.svg)
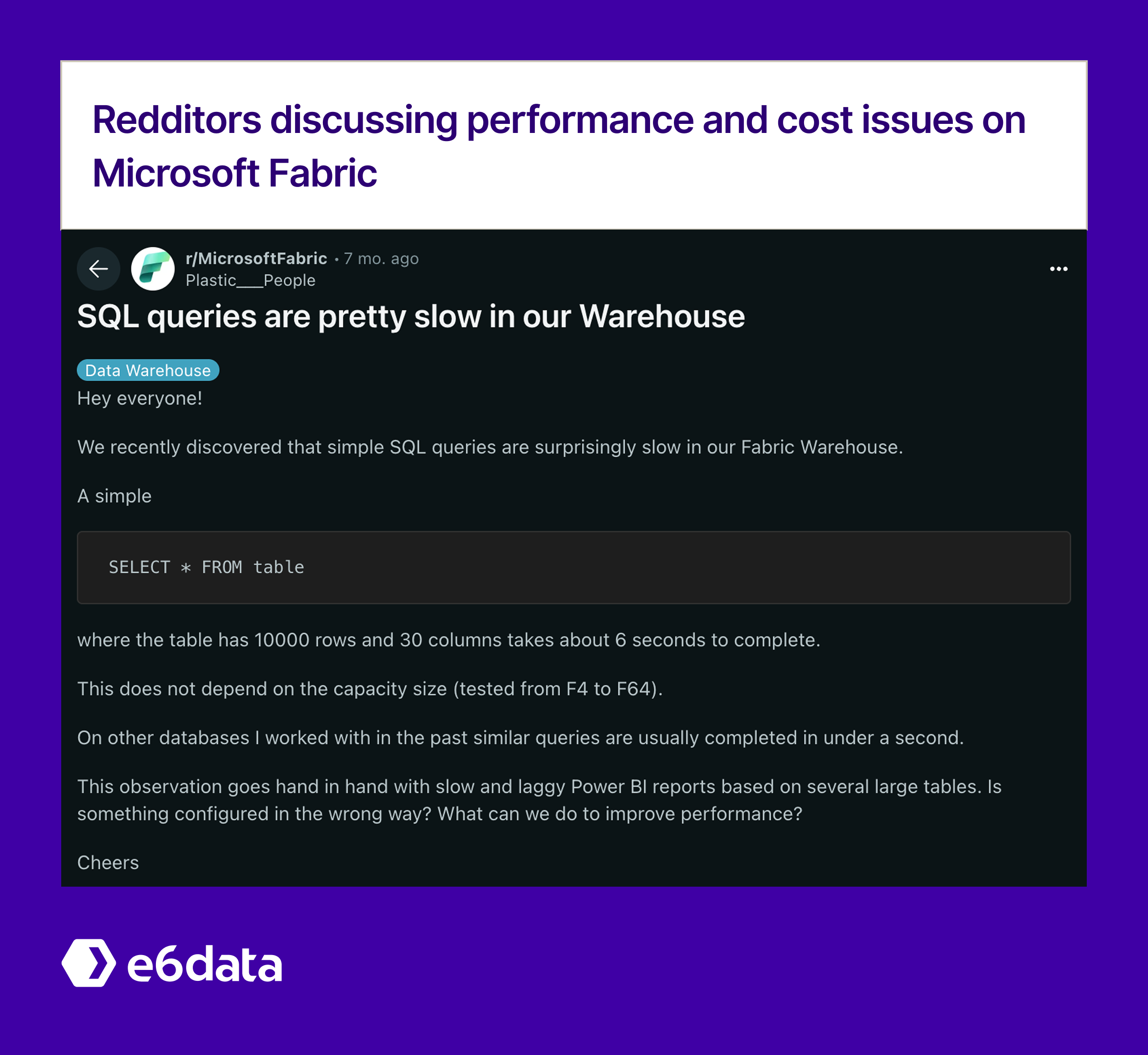
Microsoft Fabric has rapidly become a cornerstone for unified analytics workloads across US enterprises, combining data lakehouse capabilities with real-time analytics in a single SaaS platform. However, as organizations scale their Fabric deployments beyond initial proof-of-concepts, query performance bottlenecks emerge that can cripple BI dashboards, slow analytical workflows, and inflate compute costs. The performance challenges are particularly acute given Fabric's multi-engine architecture spanning SQL Analytics Endpoint, Warehouse, and Lakehouse compute layers.
Senior data engineering teams consistently report three critical pain points: inconsistent dashboard latency across different Fabric engines, unpredictable query performance when scaling from gigabyte to terabyte datasets, and difficulty optimizing cross-engine workloads that span both structured warehouses and semi-structured lakehouse data. This playbook provides battle-tested optimization tactics specifically designed for Fabric's unique architecture, with runnable code examples and clear guidance on when each approach delivers maximum performance impact.
When your Power BI dashboards consistently query specific dimensional combinations (like region + product category + time period), Z-ORDER clustering dramatically improves query performance by co-locating related data within the same data files. You'll see substantially faster dashboard load times when Z-ORDER columns match your most common filter combinations.
The key insight here is understanding your dashboard's query patterns before implementing Z-ORDER. Most enterprise dashboards follow predictable access patterns where users filter by date ranges, geographic regions, or business units. Here's how to implement Z-ORDER optimization for a typical sales dashboard scenario:
1-- Optimize sales fact table for common dashboard filters
2OPTIMIZE sales_fact_delta
3ZORDER BY (region_id, product_category, sale_date);
4
5-- Verify Z-ORDER effectiveness with file statistics
6DESCRIBE DETAIL sales_fact_delta;What makes this particularly effective is that Z-ORDER works at the Parquet file level, reducing the number of files Fabric needs to scan during query execution. When users filter dashboards by "West Region + Electronics + Last 30 Days", Fabric can skip entire files that don't contain relevant data combinations.
Alternative approaches include: V-ORDER clustering for write-heavy scenarios (superior for ETL pipelines but less dashboard optimization), traditional table partitioning by date (simpler implementation but reduced flexibility for multi-dimensional filters), Microsoft Fabric API automation for dynamic optimization, or leveraging e6data as a complementary lakehouse compute engine that automatically optimizes data layout without manual clustering commands while delivering sub-second dashboard latency through its decentralized architecture.
Dashboard performance bottlenecks often stem from Power BI repeatedly calculating the same aggregations across millions of fact table rows. Power BI aggregations combined with Fabric Warehouse materialized views eliminate this computational overhead by pre-calculating common dashboard metrics.
1-- Create warehouse materialized view for monthly sales aggregations
2CREATE MATERIALIZED VIEW monthly_sales_agg AS
3SELECT
4 region_id,
5 product_category,
6 YEAR(sale_date) as sale_year,
7 MONTH(sale_date) as sale_month,
8 SUM(revenue) as total_revenue,
9 COUNT(*) as transaction_count,
10 AVG(revenue) as avg_transaction_value
11FROM sales_fact
12WHERE sale_date >= DATEADD(YEAR, -2, GETDATE())
13GROUP BY region_id, product_category, YEAR(sale_date), MONTH(sale_date);
14
15-- Configure automatic refresh schedule
16ALTER MATERIALIZED VIEW monthly_sales_agg SET (AUTO_REFRESH = ON);Here's where it gets interesting: Power BI's query engine will automatically detect when dashboard visuals can be satisfied by your materialized view instead of scanning the underlying fact table. This happens transparently to end users, but the performance impact is dramatic for dashboards that aggregate data across time periods or business dimensions.
Alternative approaches include: Incremental refresh for large semantic models (reduces data transfer but doesn't eliminate aggregation compute), or composite models with mixed storage modes (more complex setup but allows hybrid cloud/on-premises scenarios).
When dashboards pull data from both Lakehouse Delta tables and Warehouse structured tables, Fabric Shortcuts eliminate expensive cross-engine data movement by creating unified virtual views of your data landscape. This prevents the performance penalty of federating queries across different Fabric compute engines during dashboard refresh.
What typically happens without shortcuts is that Power BI forces Fabric to orchestrate complex cross-engine queries where warehouse queries need to JOIN with lakehouse data. This coordination overhead can significantly increase dashboard refresh times. Here's how to implement shortcuts for optimal dashboard performance:
1-- Create lakehouse shortcut to warehouse dimension tables
2-- Execute in Lakehouse SQL endpoint
3CREATE SHORTCUT [warehouse_dims]
4TO 'sql-endpoint://your-workspace.datawarehouse.fabric.microsoft.com/your-warehouse/Schemas/dbo/Tables/dim_product'
5WITH (TYPE = 'SQL_ENDPOINT');
6
7-- Now query unified data without cross-engine overhead
8SELECT
9 f.sale_date,
10 d.product_name,
11 d.category,
12 SUM(f.revenue) as daily_revenue
13FROM sales_fact_delta f
14INNER JOIN warehouse_dims.dim_product d ON f.product_id = d.product_id
15WHERE f.sale_date >= DATEADD(DAY, -30, GETDATE())
16GROUP BY f.sale_date, d.product_name, d.category;
17
18-- Materialized shortcuts to eliminate cross-engine overhead
19CREATE SHORTCUT [lakehouse_warehouse_bridge]
20TO 'sql-endpoint://workspace.datawarehouse.fabric.microsoft.com/warehouse/Schemas/dbo/Tables/dim_customer'
21WITH (TYPE = 'SQL_ENDPOINT');
22
23-- Pre-aggregate across engines to minimize query-time joins
24CREATE MATERIALIZED VIEW cross_engine_agg AS
25SELECT
26 lh.customer_id,
27 lh.transaction_date,
28 SUM(lh.revenue) as lakehouse_revenue,
29 wh.customer_segment,
30 wh.lifetime_value
31FROM lakehouse.sales_fact lh
32INNER JOIN warehouse.customer_master wh ON lh.customer_id = wh.customer_id
33WHERE lh.transaction_date >= DATEADD(MONTH, -12, GETDATE())
34GROUP BY lh.customer_id, lh.transaction_date, wh.customer_segment, wh.lifetime_value;
35# Smart data movement patterns to optimize cross-engine performance
36def optimize_cross_engine_performance():
37 """Minimize data movement between Fabric engines"""
38
39 # Strategy 1: Co-locate frequently joined data
40 def colocate_related_data():
41 # Move dimension tables to lakehouse for better join performance
42 customer_dim = spark.sql("SELECT * FROM warehouse.customer_master")
43 customer_dim.write.format("delta").mode("overwrite").saveAsTable("lakehouse.customer_dim_copy")
44
45 # Create bidirectional shortcuts for critical tables
46 shortcuts_config = [
47 {'source': 'warehouse.customer_master', 'target': 'lakehouse.customer_shortcut'},
48 {'source': 'lakehouse.sales_fact', 'target': 'warehouse.sales_shortcut'}
49 ]
50
51 return shortcuts_config
52
53 # Strategy 2: Implement query result caching across engines
54 def cache_cross_engine_results():
55 cross_engine_query = """
56 SELECT
57 w.customer_segment,
58 l.product_category,
59 SUM(l.revenue) as total_revenue,
60 COUNT(*) as transaction_count
61 FROM lakehouse.sales_fact l
62 INNER JOIN warehouse.customer_master w ON l.customer_id = w.customer_id
63 WHERE l.sale_date >= CURRENT_DATE - INTERVAL 30 DAYS
64 GROUP BY w.customer_segment, l.product_category
65 """
66
67 result_df = spark.sql(cross_engine_query)
68 result_df.cache()
69 result_df.write.format("delta").mode("overwrite").saveAsTable("cache.cross_engine_summary")
70
71 return result_df
72
73optimize_cross_engine_performance()The key insight here is that shortcuts create a logical data mesh where your Power BI semantic model can treat lakehouse and warehouse data as if they exist in the same storage layer. This eliminates the query coordination overhead that typically slows down cross-engine dashboard queries.
Alternative approaches include: Data pipeline replication to consolidate data in single engine (increases storage costs and data freshness lag), DirectQuery optimization with query reduction techniques (reduces memory usage but maintains query latency), or e6data's lakehouse query engine that handles both structured and unstructured data.
Time-series dashboards consistently exhibit predictable access patterns where users focus on recent data (last 30-90 days) while occasionally drilling into historical trends. Fabric table partitioning by date, combined with proper partition elimination, ensures that dashboard queries only scan relevant data partitions.
-- Create partitioned warehouse table for time-series dashboard data
CREATE TABLE sales_fact_partitioned (
sale_id BIGINT,
customer_id INT,
product_id INT,
sale_date DATE,
revenue DECIMAL(10,2),
quantity INT
)
WITH (
CLUSTERED COLUMNSTORE INDEX,
PARTITION (sale_date RANGE RIGHT FOR VALUES (
'2023-01-01', '2023-02-01', '2023-03-01', '2023-04-01',
'2023-05-01', '2023-06-01', '2023-07-01', '2023-08-01',
'2023-09-01', '2023-10-01', '2023-11-01', '2023-12-01',
'2024-01-01', '2024-02-01', '2024-03-01', '2024-04-01'
))
);
-- For Delta tables in Lakehouse, use Hive-style partitioning
CREATE TABLE sales_fact_delta (
sale_id BIGINT,
customer_id INT,
product_id INT,
revenue DECIMAL(10,2),
quantity INT,
sale_date DATE
)
USING DELTA
PARTITIONED BY (YEAR(sale_date), MONTH(sale_date));Alternative approaches include: columnstore index optimization without partitioning (better for ad-hoc queries but less dashboard optimization), or table replication for small dimension tables (improves JOIN performance but increases storage).
Dashboard performance often degrades during business hours when hundreds of users simultaneously refresh their reports. Fabric Capacity auto-scaling prevents compute resource contention by automatically scaling compute units (CUs) based on query queue depth and CPU utilization patterns.
Here's what happens next: Fabric monitors your workspace's compute demand and automatically adds CUs when query queue times exceed your defined thresholds.
The key insight here is that auto-scaling prevents the query queueing that typically occurs when dashboard refresh jobs compete for limited compute resources. Instead of users experiencing timeouts or extended delays, auto-scaling maintains consistent dashboard response times.
Alternative approaches include: manual capacity scaling based on predictable usage patterns (more cost control but requires operational overhead), workload isolation to separate dashboard queries from ETL workloads (better resource allocation but more complex configuration), or e6data's per-vCPU scaling that eliminates capacity planning complexity while providing predictable costs and instant performance scaling without cluster management overhead.
Power BI dashboards using Direct Lake mode can experience significant performance degradation when the cache is cold, forcing fallback to DirectQuery mode which introduces substantial latency.
Direct Lake cache pre-warming ensures frequently accessed data remains memory-resident, delivering import-mode performance with real-time data freshness. When users access dashboards during peak business hours, data is already memory-resident, eliminating the cold-start latency that typically degrades user experience.
Alternative approaches include: incremental refresh policies for large semantic models (reduces refresh overhead but doesn't address cache warming), or composite models with strategic import/DirectQuery partitioning (more complex but handles mixed requirements).
Direct Lake mode can unexpectedly fall back to DirectQuery under several conditions, causing significant performance degradation and increased costs. Direct Lake fallback scenarios include exceeding SKU limits, unsupported features, memory pressure, unprocessed tables, and security constraints. Proactive monitoring and prevention strategies ensure consistent Direct Lake performance.
These fallbacks often occur silently, leaving users unaware that their dashboards have switched to slower DirectQuery mode. Implementing comprehensive monitoring and prevention strategies maintains optimal performance while providing visibility into potential issues before they impact user experience.
Alternative approaches include: manual dataset monitoring through Power BI Admin Portal (provides basic visibility but lacks automation), or capacity metrics monitoring for resource utilization (helpful but doesn't address dataset-specific issues).
For BI dashboards requiring real-time analytics on operational databases, Microsoft Fabric Mirroring provides near-zero latency data replication without impacting source system performance. Mirroring creates a read-only analytical copy of your operational database in OneLake, enabling real-time dashboards without complex ETL pipelines.
1-- Configure mirroring for real-time dashboard analytics
2-- Note: Mirroring is configured through Fabric portal, but queries run against mirrored data
3
4-- Real-time inventory dashboard analytics on mirrored operational database
5SELECT
6 p.product_category,
7 p.product_name,
8 i.current_stock_level,
9 i.reorder_point,
10 CASE
11 WHEN i.current_stock_level <= i.reorder_point THEN 'Reorder Required'
12 WHEN i.current_stock_level <= i.reorder_point * 1.5 THEN 'Low Stock Warning'
13 ELSE 'Adequate Stock'
14 END as stock_status,
15 i.last_updated
16FROM mirrored_inventory.products p
17INNER JOIN mirrored_inventory.inventory_levels i ON p.product_id = i.product_id
18WHERE i.last_updated >= DATEADD(MINUTE, -15, GETDATE())
19ORDER BY
20 CASE
21 WHEN i.current_stock_level <= i.reorder_point THEN 1
22 WHEN i.current_stock_level <= i.reorder_point * 1.5 THEN 2
23 ELSE 3
24 END,
25 p.product_category;
26
27-- Real-time customer behavior analytics for dashboards
28WITH real_time_orders AS (
29 SELECT
30 customer_id,
31 order_date,
32 order_total,
33 ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY order_date DESC) as order_rank
34 FROM mirrored_orders.orders
35 WHERE order_date >= DATEADD(HOUR, -2, GETDATE()) -- Last 2 hours
36),
37
38customer_metrics AS (
39 SELECT
40 customer_id,
41 COUNT(*) as recent_orders,
42 SUM(order_total) as recent_revenue,
43 AVG(order_total) as avg_order_value,
44 MAX(order_date) as last_order_time
45 FROM real_time_orders
46 GROUP BY customer_id
47)
48
49SELECT
50 cm.customer_id,
51 cm.recent_orders,
52 cm.recent_revenue,
53 cm.avg_order_value,
54 cm.last_order_time,
55 DATEDIFF(MINUTE, cm.last_order_time, GETDATE()) as minutes_since_last_order,
56 CASE
57 WHEN cm.recent_orders >= 3 THEN 'High Activity'
58 WHEN cm.recent_orders >= 2 THEN 'Moderate Activity'
59 ELSE 'Single Purchase'
60 END as activity_level
61FROM customer_metrics cm
62WHERE cm.recent_revenue > 100 -- Focus on high-value recent customers
63ORDER BY cm.recent_revenue DESC, cm.last_order_time DESC;Key benefits of Fabric Mirroring for BI dashboards:
Alternative approaches include: traditional ETL with scheduled refresh (higher latency but more control), DirectQuery to operational databases (real-time but impacts source performance), or composite models with strategic data combinations.
Ad-hoc analytical queries benefit enormously from Microsoft Fabric's Reflex auto-optimization capabilities, which automatically optimize data layout and statistics based on actual query patterns without manual intervention. Unlike static optimization schemes, Reflex continuously monitors query performance and adapts optimization strategies dynamically.
This proves particularly effective for exploratory data science workflows where analysts pivot between different dimensional combinations unpredictably, as Fabric automatically maintains optimal data organization.
1-- Enable auto-optimization for analytical fact table
2ALTER TABLE sales_fact_delta SET TBLPROPERTIES (
3 'delta.autoOptimize.optimizeWrite' = 'true',
4 'delta.autoOptimize.autoCompact' = 'true',
5 'delta.tuneFileSizesForRewrites' = 'true',
6 'delta.feature.allowColumnDefaults' = 'supported'
7);
8
9-- Configure adaptive statistics collection
10ALTER TABLE sales_fact_delta SET TBLPROPERTIES (
11 'delta.columnMapping.mode' = 'name',
12 'delta.enableChangeDataFeed' = 'true',
13 'delta.logRetentionDuration' = 'interval 30 days'
14);
15
16
17-- Fabric automatically detects and optimizes common query patterns
18INSERT INTO sales_fact_delta
19SELECT
20 customer_id,
21 product_id,
22 c.customer_segment,
23 p.product_category,
24 sale_date,
25 revenue,
26 quantity
27FROM staging_sales s
28JOIN customer_dim c ON s.customer_id = c.customer_id
29JOIN product_dim p ON s.product_id = p.product_id;Alternative approaches include: manual Z-ORDER clustering with periodic maintenance (provides more control but requires operational overhead), traditional table partitioning for predictable access patterns (simpler but less adaptive to changing analytical needs), or Microsoft Fabric Copilot suggestions for automated optimization recommendations.
Analytical workloads frequently require sophisticated window functions for ranking, running totals, lag analysis, and statistical calculations across large datasets. Fabric's Spark SQL optimization for window functions requires careful attention to partitioning strategies and memory management to prevent performance bottlenecks.
The critical factor for window function performance lies in aligning partition keys with analytical access patterns while managing memory allocation for intermediate shuffle operations. Fabric's cost-based optimizer can dramatically improve window function execution when provided with accurate table statistics and proper configuration.
1-- Configure session for window function optimization
2SET spark.sql.windowExec.buffer.in.memory.threshold = 4096;
3SET spark.sql.adaptive.enabled = true;
4SET spark.sql.adaptive.coalescePartitions.enabled = true;
5SET spark.sql.shuffle.partitions = 400;
6
7-- Complex analytical query with optimized window functions
8WITH customer_analytics AS (
9 SELECT
10 customer_id,
11 sale_date,
12 revenue,
13 product_category,
14 customer_segment,
15 -- Running totals and rankings
16 SUM(revenue) OVER (
17 PARTITION BY customer_id
18 ORDER BY sale_date
19 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
20 ) as customer_lifetime_value,
21
22 -- Ranking within segments
23 ROW_NUMBER() OVER (
24 PARTITION BY customer_segment, product_category
25 ORDER BY revenue DESC
26 ) as category_rank,
27
28 -- Period-over-period analysis
29 LAG(revenue, 1) OVER (
30 PARTITION BY customer_id
31 ORDER BY sale_date
32 ) as previous_revenue,
33
34 -- Statistical functions
35 PERCENTILE_CONT(0.5) OVER (
36 PARTITION BY customer_segment
37 ORDER BY revenue
38 ROWS BETWEEN 100 PRECEDING AND 100 FOLLOWING
39 ) as segment_median_revenue,
40
41 -- Advanced analytics
42 STDDEV(revenue) OVER (
43 PARTITION BY customer_id
44 ORDER BY sale_date
45 ROWS BETWEEN 30 PRECEDING AND CURRENT ROW
46 ) as revenue_volatility
47
48 FROM sales_fact_delta
49 WHERE sale_date >= '2024-01-01'
50),
51
52segment_insights AS (
53 SELECT
54 customer_segment,
55 product_category,
56 COUNT(*) as transaction_count,
57 AVG(customer_lifetime_value) as avg_clv,
58 AVG(revenue_volatility) as avg_volatility,
59 -- Complex aggregations with window context
60 COUNT(*) OVER (PARTITION BY customer_segment) as segment_size,
61 DENSE_RANK() OVER (ORDER BY AVG(customer_lifetime_value) DESC) as clv_rank
62 FROM customer_analytics
63 GROUP BY customer_segment, product_category
64)
65
66SELECT
67 customer_segment,
68 product_category,
69 transaction_count,
70 avg_clv,
71 avg_volatility,
72 segment_size,
73 clv_rank,
74 -- Calculate segment contribution
75 ROUND(100.0 * transaction_count / segment_size, 2) as category_contribution_pct
76FROM segment_insights
77WHERE clv_rank <= 10
78ORDER BY clv_rank, avg_clv DESC;Fabric automatically optimizes window function execution by analyzing partition cardinality and choosing between sort-based and hash-based algorithms. When window partitions are small enough to fit in executor memory, Fabric uses in-memory processing to avoid expensive disk spills.
Analytical workloads frequently require temporal analysis, trend identification, and period-over-period comparisons that benefit from Delta Lake's time travel capabilities. Delta time travel enables sophisticated analytical patterns like point-in-time reconstruction, data quality auditing, and historical trend analysis.
The power of time travel for analytics lies in enabling precise temporal joins and comparisons without maintaining expensive slowly changing dimension tables. Analysts can compare current state against any historical version, enabling sophisticated cohort analysis and trend identification.
What makes this particularly effective is that Delta's transaction log enables efficient time travel queries by maintaining metadata about data file changes over time. Fabric can quickly identify which files contain data for specific versions without scanning entire datasets.
Ad-hoc analytical queries often involve complex filtering and column selection patterns that can benefit significantly from advanced predicate pushdown and projection optimization. Fabric's Spark SQL optimizer can dramatically reduce I/O overhead when queries are structured to leverage columnar storage advantages and partition elimination.
The critical insight lies in structuring analytical queries to maximize predicate pushdown effectiveness while minimizing column scan overhead. This becomes particularly important for wide analytical tables with hundreds of columns where analysts typically access only small subsets of data.
When analysts structure queries to leverage these optimizations, query performance improves substantially even on large datasets.
Analytical workloads frequently require efficient deletion and update operations for scenarios like GDPR compliance, data corrections, and incremental ETL processes. Microsoft Fabric's Delta Lake MERGE operations provide ACID transaction guarantees while optimizing data lifecycle management through predicate pushdown and file-level optimization.
The critical advantage of MERGE operations lies in enabling efficient data lifecycle management that maintains query performance while handling complex update scenarios including late-arriving updates and out-of-order records.
1-- Efficient GDPR compliance with MERGE operations
2MERGE INTO customer_analytics_delta AS target
3USING (
4 SELECT
5 customer_id,
6 'DELETED' as customer_status,
7 current_timestamp() as deletion_timestamp,
8 'GDPR_REQUEST' as deletion_reason
9 FROM gdpr_deletion_requests
10 WHERE request_date >= current_date() - interval 30 days
11 AND status = 'approved'
12) AS source
13ON target.customer_id = source.customer_id
14WHEN MATCHED THEN
15 UPDATE SET
16 customer_status = source.customer_status,
17 last_modified = source.deletion_timestamp,
18 deletion_reason = source.deletion_reason,
19 pii_data = NULL, -- Remove PII fields
20 email = NULL,
21 phone = NULL
22WHEN NOT MATCHED THEN
23 INSERT (customer_id, customer_status, last_modified, deletion_reason)
24 VALUES (source.customer_id, source.customer_status, source.deletion_timestamp, source.deletion_reason);
25
26-- Optimize MERGE performance with proper clustering
27OPTIMIZE customer_analytics_delta ZORDER BY (customer_id, last_modified);
28
29-- Analytical query with efficient filtering of deleted records
30SELECT
31 customer_segment,
32 region,
33 COUNT(*) as active_customers,
34 AVG(total_revenue) as avg_customer_value,
35 SUM(total_revenue) as segment_revenue
36FROM customer_analytics_delta
37WHERE customer_status = 'active' -- Efficiently filters at storage level
38AND last_purchase_date >= current_date() - interval 365 days
39GROUP BY customer_segment, region
40ORDER BY segment_revenue DESC;Alternative approaches include: MERGE operations for complex update scenarios (provides ACID guarantees but more overhead for simple deletions), partition-based data lifecycle management using date-based retention (simpler but less granular control).
Complex analytical queries frequently involve joining large fact tables with multiple dimension tables, where default JOIN strategies can lead to unnecessary data movement and memory pressure. Fabric's Spark SQL JOIN optimization through broadcast hints and bucketing ensures that dimensional analysis queries execute efficiently without shuffle operations.
Once you've set this up, you'll find that analytical queries involving star schema JOINs execute substantially faster because dimension tables are broadcast to all executors, eliminating the shuffle overhead that typically dominates query execution time. Here's where it gets interesting: proper JOIN optimization allows Fabric to perform dimension lookups locally on each executor.
1-- Optimize star schema JOINs with broadcast hints
2SELECT /*+ BROADCAST(d, p, c) */
3 d.date_key,
4 d.month_name,
5 d.quarter,
6 p.product_name,
7 p.category,
8 c.customer_segment,
9 c.region,
10 SUM(f.revenue) as total_revenue,
11 COUNT(*) as transaction_count,
12 AVG(f.revenue) as avg_transaction_value
13FROM sales_fact_delta f
14INNER JOIN /*+ BROADCAST */ date_dim_delta d ON f.date_key = d.date_key
15INNER JOIN /*+ BROADCAST */ product_dim_delta p ON f.product_key = p.product_key
16INNER JOIN /*+ BROADCAST */ customer_dim_delta c ON f.customer_key = c.customer_key
17WHERE d.fiscal_year = 2024
18AND p.category IN ('Electronics', 'Clothing', 'Home')
19GROUP BY d.date_key, d.month_name, d.quarter, p.product_name, p.category,
20 c.customer_segment, c.region
21HAVING SUM(f.revenue) > 10000
22ORDER BY total_revenue DESC;
23
24-- Alternative: Use bucketed tables for large dimension scenarios
25CREATE TABLE sales_fact_bucketed
26USING DELTA
27CLUSTERED BY (customer_key) INTO 32 BUCKETS
28AS SELECT * FROM sales_fact_delta;
29
30CREATE TABLE customer_dim_bucketed
31USING DELTA
32CLUSTERED BY (customer_key) INTO 32 BUCKETS
33AS SELECT * FROM customer_dim_delta;Alternative approaches include: sort-merge JOIN optimization for large table combinations (handles bigger datasets but requires sorted data), or denormalized fact table designs to avoid JOINs entirely (faster queries but increased storage and update complexity).
Microsoft Fabric KQL Database is specifically optimized for time-series and telemetry data analytics, providing superior performance for complex analytical queries, log analytics, IoT data, and operational monitoring use cases compared to traditional SQL engines.
Key benefits of KQL Database for advanced analytics:
Alternative approaches include: Spark SQL with Delta tables for time-series (more general but less optimized), traditional data warehouses with time-series extensions (familiar but less performant), or specialized time-series databases (optimal but requires separate infrastructure).
Real-time ETL pipelines often struggle with late-arriving data and memory accumulation in stateful operations like window aggregations and stream-to-stream JOINs. Structured Streaming watermarks enable efficient state management by defining how long to wait for late data before finalizing aggregation results.
1# Implement watermarked streaming aggregations for ETL pipeline
2from pyspark.sql import SparkSession
3from pyspark.sql.functions import *
4from pyspark.sql.types import *
5
6# Define schema for streaming data
7sales_schema = StructType([
8 StructField("transaction_id", StringType(), True),
9 StructField("customer_id", StringType(), True),
10 StructField("product_id", StringType(), True),
11 StructField("revenue", DecimalType(10,2), True),
12 StructField("event_timestamp", TimestampType(), True)
13])
14
15# Read streaming data with watermark configuration
16streaming_sales = spark.readStream \
17 .format("kafka") \
18 .option("kafka.bootstrap.servers", "your-kafka-cluster") \
19 .option("subscribe", "sales-topic") \
20 .load() \
21 .select(from_json(col("value").cast("string"), sales_schema).alias("data")) \
22 .select("data.*") \
23 .withWatermark("event_timestamp", "10 minutes")
24
25# Perform windowed aggregations with late data handling
26windowed_sales = streaming_sales \
27 .groupBy(
28 window(col("event_timestamp"), "5 minutes", "1 minute"),
29 col("product_id")
30 ) \
31 .agg(
32 sum("revenue").alias("total_revenue"),
33 count("*").alias("transaction_count"),
34 avg("revenue").alias("avg_revenue")
35 ) \
36 .select(
37 col("window.start").alias("window_start"),
38 col("window.end").alias("window_end"),
39 col("product_id"),
40 col("total_revenue"),
41 col("transaction_count"),
42 col("avg_revenue")
43 )
44
45# Write results to Delta table with watermark-based state cleanup
46query = windowed_sales.writeStream \
47 .format("delta") \
48 .option("checkpointLocation", "/lakehouse/checkpoints/windowed_sales") \
49 .outputMode("append") \
50 .trigger(processingTime="30 seconds") \
51 .toTable("real_time_sales_agg")What makes this particularly effective is that watermarks allow Spark to automatically clean up old state information while ensuring that late-arriving data within the watermark threshold is still processed correctly. This prevents the memory leaks that commonly cause streaming ETL job failures after days or weeks of operation.
Alternative approaches include: batch processing with scheduled intervals (simpler state management but higher latency), stateless streaming without aggregations (eliminates state issues but limits analytical capabilities).
Complex ETL workflows often involve multiple dependent data transformation stages where sequential execution and resource contention can significantly impact overall pipeline throughput. Fabric Data Pipeline parallel execution and dependency management optimize end-to-end ETL performance by running independent transformation stages concurrently.
Once you've set this up, you'll immediately see ETL pipeline execution times reduce substantially because independent data transformations run in parallel instead of waiting for sequential completion.
Parallel execution requires careful dependency management where dimension table extracts can run simultaneously while fact table transformations wait for dimension data availability. This optimization is particularly effective for ETL pipelines that process multiple source systems with independent extraction schedules.
Alternative approaches include: notebook-based ETL orchestration with manual parallelization (more flexible but requires custom orchestration code), external workflow tools like Apache Airflow integration (better for complex dependencies but increases operational complexity).
ETL workloads exhibit varying resource requirements where some stages need high CPU for transformations while others require significant memory for large JOINs or aggregations. Dynamic Spark resource allocation in Fabric ensures that ETL jobs automatically scale executor resources based on workload characteristics without manual tuning.
You'll find that dynamic allocation significantly improves ETL pipeline efficiency because Spark automatically adds executors during data-intensive operations and releases them during lighter processing stages. What typically happens is that ETL pipelines have distinct phases with different resource needs that benefit from automatic scaling.
1# Configure dynamic resource allocation for ETL workloads with memory optimization
2spark.conf.set("spark.dynamicAllocation.enabled", "true")
3spark.conf.set("spark.dynamicAllocation.minExecutors", "2")
4spark.conf.set("spark.dynamicAllocation.maxExecutors", "20")
5spark.conf.set("spark.dynamicAllocation.initialExecutors", "4")
6spark.conf.set("spark.dynamicAllocation.executorIdleTimeout", "60s")
7spark.conf.set("spark.dynamicAllocation.cachedExecutorIdleTimeout", "300s")
8
9# Memory optimization for large datasets to prevent OOM errors
10spark.conf.set("spark.executor.memory", "16g")
11spark.conf.set("spark.executor.memoryOffHeapEnabled", "true")
12spark.conf.set("spark.executor.memoryOffHeapSize", "4g")
13spark.conf.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "64MB")
14spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "2")
15spark.conf.set("spark.kryoserializer.buffer.max", "2047m")
16
17# Example ETL job with varying resource requirements
18def process_sales_etl():
19 # Phase 1: Data extraction (low resource needs)
20 raw_sales = spark.read \
21 .format("jdbc") \
22 .option("url", "jdbc:sqlserver://source-db") \
23 .option("query", """
24 SELECT * FROM sales_transactions
25 WHERE transaction_date >= DATEADD(DAY, -1, GETDATE())
26 """) \
27 .load()
28
29 # Phase 2: Data enrichment (high memory for JOINs)
30 customer_dim = spark.read.table("customer_dimension")
31 product_dim = spark.read.table("product_dimension")
32
33 enriched_sales = raw_sales \
34 .join(customer_dim, "customer_id") \
35 .join(product_dim, "product_id") \
36 .withColumn("profit_margin", col("revenue") - col("cost")) \
37 .withColumn("customer_lifetime_value",
38 expr("SUM(revenue) OVER (PARTITION BY customer_id)"))
39
40 # Phase 3: Aggregation and output (moderate resources)
41 daily_summary = enriched_sales \
42 .groupBy("transaction_date", "product_category", "customer_segment") \
43 .agg(
44 sum("revenue").alias("total_revenue"),
45 sum("profit_margin").alias("total_profit"),
46 count("*").alias("transaction_count"),
47 countDistinct("customer_id").alias("unique_customers")
48 )
49
50 # Write with optimized partitioning
51 daily_summary.write \
52 .format("delta") \
53 .mode("overwrite") \
54 .partitionBy("transaction_date") \
55 .option("overwriteSchema", "true") \
56 .saveAsTable("daily_sales_summary")
57
58process_sales_etl()Alternative approaches include: fixed cluster sizing based on peak resource requirements (more predictable costs but potential resource waste), or job-specific resource tuning for each ETL stage (optimal performance but requires extensive configuration management).
ETL pipelines frequently generate numerous small files that dramatically degrade query performance and increase storage overhead. Small file consolidation through strategic OPTIMIZE operations and write configurations ensures optimal file sizes for analytical workloads while minimizing storage metadata overhead.
The fundamental performance issue with small files lies in the overhead of opening and closing multiple files during query execution. When fact tables contain thousands of small Parquet files instead of optimally-sized 128MB-1GB files, query performance can degrade due to I/O overhead and metadata processing costs.
ETL pipelines continuously write new data versions to Delta tables, creating multiple file versions that accumulate over time and dramatically increase storage costs. VACUUM operations clean up obsolete data files while preserving time travel capabilities, providing critical storage cost optimization for enterprise data platforms.
The fundamental insight here is that Delta Lake maintains multiple data file versions to support time travel and transactional features, but these accumulated versions can increase storage costs if left unmaintained. Strategic VACUUM operations balance storage efficiency with operational time travel requirements, ensuring cost-effective data lifecycle management.
1-- Configure retention policies for different table types
2VACUUM sales_fact_delta RETAIN 168 HOURS; -- 7 days for production tables
3VACUUM customer_dimension RETAIN 72 HOURS; -- 3 days for dimensions
4VACUUM customer_historical_delta RETAIN 720 HOURS; -- 30 days for compliance
5
6# Automated VACUUM operations for storage optimization
7def configure_vacuum_policies():
8 """Configure VACUUM retention policies for different table types"""
9
10 vacuum_policies = {
11 'production_tables': {'retention_hours': 168, 'description': '7 days for production'},
12 'dimension_tables': {'retention_hours': 72, 'description': '3 days for dimensions'},
13 'compliance_tables': {'retention_hours': 720, 'description': '30 days for compliance'},
14 'staging_tables': {'retention_hours': 24, 'description': '1 day for staging'}
15 }
16
17 print("VACUUM Retention Policies:")
18 for table_type, policy in vacuum_policies.items():
19 print(f" {table_type}: {policy['retention_hours']} hours ({policy['description']})")
20
21 return vacuum_policies
22
23# Configure VACUUM policies
24vacuum_config = configure_vacuum_policies()By implementing tiered retention policies based on table usage patterns, organizations can achieve substantial storage cost reductions while maintaining necessary time travel capabilities for operational and compliance needs.
Alternative approaches include: manual VACUUM scheduling during maintenance windows (more control but requires operational overhead), storage lifecycle policies with automated archival (comprehensive but more complex).
Microsoft Fabric Eventstream provides native real-time data ingestion and processing capabilities optimized for high-velocity ETL workloads. Eventstream integrates seamlessly with KQL Database and Lakehouse for both real-time and batch analytics pipelines.
Key benefits of Fabric Eventstream for ETL:
Alternative approaches include: Apache Kafka with custom streaming applications (more control but higher operational complexity), Azure Event Hubs with separate processing engines (lower cost but requires integration work), or traditional batch ETL with scheduled intervals (simpler but higher latency).
Even after implementing Auto Optimize, Adaptive Query Execution, capacity auto-scaling, Mirroring, Eventstream, and KQL Database optimizations, some BI/SQL workloads still face performance bottlenecks when scaling beyond Fabric's architectural constraints. That's where e6data comes in.
e6data is a decentralized, Kubernetes-native lakehouse compute engine delivering 10x faster query performance with 60% lower compute costs through per-vCPU billing and zero data movement. It runs directly on existing data formats (Delta/Iceberg/Hudi, Parquet, CSV, JSON), requiring no migration or rewrites. Teams often keep their existing Fabric platform for development workflows while offloading performance-critical queries to e6data for sub-second latency and 1000+ QPS concurrency.
Key benefits of the e6data approach:
Start a free trial of e6data and see performance comparison on your own workloads. Use our cost calculator to estimate potential gains.
.svg)
.svg)
.svg)
.png)

.svg)
.svg)
.svg)
.svg)
.svg)