing 3.7 vCPUs consumes exactly 3.7 vCPUs. A burst needing 47 vCPUs consumes exactly 47. For teams that have already optimized cluster sizing and query performance, the gap between node-level and atomic scaling is the remaining structural waste that tuning simply cannot address.
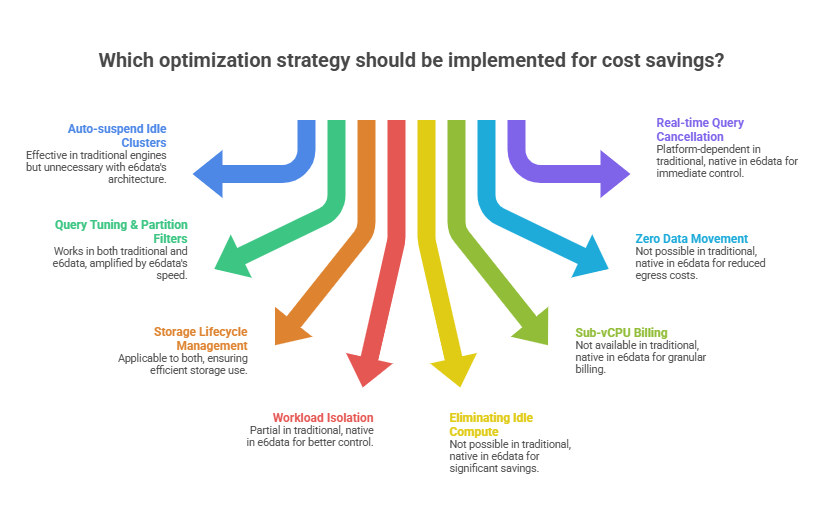
Eliminating Idle Compute Structurally
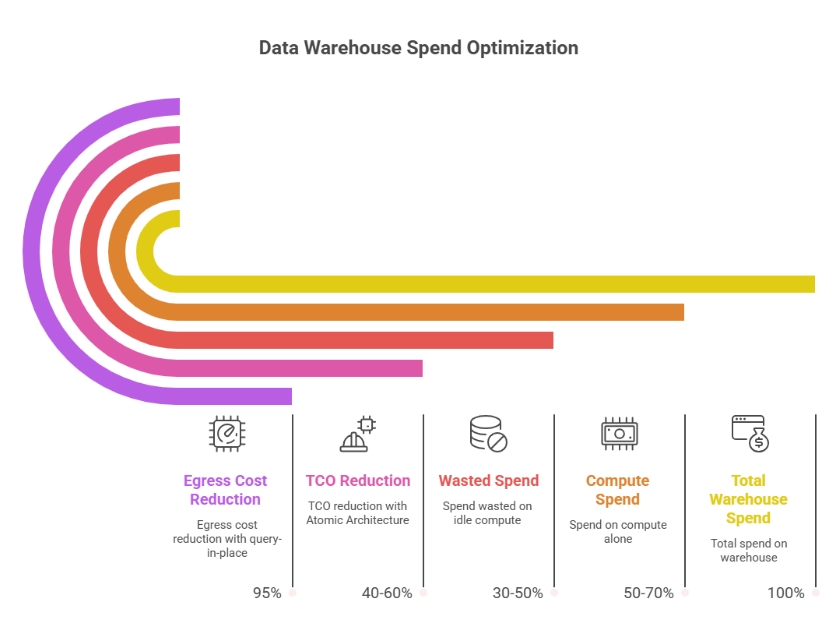
Auto-suspend policies and scheduled scaling address idle compute tactically. The structural solution is to adopt a pricing model where compute doesn't exist between queries. In a true per-vCPU model with Atomic scaling, compute materializes for the duration of a query and releases immediately after. The concept of idle compute disappears from the cost model entirely. This is a primary mechanism behind e6data's 60% lower TCO.
Reducing Data Movement and Egress Costs
In complex ETL pipelines, intermediate data can be moved multiple times before producing a final result. The most effective fix is query-in-place architecture: move compute to where data lives. A lakehouse compute engine reading directly from your object store eliminates loading costs entirely. A location-aware scheduler routing compute to the cluster nearest each data domain eliminates cross-region egress. One major US global bank using e6data's hybrid architecture achieved a 95% reduction in egress costs through this approach.
Decoupling Compute from Storage
Traditional warehouses couple compute and store tightly, scaling one forces scaling the other. When data volumes grow but query volumes stay flat, you pay for compute you don't need. Decoupled architectures bill storage at object store rates and compute only during active query execution. Your data lives in open formats on your own object store and can be queried by any compatible compute engine, eliminating vendor lock-in.
Workload Isolation
Shared compute infrastructure for mixed workloads forces provisioning for the maximum of all combined needs. An expensive batch job competing with a latency-sensitive dashboard degrades both. Routing workload types to dedicated compute lets each be provisioned and priced for its actual requirements, batch on lower-cost reserved capacity, dashboards on elastic low-latency compute, ad-hoc analytics on consumption-based infrastructure that scales to zero between sessions.
Query-Level Cost Guardrails in Real Time
Real control requires intercepting queries that exceed defined thresholds before they complete. Per-cluster thresholds automatically log, alert on, or cancel queries in real time. A query trending toward scanning 5 TB when the cluster threshold is 500 GB gets cancelled before it finishes, protecting the budget and surfacing the query for optimization review without requiring manual oversight at scale.
Data Warehouse Optimization Comparison: Legacy vs. Modern Architecture
Common Mistakes in Managing Costs in Data Warehouses
- Treating optimization as a one-time project - Costs that are under control this quarter can spiral quickly when a new team or pipeline is added. Continuous monitoring with real-time alerts and per-team attribution is the only durable approach.
- Optimizing compute while ignoring data movement - Egress fees, cross-region transfers, and ETL duplication often represent 15-25% of total spend and are routinely overlooked until a billing review surfaces them as a surprise.
- Applying one pricing model to all workloads - Production batch pipelines and ad-hoc analyst queries have completely different profiles. Treating them identically means neither is optimized.
- Assuming architectural limitations are immovable - Modern engines are designed for zero-friction adoption alongside existing infrastructure. Architectural optimization is more accessible than it was even two years ago.
- Governing at the wrong granularity - Cluster-level alerts that notify a team after monthly spend exceeds a threshold don't prevent the query that blew the budget from completing. Query-level real-time guardrails do.
- Ignoring the engineering cost of complexity - A 10% reduction in cloud spend that requires a full-time engineer to maintain is a trade. Total cost of ownership includes engineering overhead.
- Overlooking the performance-cost relationship - Faster queries are almost always cheaper queries in consumption and per-scan pricing models. Query performance optimization and cost optimization are, in most cases, the same initiative.
How e6data Solves Data Warehouse Cost Optimization
e6data is a high-performance lakehouse compute engine built for SQL analytics and AI workloads. It delivers up to 60% lower compute costs and 10x faster query performance by addressing the structural inefficiencies that make traditional cost optimization a never-ending project.
The Atomic Architecture Advantage
e6data is powered by the industry's only Atomic Architecture, analytics execution broken into independent microservices that scale at the vCPU level through standard Kubernetes APIs. In a traditional engine, every query gets a node's worth of resources whether it needs them or not. In e6data, every query gets exactly the compute it needs, measured and billed in vCPU seconds. If a query needs 3.7 vCPUs for 4 seconds, that's what it consumes. If 200 concurrent queries arrive simultaneously, the engine allocates exactly the aggregate vCPU capacity they collectively require.
Zero Data Movement Architecture
e6data queries data directly in your existing object store across any table format, Parquet, Iceberg, Delta, Hudi, ORC, CSV, JSON, AVRO. Your data stays in your lakehouse. e6data's compute layer reads it in place, eliminating egress fees, pipeline costs, and data duplication overhead. Its location-aware compute scheduler routes each query's compute tasks to the cluster closest to the relevant data, eliminating cross-region data movement structurally. Organizations using this architecture have achieved up to 95% reduction in egress costs with no ongoing management required.
Per-Cluster Query Guardrails
Per-cluster configurable thresholds automatically log, alert on, or cancel queries in real time before they consume excess compute. The governance gap most optimization programs leave open, the gap between knowing a query is expensive and preventing it from completing, closes entirely. Zero-failed SLAs due to poorly optimized queries become achievable rather than aspirational.
Real Production Results
One enterprise customer achieved 1,000 QPS concurrency with p95 SLAs under 2 seconds on near-real-time data with complex queries, performance other leading engines could not match at any TCO. Rajeev Purohit, Head of Platform Engineering at Freshworks, noted that e6data demonstrated impressive performance, concurrency, and granular scalability across their most resource-intensive workloads.
In TPC-DS benchmark testing against Microsoft Fabric's OneLake, e6data delivered 33% faster query performance than native Fabric SQL engines without increasing costs, duplicating data, or requiring any query rewrites. For teams already running Databricks with open lakehouse storage, e6data introduces Atomic scaling without displacing the existing architecture, teams report an additional 40-60% cost reduction on top of existing Databricks optimizations when routing cost-sensitive SQL workloads through e6data.
Taking Action: Your Next Steps
- Start with the audit. Pull three months of billing data, segment by compute, storage, and networking, and identify your top cost drivers. This initial audit will almost certainly surface addressable waste within your existing architecture.
- Work through the eight steps sequentially. Right-sizing compute and implementing auto-suspend deliver the fastest initial savings. Query optimization and storage lifecycle management compound over time. Governance and attribution prevent costs from drifting back upward after you've brought them down.
- If you're already applying these tactics and costs still grow faster than business value, the conversation has shifted to architecture. Modern lakehouse compute engines like e6data plug into your existing architecture without data migration or query rewrites and deliver structural savings that tuning within your existing engine cannot replicate.
- The e6data cost calculator at e6data.com/pricing provides a direct comparison based on your actual vCPU consumption patterns. You can also request a production evaluation where e6data's team runs your most expensive workloads and delivers results on your real data, typically within weeks.
Conclusion
Data warehouse cost optimization spans compute management, query engineering, storage lifecycle, pricing model alignment, governance, and architectural design. Neglecting any layer creates conditions for costs to climb back up after you've worked to bring them down.
The critical distinction is between operational optimization and structural optimization. Operational work, right-sizing, query tuning, auto-suspend, storage lifecycle is necessary and valuable. But it has a ceiling. Once you've tuned everything within your existing architecture, remaining costs are driven by how the engine scales.
That's when architecture matters. Traditional node-level scaling creates structural over-provisioning by design. Atomic scaling at the vCPU level, per-vCPU billing, and zero-data-movement execution address cost at its source rather than managing symptoms. e6data was built to deliver this, cost efficiency at the scale, performance, and reliability modern analytics demand, without migrations, rewrites, or disruption. On this platform, cost optimization and performance optimization are the same goal.
Listen to the full podcast
Share this article
FAQs
What is data warehouse cost optimization?
The systematic practice of reducing the total cost of operating a cloud data warehouse while preserving or improving query performance and reliability. It encompasses compute management, query efficiency, storage lifecycle management, pricing model alignment, and cost governance.
What are the biggest drivers of high data warehouse costs?
Idle compute on over-provisioned clusters, node-level scaling that charges for capacity headroom at low utilization, inefficient queries scanning far more data than necessary, data movement and egress fees from ETL pipelines, and storage accumulation from data that is never queried or cleaned up.
What is the average data warehouse cost for enterprises?
Costs vary dramatically based on data volumes, query concurrency, workload types, and pricing model choices. Enterprises at scale typically spend several hundred thousand to several million dollars annually, with compute representing 50-70% of total spend.
What are the best data warehouse cost optimization strategies?
Right-sizing compute and implementing auto-suspend, optimizing queries to reduce data scanned, aligning workloads with the appropriate pricing model, eliminating idle compute through architecture, reducing data movement with query-in-place approaches, and introducing real-time query guardrails.
What is the best pricing model for variable workloads?
Per-vCPU usage-based pricing or consumption-based pricing provides the best alignment between spend and actual usage. Reserved capacity can be cost-effective for stable portions of workloads but should not be applied to inherently variable query patterns.
How does e6data reduce data warehouse costs?
Through its Atomic Architecture, compute scales at the individual vCPU level, you pay only for vCPU seconds consumed. In production, this delivers up to 60% lower compute costs and 10x faster query performance.
Can I use e6data without migrating my existing data?
Yes, e6data reads data directly in your existing object store in open formats including Parquet, Iceberg, Delta, Hudi, ORC, CSV, JSON, and AVRO.
How do I manage costs in a data warehouse with multiple teams?
Per-team cost attribution, workload isolation across separate compute clusters, budget alerts that notify team owners before spend exceeds targets, and real-time query guardrails that prevent individual queries from consuming disproportionate compute. e6data supports all of these natively.
How often should I review my optimization strategy?
For teams with active workload growth, monthly reviews of key cost metrics with quarterly architectural assessments. For stable environments, quarterly reviews of cost trends, utilization metrics, and top cost drivers are typically sufficient. Revisit explicitly whenever a significant new workload is added.
What optimizations require no architectural changes?
Auto-suspend policies for idle clusters, query tuning to eliminate full-table scans and add partition filters, storage lifecycle management to archive or delete cold data, workload separation to match pricing models to workload types, and per-cluster cost attribution to create team-level accountability.
.svg)
.svg)
.svg)
.svg)
Available at
.png)

.svg)