.svg)
.svg)
.svg)
Subscribe to our newsletter - Data Engineering ACID
Share this article
.svg)
.svg)
German Strings: The 16-Byte Secret to Faster Analytics
September 19, 2025
/
Engineering

Key Takeaways:
- German Strings are an optimized 16-byte string representation that stores a length and inlined prefix, greatly improving string handling performance in databases.
- By inlining short strings and prefixes, this format avoids costly pointer dereferences and leverages cache locality – yielding up to ~3x faster string comparisons in our tests.
- German Strings assume immutable strings and target read-mostly workloads. They eliminate many memory allocations and copies, which reduces GC pressure and overall memory usage.
Every database deals with text data, and strings often dominate data workloads. In analytical queries, string processing can become a major bottleneck. Traditional string representations (like typical null-terminated C strings or heap-allocated objects) carry significant overhead: extra metadata, pointer indirections, and poor cache locality. Over millions of rows, those inefficiencies add up. To unlock faster insights, modern analytics engines require a more cache-friendly, compact way to handle text. This is why we’re excited about German Strings, an approach that restructures how strings are stored in memory to dramatically boost string performance. At e6data, we’ve implemented this optimization in our real-time analytics engine as a new feature to supercharge text-heavy queries.
Origin of the Term “German Strings”
The quirky name comes from academic lineage. The concept was first described in a 2018 paper from TUM (Technical University of Munich) and implemented in their Umbra database system. Andy Pavlo jokingly dubbed them “German Strings” in homage to their German origin, and the nickname stuck. Many wondered if it relates to handling German characters (umlauts, ß, etc.), but it doesn’t – it’s purely about memory layout, not locale or character encoding. (For the record, German Strings fully support Unicode (UTF-8) text like any other string type). The success of the idea has made it widespread, appearing in systems like DuckDB, Apache Arrow (DataFusion), Polars, and Meta’s Velox engine. This broad adoption underlines that German Strings aren’t a niche experiment, but a proven technique now everywhere in analytics databases.
How German Strings Work (16-Byte Layout)
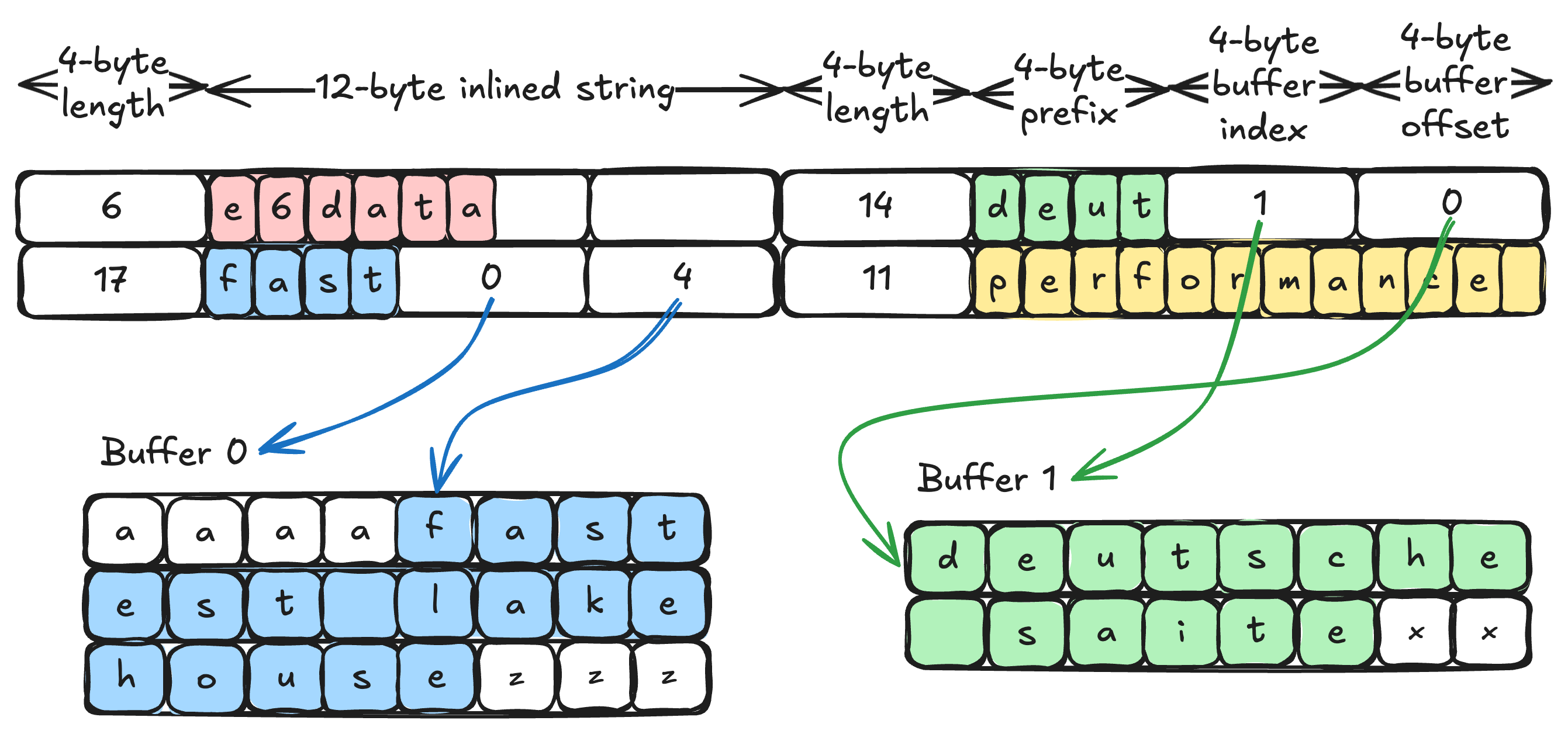
At the heart of German Strings is a fixed 16-byte string struct design. In those 16 bytes, the string’s essential info is stored in one of two ways, depending on length: short-string or long-string format. For short strings (≤ 12 bytes), the struct stores the string inline. The first 4 bytes are used to record the string’s length, and the remaining up to 12 bytes directly contain the string characters. There’s no separate heap allocation at all – the text lives right inside the struct. For example, a string like e6data(6 bytes) fits entirely within the 16B structure, including its length field.
For longer strings (> 12 bytes), the struct acts as a smart reference. It still begins with a 4-byte length, but instead of storing the whole content, it stores a prefix and a pointer substitute. A copy of the string’s first few characters (typically the first 4 bytes) is embedded as a prefix, and the struct uses the remaining space to hold two 32-bit values that locate the full string data elsewhere. In our implementation (which aligns with Apache Arrow’s StringView), those two 32-bit fields serve as a buffer index and an offset. They tell us which memory buffer holds the rest of the string and where it starts, instead of an actual raw pointer. By splitting an 8-byte pointer into two 4-byte indices, we can reference string data spread across potentially multiple buffers, useful for memory management and zero-copy data loading in columnar formats. Crucially, we still keep a 4-byte prefix of the string in the struct itself as a quick reference to its beginning.
What are the Key Benefits of German Strings?
Inline Prefix = Faster Comparisons
- German Strings store a 4-byte inline string prefix plus length in the 16-byte string struct.
- Equality checks, joins, and filters compare length and prefix first, using fast integer comparisons in CPU registers.
- Most comparisons short-circuit on the prefix, often ~95% of cases, avoiding full scans.
- In our microbenchmarks, equality checks are 3 to 3.5x faster with the inline string prefix enabled.
16-Byte Struct = Better Cache Locality & Less Overhead
- Fixed 16-byte string struct keeps headers contiguous, improving cache locality and branch prediction for vectorized scans.
- Modern CPUs can load and compare multiple German Strings simultaneously using SVE/AVX2/AVX-512 instructions, processing 2-4 strings per instruction. The uniform size means no branching for size checks during SIMD operations (The short-string optimization from C++ switches between layouts for each string, potentially causing a lot of branch mispredictions).
- In the usual string vectors, each string’s prefix is far apart in memory, especially when the strings are long. That leads to more frequent memory access. In the case of German Strings, with a typical cache line of 64 bytes, we can fetch four German String structs in one memory access
- Typical std::string is ~24 bytes; moving to 16 bytes cuts about 33% metadata overhead.
- 16 bytes fits common calling conventions, so simple comparisons can use far fewer CPU instructions than larger objects.
Fewer Copies and Memory Savings
- German Strings references long payloads by buffer index and offset, enabling reuse and dedupe of repeated values.
- Creating a substring simply means adjusting the offset and length fields; no data movement at all. Operations like SQL substr, trimming or splitting operations, or any window function over text data are benefited.
- Common operations like slicing and filtering adjust indices instead of allocating new strings, reducing copies.
- During ingestion, especially from Parquet length-prefixed data, engines can wrap buffers directly, avoiding extra moves.
- Teams report 20% to 200% end-to-end gains on string-heavy workloads when German Strings is enabled.
- Fewer copies reduce GC pressure and overall memory traffic in read-mostly analytics.
This also pairs really well with dictionary encoding. Fixed-size views can point into a shared dictionary buffer, and the prefix enables quick dictionary lookups without dereferencing.
This also enables us to try out a bunch of interesting (and potentially more performant) things on the existing tasks. For example, you can basically now treat the 4 bytes as an integer and do a radix sort on the strings, and only do a fallback when necessary.
What are the Drawbacks and Trade-offs of German Strings?
- Small-string overhead: With German Strings and StringView, every value carries a 16-byte string struct. In an offsets-based layout a tiny value might use ~4 bytes of offset plus a few data bytes. For very short strings this means a higher per-value footprint until dedupe or reuse of shared buffers pays it back.
- When to compact buffers: Deciding where in the query lifecycle to compact the shared buffers is non-trivial. Compacting too early adds extra work and can stall hot operators. Compacting too late increases memory use and can hurt cache locality. We are experimenting with operator-aware heuristics similar to DataFusion’s implementation.
- Data-dependent gains: The inline string prefix accelerates comparisons when early bytes are discriminative. If many values share the same initial bytes, the engine falls back to full comparisons more often, and the benefit shrinks. In edge cases, the fallback path can be slightly slower, since German Strings optimize the fast path at a small cost to the slow path.
- Character indexing on UTF-8: Operations like indexAt by character become trickier with variable-width UTF-8. You either walk bytes from the start or maintain extra per-value character offsets. Runtimes that use fixed-width code units avoid this, but with UTF-8, we may need auxiliary indices when workloads rely on character positions.
Our Implementation at e6data
- e6data’s implementation of German Strings is inspired by Apache Arrow’s StringView layout (https://arrow.apache.org/docs/format/Columnar.html#variable-size-binary-view-layout)
- The engine seamlessly converts standard string data to StringView, buffer management, and compaction behind the scenes; the change is transparent to SQL and API users.
- Microbenchmarks on selective string comparisons in filters and joins show 3x to 3.5x speed improvements with German Strings enabled.
- External validation: Apache DataFusion reports up to 2x end-to-end gains on string-heavy workloads after incorporating StringView.
- Ongoing work focuses on full-scale benchmarks and smart buffer compaction to keep performance consistent.
Conclusion
German Strings is a small change that pays off in a big way. By switching to a 16-byte, prefix-inclusive format, we trim memory overhead and speed up common string operations. If you work in data engineering, you know strings are everywhere, so better string performance shows up across filters, joins, and sorts. At e6data, adopting German Strings lets our real-time analytics engine move faster without asking you to change a thing.
This approach is no longer just a research idea. You can see versions of it in DuckDB and in Apache Arrow’s StringView, and the results hold up under pressure. In our own testing, plans that used to grind through full strings now resolve early using the inline string prefix, which improves cache locality and cuts needless work.
The big picture is simple. German Strings help our engine treat text more like numbers. You get quicker queries, lower latency, and leaner memory use, especially when workloads hammer on equality checks and prefix comparisons. We’re rolling this out across the e6data platform and pairing it with other practical wins, like better hash tables for string keys. Sometimes performance comes from perfecting the basics. Here, it comes from 16 well-used bytes.
References
Why German Strings are Everywhere
A Deep Dive into German Strings
Using StringView / German Style Strings to Make Queries Faster: Part 1- Reading Parquet
Using StringView / German Style Strings to make Queries Faster: Part 2 - String Operations
Listen to the full podcast
Share this article
FAQs
What are German Strings in analytics?
A fixed 16-byte string representation that stores a 4-byte length plus an inline prefix. Short strings (≤12 bytes) are fully inlined; longer strings embed a prefix and reference the rest via buffer index and offset. The compact, cache-friendly struct replaces pointer-heavy layouts.
How do German Strings speed up comparisons and joins?
Engines first compare length and the 4-byte inline prefix using fast integer operations; about 95% of equality checks short-circuit before touching full payload. In microbenchmarks, e6data saw 3–3.5x faster equality checks when the prefix optimization is enabled.
Are German Strings related to the German language or special characters?
No, the name traces to a 2018 TUM (Umbra) paper, and Andy Pavlo jokingly coined “German Strings.” It’s about memory layout, not locale or character sets. They fully support Unicode/UTF-8 text.
How are short and long strings laid out?
Short strings (≤12B): 4B length plus up to 12B inlined value—no heap allocation. Long strings (>12B): 4B length, 4B inline prefix, 4B buffer index, 4B offset; the remaining bytes live in shared buffers referenced by index/offset.
What hardware and cache benefits come from the 16-byte struct?
Uniform 16-byte structs improve cache locality and branch prediction. Modern CPUs (SVE/AVX2/AVX-512) can compare multiple strings per instruction—typically two to four. Typical std::string is about 24 bytes; 16 bytes trims roughly one-third of metadata and lets vectorized scans load several headers per cache line.
Which operations get cheaper besides equality checks?
Slicing, substrings, trim/split, and many window functions adjust indices (offset and length) instead of copying bytes. During ingestion, engines can wrap Parquet’s length-prefixed buffers directly. Shared buffers enable reuse and dedup; dictionary encoding benefits from fixed-size views and the inline prefix. You can even radix-sort on the 4-byte prefix with fallback.
What are the main drawbacks or tradeoffs of German Strings?
For very short values, each 16-byte struct can outweigh offsets-based layouts. Deciding when to compact shared buffers is non-trivial. Gains are data-dependent—similar prefixes reduce early exits. With UTF-8, character indexing may require auxiliary indices. German Strings assume immutability and target read-mostly workloads.
Where else is this approach used?
Beyond e6data, variants appear in DuckDB, Apache Arrow (DataFusion), Polars, and Meta’s Velox. The approach traces back to the Umbra system at TUM.
What performance results are reported?
e6data microbenchmarks report 3–3.5x faster equality checks for filters and joins. Apache DataFusion reports up to 2x end-to-end gains on string-heavy workloads. Teams report roughly 20%–200% end-to-end improvements when German Strings are enabled.
Is the feature transparent to e6data users?
Yes, e6data converts standard strings to a StringView-style layout, manages buffer index/offset and compaction internally, and requires no SQL or API changes.
.svg)
.svg)
.svg)
.svg)
Available at
.png)

.svg)