.svg)
.svg)
.svg)
Subscribe to our newsletter - Data Engineering ACID
Share this article
.svg)
.svg)
Apache Iceberg vs. Delta Lake vs. Hudi
June 26, 2026
/
General

Picking a table format is one of the hardest data platform decisions to undo. Unlike changing a query engine, where you just need to rewrite some SQL, changing a table format (especially at a larger scale) means redoing your entire data layer, which can be a big hassle.
We'll cover how each one organizes metadata, commits transactions, handles row-level changes, and behaves under concurrency - plus where they're converging, and how format-agnostic compute engines are changing the decision.
TL;DR
Apache Iceberg - Best for new, multi-engine lakehouses. It's vendor-neutral, works with the widest range of engines (Spark, Flink, Trino, Snowflake, BigQuery, Athena, DuckDB, Dremio), and supports partition evolution. Apache Iceberg’s V3 is already out with added specs like deletion vectors, row lineage, and more data types. V4 is also under active development, which will change the metadata structure and add new specs and features.

Delta Lake - Best if you're already in the Databricks or Spark ecosystem. It has the deepest Spark integration, the largest user base, and a clean transaction model. UniForm lets Delta tables work with Iceberg and Hudi readers.

Apache Hudi - It’s one of the strongest fits for streaming data, CDC, and frequent upserts. Its record-level index and timeline architecture are built for fast, mutable pipelines. Version 1.0/1.1 added secondary indexes, expression indexes, and non-blocking concurrency.
It's also worth noting that while Delta Lake has one of the largest user bases, Apache Iceberg is quickly catching up. Thanks to its flexibility and new features, it is becoming the top choice for many engineering teams.
If you are already using multiple formats and don't want to migrate, then the simplest answer is a compute engine that reads all three natively - more on that at the end.
Why table formats exist at all
A data lake is just files in object storage (S3, GCS, ADLS). That's cheap and infinitely scalable, but raw files can't give you atomic commits, consistent reads during writes, schema evolution, or time travel. The classic Hive table, directories as partitions, falls apart once you have thousands of partitions and millions of files: listing operations dominate, metadata is unreliable, and concurrent writers corrupt state.
Open table formats fix this by tracking files and snapshots instead of directories.
They add a metadata layer on top of Parquet/ORC that delivers three things every engineer wants: atomic transactions (a write either fully lands or doesn't), consistent reads (queries never see a half-written table), and metadata that scales (query planning doesn't choke as the table grows). Iceberg, Delta, and Hudi solve this; they just disagree on how. (The lakehouse pattern they implement was formalized by Databricks in a 2021 CIDR paper.)
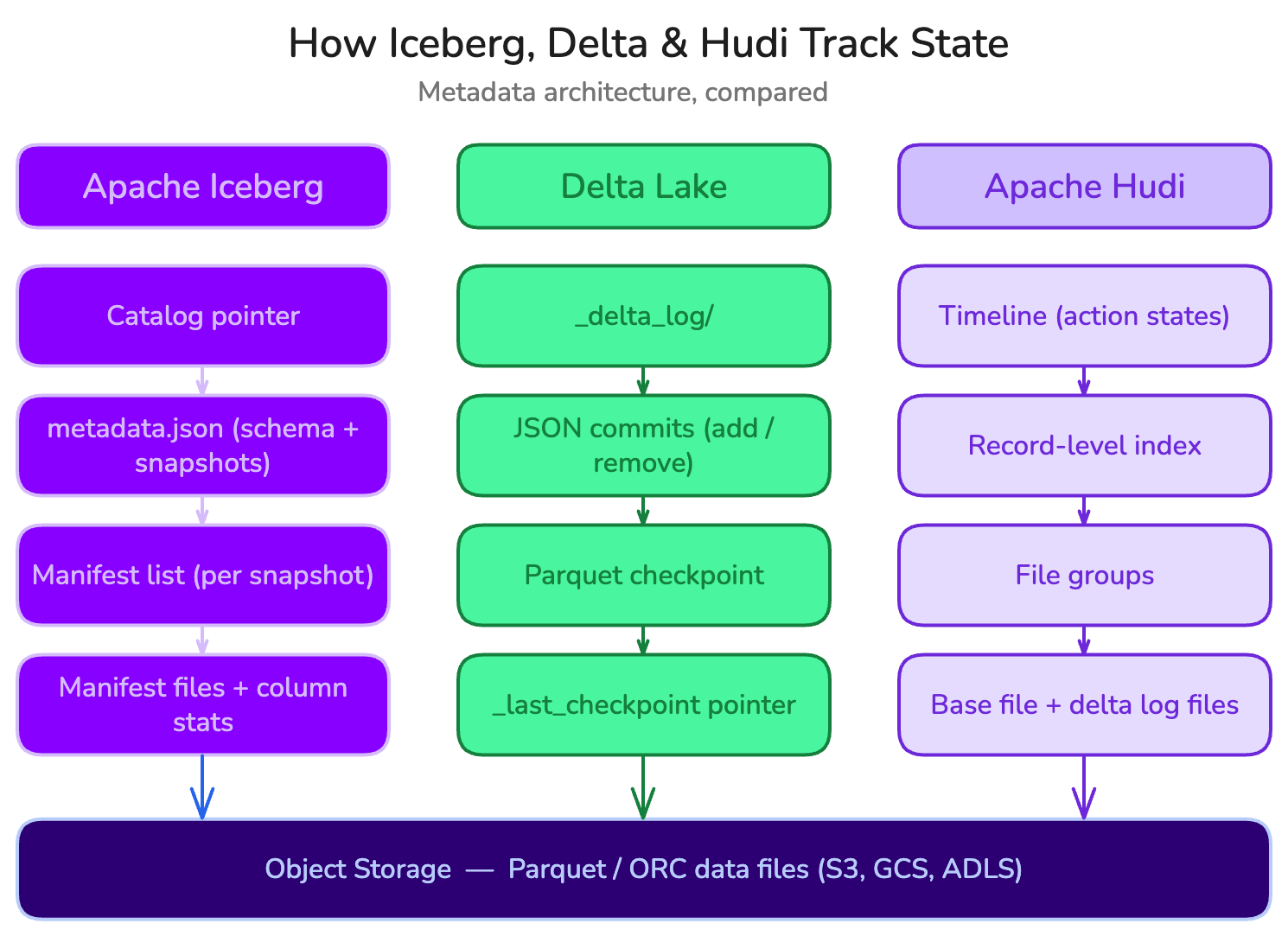
Architecture: how each format tracks state
The metadata model is the single biggest architectural difference, and it drives everything downstream: planning speed, concurrency safety, and operational overhead.
Apache Iceberg: a hierarchical snapshot tree
Iceberg uses a layered tree. A catalog holds a pointer to the current metadata.json. That metadata file records the schema, partition specs, and the list of snapshots.
Each snapshot points to a manifest list, pointing to manifest files, and finally tracks the individual data files along with column-level statistics (min/max, null counts) and partition values.
That stats-rich hierarchy is why Iceberg prunes well. The planner can eliminate entire manifests and data files before reading anything. Commits are an atomic swap of the metadata pointer using optimistic concurrency: write your new files and metadata, then attempt to compare-and-swap the pointer; if someone else committed first, retry against the new snapshot.
The full set of guarantees is defined in the open Iceberg table spec, which versions them as V1–V3.
Delta Lake: an ordered transaction log
Delta's source of truth is the _delta_log directory: an ordered sequence of JSON commit files (000000.json, 000001.json, …), each describing add and remove file actions. To avoid replaying the entire log, Delta periodically writes a Parquet checkpoint that collapses state into a single snapshot, with a _last_checkpoint pointer for fast lookup.
This log-structured design is conceptually simple and integrates tightly with Spark, which is both Delta's strength and its historical constraint. The richest behavior has always lived closest to the Databricks/Spark runtime, though connectors and the Delta Kernel project have broadened reach.
Apache Hudi: a timeline plus file groups
Hudi is the odd one out, and deliberately so. Its source of truth is a timeline, a log of actions that move through states (REQUESTED → INFLIGHT → COMPLETED). Data is physically organized into file groups, each containing a base file plus delta log files. Critically, Hudi maintains a record-level index mapping record keys to the file group that holds them.
That index is the whole point: when an upsert or delete arrives, Hudi knows exactly which file group to touch instead of scanning the table. For CDC and streaming workloads that mutate the same keys repeatedly, this is a structural advantage which no other format matches out of the box.
Feature comparison: how the architectures play out in practice
That covers how each format is built. The architecture comparison above is deliberately separate from what follows—because the more useful question for day-to-day engineering is how those designs behave once you start mutating, evolving, and streaming into these tables.
This section is the feature-by-feature comparison. Here's the at-a-glance version; each row is unpacked in detail below.
The throughline to watch: in each row, the metadata model from the previous section resurfaces as a concrete capability or constraint.
Row-level mutations: COW, MOR, and deletion vectors
How a format handles UPDATE, DELETE, and MERGE reveals its priorities.
Copy-on-Write (COW): rewrite the entire data file containing the changed rows. Read-optimal, write-expensive. Good for batch.
Merge-on-Read (MOR): write small delete/update files and merge them at query time. Write-cheap, read-expensive until compaction runs. Good for frequent mutations.
Deletion Vectors (DV): compact binary bitmaps that mark deleted row positions inside a data file—avoiding the pile-up of separate positional delete files. The most efficient approach for sparse deletes.
Iceberg offers all three: COW and MOR (positional/equality delete files) from V2, and deletion vectors stored as Puffin files in V3.
Delta supports COW and recently added deletion vectors using a bitmap format that's intentionally compatible with Iceberg's. Hudi is built around COW and MOR table types, with its record-level index making targeted upserts efficient regardless of mode.
The convergence here is real: Iceberg V3 and Delta now share compatible deletion-vector encodings and row-tracking semantics, which is part of a broader industry push to unify the data layer across formats.
Concurrency and the write path
Iceberg uses optimistic concurrency control via atomic pointer swaps. Concurrent writers retry on conflict. Clean for analytics; less ideal for very high-frequency writers contending on the same partitions.
Delta also uses optimistic concurrency on the transaction log, with conflict detection based on which files each transaction read and wrote.
Hudi supports multiple concurrency models, including file-group-level locking and, since Hudi 1.0, non-blocking concurrency control (NBCC)—designed so multiple streaming jobs can write to the same dataset without blocking each other. This is a direct answer to the streaming-ingestion problem the other two weren't originally built for.
Schema and partition evolution
This is where Iceberg's design pays off most visibly for engineers who maintain tables over years.
- Iceberg evolves schema by column ID, so add, drop, rename, and reorder are safe metadata-only operations with no data rewrites. It also offers hidden partitioning (queries don't reference partition columns) and partition evolution—you can change the partitioning scheme of an existing table without rewriting historical data. No other format offers true partition evolution.
- Delta supports schema evolution and column mapping (improved substantially in the 3.x line), and replaces rigid Hive partitioning with Liquid Clustering, which lets you change clustering keys incrementally without a full rewrite.
- Hudi handles additive and compatible type changes well and folds partitioning into its indexing system via expression indexes, but renaming or dropping columns and changing partition schemes is more constrained.
Streaming, CDC, and incremental processing
If your workload is "continuously ingest mutations and serve fresh data," the ranking flips toward Hudi.
Hudi was built for this from day one at Uber. Incremental queries pull only changed records since a commit, the record index makes upserts cheap, and built-in table services (ingestion, compaction, clustering, cleaning) make it a self-managing Data Lakehouse Management System, not just a file format.
Iceberg added row lineage in V3 (_row_id, _last_updated_sequence_number), which simplifies change detection and incremental processing—closing part of the gap, especially for audit and CDC pipelines.
Delta supports Change Data Feed and structured streaming reads/writes, and is a natural fit when Spark Structured Streaming is already your ingestion layer.
Ecosystem, governance, and momentum
The best format is useless if your engines can't read it.
Iceberg has the broadest multi-engine support and is governed neutrally by the Apache Software Foundation. The momentum signals from 2024-2025 were hard to ignore: Databricks acquired Tabular (founded by Iceberg's Netflix creators) for over a billion dollars, AWS shipped S3 Tables with native Iceberg support, Snowflake made Iceberg tables GA and open-sourced the Polaris catalog, and BigQuery added managed Iceberg tables. The REST catalog spec has become a de facto standard.
Delta still has the largest installed base, used across a majority of the Fortune 500 and tens of thousands of organizations, anchored by Databricks. Its reach outside Spark keeps widening through connectors and UniForm.
Hudi holds a narrower but deep position with streaming-heavy users like Uber, Amazon, Walmart, and Robinhood, and continues to invest in platform services and indexing.
Case studies
Iceberg: built for open, multi-engine analytics
- Netflix (creator). By 2015, Netflix had moved its 100+ PB warehouse onto S3, and Hive tables became the pain point: no stable atomic transactions, inconsistent behavior across engines, and operations people were afraid to run for fear of corrupting data. Ryan Blue and Dan Weeks built Iceberg to fix correctness and engine-agnostic access, then open-sourced it in 2018. Netflix later paired Iceberg with its Maestro workflow engine for incremental processing, capturing changes without recopying datasets to cut compute cost and improve freshness. [Read more: Iceberg at Netflix and Beyond with Ryan Blue]
- Airbnb. Migrated off a Hive metastore whose partition counts had become a performance bottleneck, forcing shorter retention and coarser aggregation, and adopted Iceberg to restore scalable partition handling and schema evolution. [Read more: Upgrading Data Warehouse Infrastructure at Airbnb]
Hudi: built for mutable, streaming, and CDC-heavy data
- Uber (creator): Uber ingests billions of events daily – rides, deliveries, pricing, locations – that aren't append-only; they need constant updates and corrections. Before Hudi, there was no practical way to apply record-level mutations to data on S3/HDFS. Uber built Hudi to bring upserts, deletes, and incremental pulls to the lake, and its Record Index delivers near-O(1) key lookups on trillion-row tables, which makes upsert-driven ingestion tractable at that scale. Hudi now powers tens of thousands of Uber datasets. [Read more: Apache Hudi™ at Uber]
- Robinhood: Built a CDC streaming lakehouse on Hudi, Kafka into Hudi with incremental processing and efficient upserts, and reportedly cut data freshness from roughly 24 hours to under 15 minutes.
Delta: built for Spark-centric, Databricks-anchored stacks
- Comcast: Used Delta Lake to ingest and enrich raw telemetry from video and voice devices, joining historical and streaming data reliably. The headline result was operational: optimized ingestion replaced 640 machines with 64, a roughly 10x compute reduction, alongside far less DevOps overhead. [Read more: Comcast Delta Lake Case Study]
- Adobe Experience Platform: The Real-Time Customer Profile team replaced a cost-prohibitive NoSQL "hot store" with a Delta-based lakehouse, reporting an 80%+ reduction in scan time on a 1 TB workload and compression from 1 TB down to ~64 GB, while solving multi-source writer conflicts via CDC. [Read more: Adobe Delta Lake Case Study]
The clearest signal of fit is what teams reached for when they hit a wall. The pattern across published engineering accounts is consistent: the workload, not the hype, drove the choice.
One thing worth keeping in mind: the Iceberg and Hudi origin stories come from the teams that built them (Netflix and Uber), and most Delta Lake case studies are published by Databricks. That doesn't mean the numbers are wrong, but the perspective may not be fully neutral.
Focus on the architectural reasoning (e.g., why Hive fell short, why upserts needed an index, why Spark integration mattered); that's the reliable part. Treat the headline metrics as best-case results chosen by vendors, and test them against your own workload.
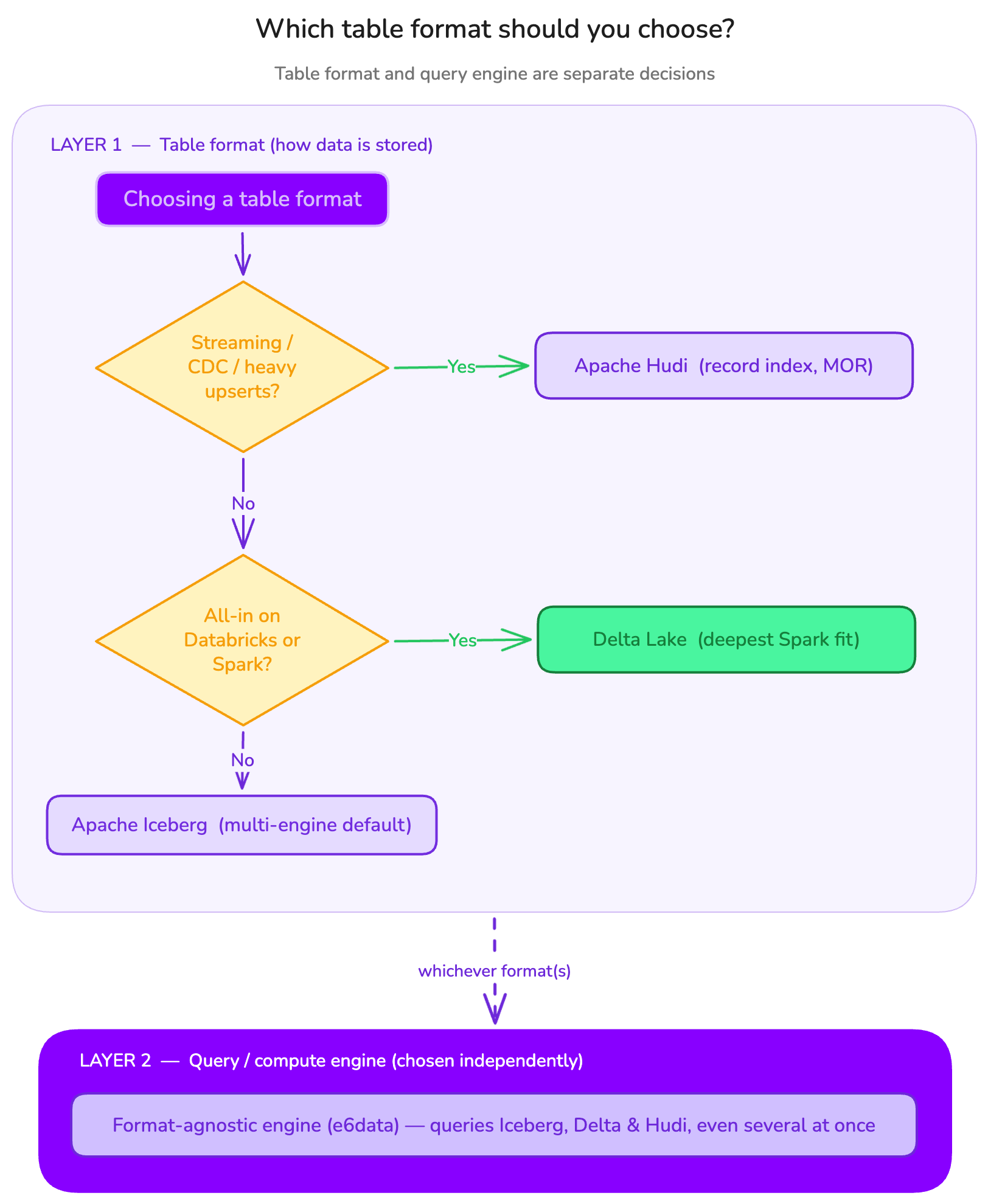
A practical decision framework
- Starting fresh, want multi-engine flexibility and vendor neutrality → Iceberg.
- All-in on Databricks / Spark-centric → Delta (consider enabling UniForm to keep options open).
- Streaming ingestion, CDC, frequent upserts/deletes on mutable data → Hudi.
- Already running more than one format → don't migrate reflexively; put a format-agnostic engine on top.
Where the query engine fits: e6data
A table format defines how data is laid out. A compute engine decides how fast you can query it, and whether you're locked to one format at all.
e6data is a lakehouse compute engine built on a decoupled, decentralized architecture that separates compute from storage. Rather than forcing a format choice, e6data added native, side-by-side support for Apache Iceberg, Delta Lake, Apache Hudi, and the Polaris catalog, so you can run SQL across tables written in any of them from a single workspace, without copying data or rewriting pipelines.
A few things make this relevant to the comparison above:
- A smart catalog layer understands Iceberg and Delta layout metadata natively and talks to Polaris through the same REST interface Iceberg uses, giving you consistent schema discovery, partition browsing, and cross-catalog joins across formats.
- Governance was carried through, with enforcement of catalog privileges (such as Polaris RBAC and Unity Catalog) so users only query what they're entitled to.
- Decoupled compute targets predictable SLAs and low-latency response at high query concurrency, useful for the embedded and interactive analytics workloads where format choice shouldn't dictate query performance.
In other words, if interoperability is the real story of 2026, the engine layer is where that story plays out. You pick the format that fits each workload: Hudi for the streaming ingest, Iceberg for the open analytical tables, and query them together.
The bottom line
For most new lakehouses, Iceberg is the safe default because of governance and engine breadth. Delta remains the pragmatic choice inside Databricks. Hudi is the specialist's pick for streaming and CDC.
But the more durable insight is that the formats are converging (shared deletion-vector encodings, compatible row lineage, and cross-format translation), which means the exclusive bet matters less every quarter. Choose the format that fits the workload, keep your options open with interoperability features, and put a format-agnostic engine on top so the decision never boxes you in.
Want to see your existing Iceberg, Delta, and Hudi tables queried side by side from one workspace? Explore the e6data product documentation to see how the engine handles all three.
Listen to the full podcast
Share this article
FAQs
Is Apache Iceberg always the best table format?
No. Iceberg is the strongest default for new, multi-engine, vendor-neutral lakehouses, but Delta is better inside Databricks/Spark and Hudi is better for streaming ingestion, CDC, and high-frequency upserts. The right choice depends on your engines and workload.
What is the main architectural difference between Iceberg, Delta, and Hudi?
Iceberg uses a hierarchical snapshot tree (metadata.json → manifest list → manifests → data files), Delta uses an ordered transaction log (_delta_log with periodic checkpoints), and Hudi uses a timeline plus file groups with a record-level index for fast upserts.
Can the same data be queried through multiple table formats?
Yes. Apache XTable translates metadata between all three, Delta UniForm exposes Iceberg/Hudi metadata from Delta tables, and Hudi can output Iceberg-compatible tables. A format-agnostic compute engine like e6data can also query Iceberg, Delta, and Hudi natively from one workspace.
What is a deletion vector?
A compact binary bitmap that marks deleted rows inside a data file, avoiding separate positional delete files. Iceberg added them in the V3 spec, and Delta uses a compatible bitmap format, making sparse deletes far more efficient.
Which table format is best for streaming and CDC?
Apache Hudi, because of its record-level index, merge-on-read tables, incremental queries, and non-blocking concurrency control built for high-frequency mutations.
Does choosing a table format lock me into one query engine?
It shouldn't. Iceberg has the broadest engine support, and a decoupled compute engine such as e6data reads Iceberg, Delta, and Hudi natively, so the format choice doesn't dictate which engine you run.
.svg)
.svg)
.svg)
.svg)
Available at
.png)

.svg)