.svg)
.svg)
.svg)
Subscribe to our newsletter - Data Engineering ACID
Share this article
.svg)
.svg)
Building a Modern Data Pipeline in Snowflake: From Snowpipe to Managed Iceberg Tables with Sync Checks
July 25, 2025
/
Engineering
As data volumes grow and real-time analytics become essential, organizations are turning to open table formats like Apache Iceberg to build flexible, scalable data lakehouse architectures. One of Iceberg’s key strengths is its open data catalog, a shared, standardized metadata layer that tracks table schema, partitions, snapshots, and other versions. This open catalog provides a single source of truth for table metadata, ensuring all engines see the same schema and table state (snapshots) with ACID transactional guarantees. In practice, the catalog allows multiple systems to operate on a single copy of data, so different query engines (Snowflake, Spark, Trino, Presto, e6data, etc.) can all query the exact same data and get consistent results. Iceberg’s design brings SQL table reliability (ACID transactions, schema evolution, time travel) to data lakes, enabling multi-engine interoperability without vendor lock-in.
Snowflake’s recent support for managed Iceberg tables leverages this open catalog to provide seamless cross-platform querying. A Snowflake-managed Iceberg table is an Iceberg table where Snowflake manages all writes and metadata, but the data is stored in your cloud storage in an open format (Parquet files with Iceberg metadata). In other words, Snowflake’s powerful SQL engine can insert and update data in the table, and other tools can read the same table via the open catalog. Snowflake writes data to cloud object storage (e.g., Amazon S3) as Parquet and stores the table’s metadata (snapshots, manifests, schema definitions) in the Iceberg format on that storage. This means you can use Snowflake for its performance and ease-of-use, alongside other processing engines on the same data, without data duplication or complex ETL transfers.
The Iceberg metadata acts as a neutral interface for any compatible engine to see the table’s latest snapshot and schema. Snowflake’s product team emphasizes that this approach gives customers the freedom to “mix and match multiple query engines, in any fashion, without lock-in.” In short, Snowflake-managed Iceberg tables enable agility, strong governance, and easy data sharing across diverse analytic tools on a unified dataset, all while avoiding the “new lock-in layer” of proprietary catalogs.
In this blog, we walk through building a modern data pipeline in Snowflake that ingests data via Snowpipe, transforms it, writes into a Snowflake-managed Iceberg table, and performs data quality checks to ensure everything stays in sync. It does all this while benefiting from Apache Iceberg’s open data catalog and multi-engine compatibility.
Overall Architecture - Data Pipeline
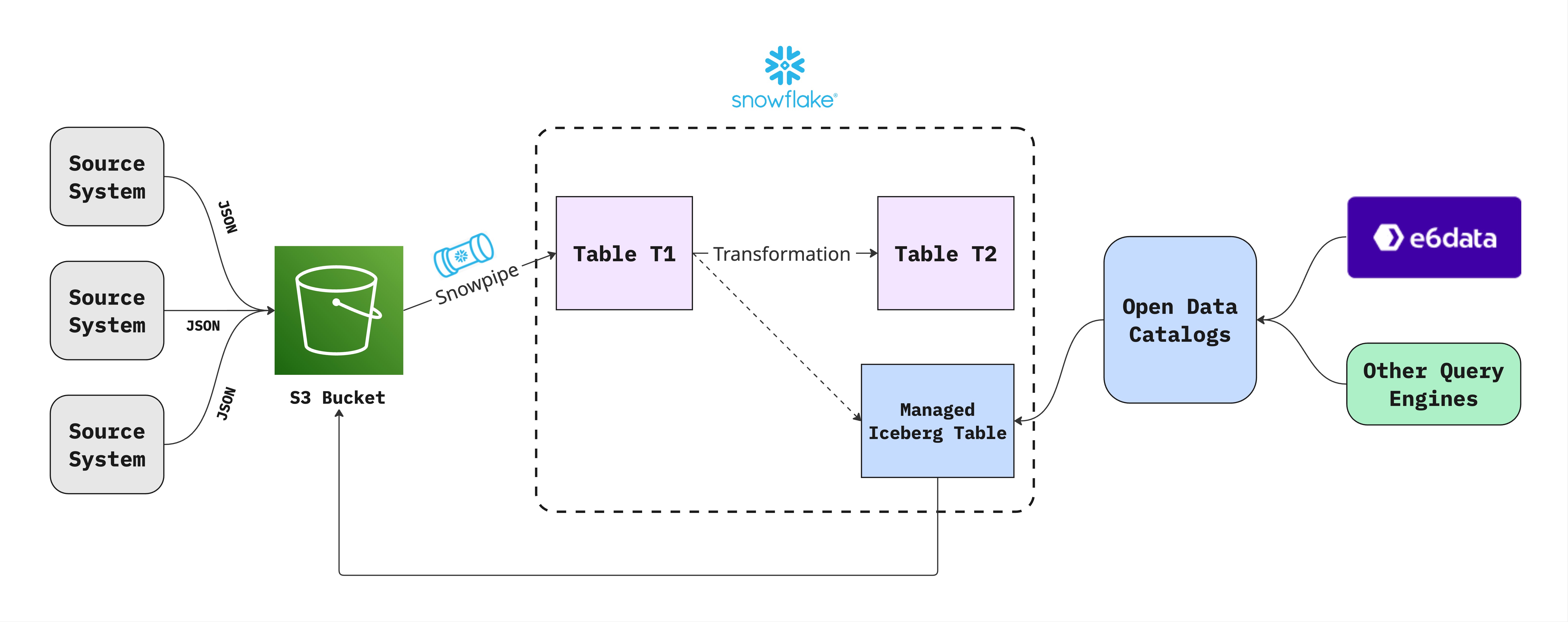
Here are the SQL statements to create the main tables used in the pipeline:
-- Landing table: raw data ingested by Snowpipe
CREATE OR REPLACE TABLE landing_orders (
order_id STRING,
order_date STRING,
amount FLOAT
);
-- Core curated table with cleaned and standardized data
CREATE OR REPLACE TABLE core_orders (
order_id STRING,
order_date DATE,
normalized_amount NUMBER(10, 2)
);
-- Managed Iceberg table for analytics
CREATE OR REPLACE ICEBERG TABLE managed_iceberg.orders (
order_id STRING,
order_date DATE,
normalized_amount NUMBER(10, 2)
)
EXTERNAL_VOLUME = 'snowflake_volume'
CATALOG = 'SNOWFLAKE'
BASE_LOCATION = 's3://snowflake/orders';
Real-World Example: Daily Batch Processing for E-Commerce Orders
Imagine you run a data platform for an e-commerce company. Every night at 2 AM, new JSON files containing the latest orders are dropped into an Amazon S3 bucket. Your goals are to:
- Automatically ingest the daily order data into Snowflake as soon as it arrives.
- Apply business rules via transformations (e.g., remove or flag invalid orders with negative amounts, standardize date formats).
- Store the cleaned data in a Snowflake-managed Iceberg table for analytics and multi-engine access.
- Perform data quality checks to ensure the Iceberg table is fully synchronized with the curated source data.
- Automate the entire pipeline to run daily without manual intervention.
Daily Pipeline Flow
Step 1: Data Lands in S3
At 2 AM, a JSON file like this lands in s3://ecom-data/orders/2025-07-08/orders.json:
[
{"order_id": "A123", "order_date": "2025-07-07", "amount": 499.99},
{"order_id": "A124", "order_date": "2025-07-07", "amount": -100}
]Step 2: Snowpipe Auto-Loads to Landing Table
CREATE OR REPLACE STAGE ORDER_STAGE
url = 's3://ecom-data/orders/'
STORAGE_INTEGRATION = 'snowflake_storage_integration'
file_format = (type ='JSON')
CREATE or replace PIPE ORDER_PIPE
AUTO_INGEST = TRUE
AS
COPY INTO landing_orders
FROM @s3_orders_stage_v2
FILE_FORMAT = (type = 'JSON')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;
Snowpipe automatically ingests new files from S3 into the landing_orders table near real-time, enabling continuous data arrival.
Steps 3 and 4: Transformation and Iceberg Load (Encapsulated in Procedure)
To simplify management and ensure atomicity, the transformation and Iceberg load are encapsulated in a stored procedure transform_orders():
CREATE OR REPLACE PROCEDURE transform_orders()
RETURNS STRING
LANGUAGE SQL
AS
$$
BEGIN
-- Remove invalid records from landing_orders (e.g., negative amounts)
DELETE FROM landing_orders WHERE amount <= 0;
-- Load cleaned and transformed data into core_orders
INSERT INTO core_orders
SELECT
UPPER(TRIM(order_id)) AS order_id,
TO_DATE(order_date) AS order_date,
ROUND(amount, 2) AS normalized_amount
FROM landing_orders;
-- Insert new records into managed Iceberg table for analytics
INSERT INTO managed_iceberg.orders
SELECT * FROM core_orders
WHERE order_date = CURRENT_DATE - 1;
RETURN 'Transform and load completed';
END;
$$;
Note: The procedure assumes that Snowpipe has finished loading the daily batch before transformation starts to avoid deleting records prematurely.
Step 5: Data Quality Check
Ensuring the data is fully synchronized between the curated table and the Iceberg table is critical for reliable analytics.
You can run row count and difference checks like this:
-- Compare record counts
SELECT
(SELECT COUNT(*) FROM core_orders WHERE order_date = CURRENT_DATE - 1) AS core_count,
(SELECT COUNT(*) FROM managed_iceberg.orders WHERE order_date = CURRENT_DATE - 1) AS iceberg_count;
-- Identify mismatched records
SELECT * FROM core_orders WHERE order_date = CURRENT_DATE - 1
MINUS
SELECT * FROM managed_iceberg.orders WHERE order_date = CURRENT_DATE - 1;
For more robust validation, consider extending this with checksum or hash comparisons.
Step 6: Automate with a Daily Task
Schedule the pipeline to run daily with Snowflake Tasks:
-- Create task to automate the pipeline
CREATE OR REPLACE TASK daily_order_pipeline
WAREHOUSE = prod_wh
SCHEDULE = 'USING CRON 0 2 * * * UTC' -- 2 AM UTC daily
AS
BEGIN
CALL transform_orders();
END;
-- Enable Task
ALTER TASK daily_order_pipeline RESUME;
This ensures the entire pipeline runs consistently every day without manual intervention.
To streamline and automate modern data pipelines alongside Snowflake, platforms like Peliqan offer low-code integration flows and orchestration between diverse sources, transformation logic, and quality checks.
Peliqan enables teams to design, schedule, monitor, and troubleshoot complex pipelines using both SQL & Python, integrating seamlessly with Snowflake and other lakehouse targets - reducing engineering overhead and accelerating time-to-value.
Conclusion
By combining Snowpipe for automated ingestion, SQL transformations for data cleaning, and Snowflake-managed Iceberg tables for storage, you can build a modern, scalable data pipeline that offers several key benefits:
- Automated ingestion and transformation: New data is loaded and processed continuously or on schedule without manual intervention, keeping datasets fresh.
- Clean, curated data for analytics: The pipeline enforces business rules and data quality checks during the transform step, producing high-quality, trusted data in a curated format.
- Access to Apache Iceberg’s open data catalog: The managed Iceberg table leverages Iceberg’s open metadata layer (the catalog of table snapshots, schema, partitions, etc.), which is shared across engines.
- Seamless multi-engine interoperability: Because the data is in Iceberg format (Parquet files + Iceberg metadata) on cloud storage, you can query it not only from Snowflake but also from Spark, Trino, Presto, e6data, or any other engine that supports Iceberg
- End-to-end data quality checks: Built-in quality checks (e.g., using Snowflake’s DMFs or custom SQL queries) at each stage of the pipeline ensure that issues are caught early.
Snowflake’s managed Iceberg tables effectively unlock the benefits of open data formats and open metadata catalogs while retaining Snowflake’s ease-of-use, performance, and governance features. This aids you in building next-generation lakehouse architectures that support diverse workloads and tools on a unified platform. In other words, you get the freedom of an open data lake (no lock-in, multi-engine access) combined with the convenience and reliability of Snowflake’s Data Cloud in one solution.
Listen to the full podcast
Share this article
FAQs
What is a Snowflake‑managed Iceberg table?
A Snowflake‑managed Iceberg table is an Apache Iceberg table whose data (Parquet files) and Iceberg metadata live in your own cloud storage, while Snowflake handles all writes and snapshot management. You can insert or update it from Snowflake and let any Iceberg‑compatible engine read the same table through the open catalog.
How does Snowpipe get data into Snowflake automatically?
Snowpipe watches an external stage—such as an S3 folder—and, with AUTO_INGEST = TRUE, copies new files into the landing_orders table almost in real time. A JSON stage and pipe call COPY INTO landing_orders, so every file dropped in s3://ecom-data/orders/ is loaded without manual intervention.
Can other engines query the same data written by Snowflake?
Yes, because the data sits in open Parquet files with Iceberg metadata, engines such as Spark, Trino, Presto, e6data or any Iceberg‑compatible tool can read the exact same snapshots Snowflake writes—no copies or conversions required.
What advantages does the combined Snowpipe + Iceberg pipeline deliver?
The design gives automated ingestion, enforced transformations, curated analytics tables, ACID time‑travel, open multi‑engine access and row‑level sync checks—all on cloud object storage. You gain fresh, high‑quality data and lakehouse flexibility without extra ETL or duplicated copies.
.svg)
.svg)
.svg)
.svg)
Available at
.png)

.svg)