.svg)
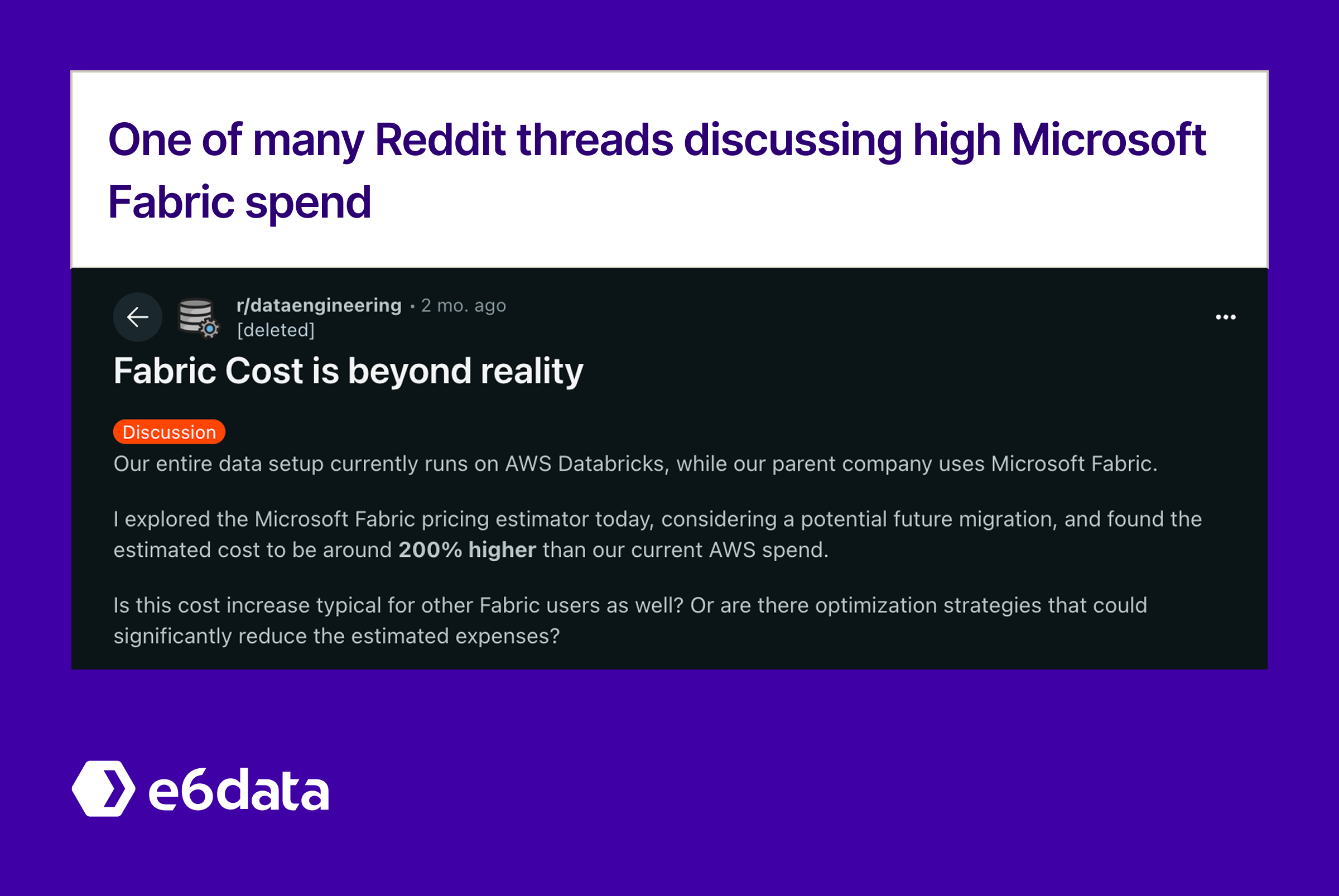
Microsoft Fabric’s unified analytics platform can simplify your data estate, but without strong cost governance, that flexibility can quickly turn into budget overruns. Enterprises adopting Fabric’s integrated approach to data engineering, analytics, and AI are discovering that its consumption-based pricing introduces complex cost dynamics that require specialized optimization strategies.
Common pain points include:
Unlike traditional analytics platforms with fixed licensing, Fabric’s pay-as-you-go model means every query, every data movement, and every storage decision directly hits your bottom line.
This playbook offers data engineering teams tactical, measurable approaches to optimize Fabric costs across three critical workload categories. Each tactic includes code examples, real-world scenarios (with metrics), and proven alternatives that have delivered substantial cost reductions in enterprise environments. Use it as a practical cost-optimization handbook for your Fabric workloads.
Before diving into optimizations, it’s important to monitor key cost indicators that signal inefficiencies. The table below outlines cost “yardsticks” and warning thresholds and trigger points for investigation, along with examples of what to monitor:
Optimizations must be tailored to your Fabric workload patterns. Each workload type has distinct cost drivers and opportunities:
Characteristics: High-frequency, predictable analytical queries (e.g. executive dashboards).
Primary Cost Drivers: Power BI Premium capacity usage, semantic model size, query processing times.
Optimization Focus: Caching strategies, efficient model design, incremental refresh patterns.
Characteristics: Exploratory queries with unpredictable resource needs and varying complexity (e.g. data science notebooks).
Primary Cost Drivers: Spark compute session runtime, OneLake data scan volume, SQL endpoint query costs.
Optimization Focus: Query tuning (pruning data scans), data partitioning/clustering, session management (auto-pause/terminate).
Characteristics: High-volume data movement and real-time processing (e.g. pipelines and event streams).
Primary Cost Drivers: Data Factory pipeline execution CUs, Spark cluster utilization (idle vs peak), streaming ingestion and transformation costs.
Optimization Focus: Pipeline efficiency (batching, parallelism), cluster autoscaling, data compression and format optimization.
For BI dashboards (typically Power BI-driven), the biggest savings come from optimizing datasets and refreshes to reduce load on Premium capacities. The tactics below focus on semantic model efficiency and smarter use of compute for frequent dashboard queries.
A major healthcare network’s patient analytics dashboard was overloading their Power BI Premium capacity (CPU ~95% at peak). The dashboard queried a 500 GB fact table (2.8 billion rows) on every load, causing executive reports to time out and slicers to take 15–30 seconds.
The team addressed this by implementing user-defined aggregations in the Power BI semantic model to pre-summarize common query results. The DAX snippet below creates a monthly aggregation table (PatientMetrics_Monthly) with total visits, average length of stay, and total revenue by Year, Month, and Department. This pre-aggregated table is added to the model and will answer high-level queries without scanning the entire fact table:
1-- Define an aggregation table at Month level
2DEFINE TABLE PatientMetrics_Monthly =
3SUMMARIZECOLUMNS(
4 'Calendar'[Year],
5 'Calendar'[Month],
6 'Department'[DepartmentName],
7 "TotalVisits", SUM('FactPatientVisits'[VisitCount]),
8 "AvgLengthOfStay", AVERAGE('FactPatientVisits'[LengthOfStay]),
9 "TotalRevenue", SUM('FactPatientVisits'[Revenue])
10)
11
12-- Evaluate and add the aggregation table to the model
13EVALUATE PatientMetrics_MonthlyAlternatives:
A retail analytics team was performing full dataset refreshes every hour for their sales dashboards, refreshing 12 large Power BI datasets, each consuming ~850 capacity units (CUs) per refresh. During Black Friday weekend, this aggressive schedule drove refresh costs to about $2,400 per day, and many refresh attempts timed out under the load.
They implemented an incremental refresh policy to only process new or changed data instead of fully reloading everything. The JSON snippet below illustrates an example incremental refresh configuration: it refreshes data at an hourly grain for the last 10 hours, maintains a rolling 90-day window of historical data, and uses detectDataChanges to only load partitions where source data has changed:
1{
2 "refreshPolicy": {
3 "type": "incremental",
4 "incrementalGranularity": "Hour",
5 "incrementalPeriods": 10,
6 "rollingWindowGranularity": "Day",
7 "rollingWindowPeriods": 90,
8 "detectDataChanges": true,
9 "sourceExpressionFilter": "DateTime[Date] >= DateTime.From(RangeStart) and DateTime[Date] < DateTime.From(RangeEnd)"
10 }
11}Alternatives:
A financial services firm had a compliance dashboard serving ~2,500 users across different regions and clearance levels. Power BI Row-Level Security (RLS) ensured each user only saw permitted data (filtered by geography and role). However, without optimization, every query had to re-evaluate the RLS filters for each user, leading to 8–12 second dashboard load times and high Premium CPU utilization.
They optimized RLS by caching the user-to-region mapping and leveraging it in the filter logic. Specifically, they created a table-valued function in the data source that returns the allowed regions for a given user, and then used that in the Power BI model’s RLS rule. This way, the expensive security lookup is done once and reused.
1-- SQL: Table-valued function to get allowed regions for a user
2CREATE FUNCTION Security.GetUserRegions(@UserPrincipalName NVARCHAR(256))
3RETURNS TABLE
4AS
5RETURN
6(
7 SELECT DISTINCT ur.RegionCode
8 FROM dbo.UserRegions ur
9 JOIN dbo.Users u ON ur.UserId = u.UserId
10 WHERE u.UserPrincipalName = @UserPrincipalName
11 AND ur.IsActive = 1
12 AND ur.ExpiryDate > GETDATE()
13);
14
15-- Power BI RLS DAX rule using the function
16[RegionCode] IN VALUES( Security.GetUserRegions( USERNAME() ) )Alternatives:
TREATAS or pre-aggregated lookup tables) to improve the query plan and reduce overhead.One data engineering team maintained ~15 development and testing workspaces in Fabric on a dedicated Premium capacity, running 24/7. Off-hours (nights & weekends), these environments sat idle but still consumed capacity in wasted cost with zero user activity.
The solution was to implement automatic workspace pausing for non-production workspaces during idle periods. They scheduled a PowerShell script (using Azure Automation) that checks each dev/test workspace’s last activity, and if a workspace has been idle for over 2 hours, it suspends the workspace.
1# PowerShell: Auto-pause idle workspaces
2$workspaces = @("Dev-Analytics", "Test-Reports", "Staging-Dashboards")
3foreach ($ws in $workspaces) {
4 $usage = Get-PowerBIWorkspaceUsage -WorkspaceId $ws -Days 1
5 if ($usage.LastActivity -lt (Get-Date).AddHours(-2)) {
6 Suspend-PowerBIWorkspace -WorkspaceId $ws
7 Write-Host "Paused workspace: $ws due to inactivity"
8 }
9}Alternatives:
A team had 8 interdependent Power BI dataflows feeding their supply chain dashboards. Originally, all 8 dataflows were set to refresh simultaneously at 6:00 AM daily. This caused a huge spike in load (Premium capacity hit ~98% CPU) and frequent refresh failures (3–4 failures per week) due to contention when all dataflows ran at once.
The team redesigned the refresh schedule to stagger these dataflows and chain them by dependencies. Critical dataflows now refresh first, and downstream dataflows refresh sequentially after their prerequisites complete.
1{
2 "dataflowRefreshSchedule": {
3 "sourceDataflows": [
4 {
5 "name": "Suppliers_Master",
6 "schedule": "0 5 * * *",
7 "priority": 1,
8 "dependencies": []
9 },
10 {
11 "name": "Inventory_Transactions",
12 "schedule": "0 6 * * *",
13 "priority": 2,
14 "dependencies": ["Suppliers_Master"]
15 },
16 {
17 "name": "Production_Metrics",
18 "schedule": "0 7 * * *",
19 "priority": 3,
20 "dependencies": ["Inventory_Transactions"]
21 }
22 ]
23 }
24}Alternatives:
An analytics team was ingesting a high volume of sales data (≈18 GB/day) into Power BI models in Import mode. This led to large dataset sizes (and Premium storage costs around $3,200/month) and long refresh times (~45 minutes). The model served dual purposes: real-time inventory lookups and historical sales trend analysis, all in one dataset, causing both performance and cost issues due to the mixed workload.
They re-architected the Power BI dataset as a composite model, splitting data by freshness: current data stays in DirectQuery (no import), while historical data remains imported for fast analysis. In practice, they set up the fact table with partitions or logic by date.
1-- Pseudo-code: determine storage mode by year (current year = DirectQuery, others = Import)
2EVALUATE
3ADDCOLUMNS(
4 SUMMARIZE('Sales', 'Date'[Year], 'Date'[Month]),
5 "StorageMode",
6 IF(
7 'Date'[Year] = YEAR(TODAY()),
8 "DirectQuery", -- Current year data via DirectQuery for real-time
9 "Import" -- Historical data cached in memory
10 )
11)
12
13-- Define relationships appropriate for DirectQuery (one cross-filter, one single to control join behavior)
14DEFINE
15RELATIONSHIP('Sales'[ProductID], 'Products'[ProductID], MANY_TO_ONE, CROSSFILTER_BOTH)
16RELATIONSHIP('Sales'[DateKey], 'Calendar'[DateKey], MANY_TO_ONE, CROSSFILTER_SINGLE)Alternatives:
Ad-hoc analytics workloads (like interactive SQL queries, notebooks, or experiments on large datasets) benefit from optimizing data layout and managing compute resources on-the-fly. The following tactics aim to minimize data scanned and eliminate idle compute time, making exploratory analysis in Fabric faster and cheaper.
A financial analytics team was querying a 2.5 TB OneLake Delta table of transactions for exploratory analysis. Because the data wasn’t organized for their query patterns, each query ended up scanning almost the entire dataset, consuming ~450–600 CUs and taking 15–25 minutes. The heavy cost and slow turnaround made analysts hesitant to run complex queries frequently.
They tackled this by optimizing the physical layout of the Delta Lake data using Z-order clustering and partitioning. In practice, this meant clustering data files on the most commonly filtered fields and partitioning the data by date to prune unnecessary data.
1-- Physically cluster the table files by frequently filtered columns
2OPTIMIZE financial.transactions
3ZORDER BY (transaction_date, account_type, amount_range, region_code);
4
5-- Compute fresh statistics to aid the query optimizer
6ANALYZE TABLE financial.transactions COMPUTE STATISTICS;
7
8-- (Optional) Repartition data by date for pruning
9CREATE TABLE financial.transactions_optimized
10USING DELTA
11PARTITIONED BY (year, month)
12LOCATION 'abfss://analytics@storage.dfs.core.windows.net/transactions'
13TBLPROPERTIES (
14 'delta.autoOptimize.optimizeWrite' = 'true',
15 'delta.autoOptimize.autoCompact' = 'true'
16)
17AS SELECT *
18FROM financial.transactions;Alternatives:
An analytics team stored 18 months of customer behavior data as 847,000 small JSON files in OneLake, causing analytical queries to scan excessive file metadata and consume 320-480 CUs per query. Query planning alone took 2-5 minutes before execution started.
The team implemented a file consolidation and format optimization strategy. They converted the scattered JSON files into larger columnar files (Parquet/Delta) with appropriate partitioning to improve query efficiency.
1# Consolidate small files into optimized Parquet format
2from delta.tables import DeltaTable
3import pyspark.sql.functions as F
4
5def optimize_file_layout(source_path, target_path, partition_columns):
6 # Read fragmented data and optimize layout
7 df = spark.read.option("multiline", "true").json(source_path)
8
9 # Add partitioning columns for efficient filtering
10 df_with_partitions = df.withColumn("year", F.year(F.col("timestamp"))) \
11 .withColumn("month", F.month(F.col("timestamp"))) \
12 .withColumn("customer_segment",
13 F.when(F.col("total_purchases") > 1000, "high_value")
14 .when(F.col("total_purchases") > 100, "medium_value")
15 .otherwise("low_value"))
16
17 # Write as optimized Delta table with proper file sizing
18 df_with_partitions.write \
19 .format("delta") \
20 .mode("overwrite") \
21 .partitionBy("year", "month", "customer_segment") \
22 .option("delta.autoOptimize.optimizeWrite", "true") \
23 .option("delta.targetFileSize", "134217728") # 128MB target file size \
24 .save(target_path)
25
26# Execute optimization
27optimize_file_layout(
28 "abfss://raw@storage.dfs.core.windows.net/customer_behavior/json/",
29 "abfss://analytics@storage.dfs.core.windows.net/customer_behavior_optimized/",
30 ["year", "month", "customer_segment"]
31)Alternatives:
A business intelligence team was repeatedly analyzing the same customer segments and time periods, with each analyst re-scanning 800GB of source data for overlapping analyses. Daily analytical workloads consumed 2,800 CUs with 65% of queries accessing previously computed intermediate results.
To address this, the team built an intelligent caching layer on top of Spark. Instead of relying solely on manual caching, they created a mechanism to automatically cache and reuse intermediate results for frequent query patterns.
1# Implement intelligent caching with cache lifecycle management
2from pyspark.sql import DataFrame
3from pyspark.storagelevel import StorageLevel
4import hashlib
5
6class AnalyticsCacheManager:
7 def __init__(self):
8 self.cache_registry = {}
9 self.cache_hits = 0
10 self.cache_misses = 0
11
12 def get_cache_key(self, query: str, parameters: dict) -> str:
13 # Create deterministic cache key
14 cache_input = f"{query}_{sorted(parameters.items())}"
15 return hashlib.md5(cache_input.encode()).hexdigest()
16
17 def get_or_compute(self, cache_key: str, compute_func, cache_level=StorageLevel.MEMORY_AND_DISK_SER):
18 if cache_key in self.cache_registry:
19 self.cache_hits += 1
20 print(f"Cache HIT for {cache_key[:8]}...")
21 return self.cache_registry[cache_key]
22
23 self.cache_misses += 1
24 print(f"Cache MISS for {cache_key[:8]}... Computing...")
25
26 # Compute and cache result
27 result = compute_func()
28 result.cache()
29 result.persist(cache_level)
30
31 self.cache_registry[cache_key] = result
32 return result
33
34 def get_cache_stats(self):
35 hit_rate = self.cache_hits / (self.cache_hits + self.cache_misses) * 100
36 return f"Cache hit rate: {hit_rate:.1f}% ({self.cache_hits} hits, {self.cache_misses} misses)"
37
38# Usage example for customer segmentation analysis
39cache_manager = AnalyticsCacheManager()
40
41def compute_customer_segments(date_range, region):
42 return spark.sql(f"""
43 SELECT customer_id,
44 SUM(purchase_amount) as total_spent,
45 COUNT(*) as transaction_count,
46 CASE
47 WHEN SUM(purchase_amount) > 5000 THEN 'Premium'
48 WHEN SUM(purchase_amount) > 1000 THEN 'Standard'
49 ELSE 'Basic'
50 END as segment
51 FROM transactions
52 WHERE transaction_date BETWEEN '{date_range[0]}' AND '{date_range[1]}'
53 AND region = '{region}'
54 GROUP BY customer_id
55 """)In this approach:
Alternatives:
A financial modeling team had unpredictable analytical workloads ranging from simple aggregations requiring 2 cores to complex ML training needing 200+ cores. Static cluster provisioning for peak capacity resulted in $6,200 monthly costs with 25% average utilization and frequent resource waste.
The team enabled dynamic cluster scaling (Spark Dynamic Allocation) so that compute resources would automatically scale up or down based on current workload. They set a broad range for executors, from a minimum of 2 up to a maximum of 200, and tuned Spark’s thresholds to make scaling decisions quickly. The configuration snippet below highlights this:
1# Configure adaptive Spark cluster scaling
2spark.conf.set("spark.dynamicAllocation.enabled", "true")
3spark.conf.set("spark.dynamicAllocation.minExecutors", "2")
4spark.conf.set("spark.dynamicAllocation.maxExecutors", "200")
5spark.conf.set("spark.dynamicAllocation.initialExecutors", "10")
6
7# Advanced scaling configuration
8spark.conf.set("spark.dynamicAllocation.executorIdleTimeout", "60s")
9spark.conf.set("spark.dynamicAllocation.cachedExecutorIdleTimeout", "300s")
10spark.conf.set("spark.dynamicAllocation.schedulerBacklogTimeout", "1s")
11spark.conf.set("spark.dynamicAllocation.sustainedSchedulerBacklogTimeout", "5s")
12
13# Custom resource allocation based on workload patterns
14class WorkloadBasedScaling:
15 def __init__(self):
16 self.workload_profiles = {
17 "simple_aggregation": {"min_executors": 2, "max_executors": 10, "target_executor_cores": 4},
18 "ml_training": {"min_executors": 20, "max_executors": 200, "target_executor_cores": 8},
19 "data_exploration": {"min_executors": 5, "max_executors": 50, "target_executor_cores": 4},
20 "report_generation": {"min_executors": 8, "max_executors": 40, "target_executor_cores": 4}
21 }
22
23 def configure_for_workload(self, workload_type: str):
24 if workload_type not in self.workload_profiles:
25 print(f"Unknown workload type: {workload_type}")
26 return
27
28 profile = self.workload_profiles[workload_type]
29
30 spark.conf.set("spark.dynamicAllocation.minExecutors", str(profile["min_executors"]))
31 spark.conf.set("spark.dynamicAllocation.maxExecutors", str(profile["max_executors"]))
32 spark.conf.set("spark.executor.cores", str(profile["target_executor_cores"]))
33
34 print(f"Configured cluster for {workload_type}: {profile}")
35
36# Usage with automatic workload detection
37scaler = WorkloadBasedScaling()
38
39def execute_with_optimal_scaling(query: str, estimated_data_size_gb: float):
40 # Simple heuristic for workload classification
41 if "train" in query.lower() or "ml" in query.lower():
42 workload = "ml_training"
43 elif estimated_data_size_gb < 10:
44 workload = "simple_aggregation"
45 elif "GROUP BY" in query and "JOIN" in query:
46 workload = "data_exploration"
47 else:
48 workload = "report_generation"
49
50 scaler.configure_for_workload(workload)
51 return spark.sql(query)Alternatives:
An analytics team was repeatedly computing the same customer lifetime value calculations and segmentation logic across multiple reports and dashboards. Each calculation required scanning 1.2TB of historical data, with 85% of queries containing overlapping analytical logic consuming redundant compute resources.
To eliminate this duplication, they introduced query result materialization for common expensive computations. In practice, this means creating materialized views or cached tables that store the results of these computations, so that downstream queries can simply read the precomputed results. First, they created materialized views in their Lakehouse (on Delta tables) for the heavy queries.
1-- Create materialized views for common analytical patterns
2CREATE MATERIALIZED VIEW customer_lifetime_analytics
3USING DELTA
4LOCATION 'abfss://analytics@storage.dfs.core.windows.net/materialized/clv_analytics'
5AS
6SELECT
7 customer_id,
8 registration_date,
9 DATEDIFF(CURRENT_DATE, registration_date) as customer_age_days,
10 SUM(purchase_amount) as total_lifetime_value,
11 COUNT(DISTINCT transaction_date) as purchase_frequency,
12 AVG(purchase_amount) as avg_order_value,
13 MAX(transaction_date) as last_purchase_date,
14 DATEDIFF(CURRENT_DATE, MAX(transaction_date)) as days_since_last_purchase,
15 CASE
16 WHEN SUM(purchase_amount) > 10000 AND COUNT(*) > 50 THEN 'VIP'
17 WHEN SUM(purchase_amount) > 5000 AND COUNT(*) > 20 THEN 'High Value'
18 WHEN SUM(purchase_amount) > 1000 AND COUNT(*) > 5 THEN 'Regular'
19 ELSE 'Occasional'
20 END as customer_segment,
21 PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY purchase_amount) as median_order_value
22FROM customer_transactions
23WHERE transaction_date >= '2022-01-01'
24GROUP BY customer_id, registration_date;
25
26-- Implement incremental refresh for materialized views
27REFRESH MATERIALIZED VIEW customer_lifetime_analytics
28WHERE transaction_date >= CURRENT_DATE - INTERVAL 1 DAY;Next, they developed a lightweight Query Materialization Manager in Python to keep track of materialized queries and their dependencies. The idea was to programmatically register common query patterns, so they could ensure those are materialized and refreshed when source data changes.
Alternatives:
ETL (Extract-Transform-Load) and streaming workloads often involve constant data movement and long-running processes. Cost optimization here focuses on improving batch efficiency, avoiding unnecessary compute during low loads, and leveraging scaling to handle throughput spikes.
A data engineering team was running 240 separate Data Factory pipelines for daily shipment processing, with each pipeline handling 50-200 records individually. Pipeline overhead costs reached $4,100 monthly, with 85% of execution time spent on pipeline initialization rather than data processing.
The team refactored their pipelines to batch process data in larger chunks and drastically reduce the number of pipeline invocations. They combined those 240 daily runs into about a dozen runs by increasing batch sizes to ~10,000 records and processing multiple shipments in one go.
1{
2 "pipeline": {
3 "name": "optimized_shipment_processing",
4 "parameters": {
5 "batchSize": "10000",
6 "maxParallelism": "8",
7 "retryPolicy": {
8 "count": 3,
9 "intervalInSeconds": 30
10 }
11 },
12 "activities": [
13 {
14 "name": "BatchShipmentData",
15 "type": "Copy",
16 "inputs": [
17 {
18 "referenceName": "shipment_source",
19 "type": "DatasetReference"
20 }
21 ],
22 "typeProperties": {
23 "source": {
24 "type": "SqlServerSource",
25 "sqlReaderQuery": "SELECT * FROM shipments WHERE processed_date = '@{formatDateTime(utcnow(), 'yyyy-MM-dd')}'"
26 },
27 "sink": {
28 "type": "DeltaLakeSink",
29 "writeBatchSize": 10000,
30 "writeBatchTimeout": "00:30:00"
31 },
32 "enableStaging": true,
33 "stagingSettings": {
34 "linkedServiceName": "AzureBlobStorage",
35 "path": "staging/shipments"
36 }
37 }
38 }
39 ]
40 }
41}Alternatives:
A data engineering team was ingesting 2.8 million transaction records daily through streaming pipelines, with each micro-batch performing individual MERGE operations causing excessive file fragmentation and compute overhead. Streaming costs reached $3,600 monthly with increasing latency issues.
The team optimized the streaming pipeline by batching up merges and introducing periodic compaction. Instead of merging every single micro-batch (which might be a few hundred records), they accumulated a few micro-batches and merged them in one go, and regularly ran OPTIMIZE to combine small files.
1# Optimized streaming Delta merge with batching and compaction
2from delta.tables import DeltaTable
3import pyspark.sql.functions as F
4from pyspark.sql.types import StructType, StructField, StringType, TimestampType, DoubleType
5
6def optimized_streaming_merge(spark, source_stream, target_table_path):
7 # Configure streaming batch parameters for efficiency
8 streaming_query = (source_stream
9 .writeStream
10 .format("delta")
11 .outputMode("append")
12 .trigger(processingTime='2 minutes') # Batch micro-batches for efficiency
13 .option("checkpointLocation", f"{target_table_path}/_checkpoints/streaming")
14 .option("mergeSchema", "true")
15 .foreachBatch(lambda batch_df, epoch_id: process_streaming_batch(batch_df, epoch_id, target_table_path))
16 .start()
17 )
18
19 return streaming_query
20
21def process_streaming_batch(batch_df, epoch_id, target_table_path):
22 print(f"Processing batch {epoch_id} with {batch_df.count()} records")
23
24 # Load target Delta table
25 target_table = DeltaTable.forPath(spark, target_table_path)
26
27 # Optimize merge conditions for performance
28 merge_condition = """
29 target.transaction_id = source.transaction_id AND
30 target.account_id = source.account_id
31 """
32
33 # Execute optimized merge with batch grouping
34 (target_table.alias("target")
35 .merge(batch_df.alias("source"), merge_condition)
36 .whenMatchedUpdate(set={
37 "amount": F.col("source.amount"),
38 "status": F.col("source.status"),
39 "updated_timestamp": F.current_timestamp()
40 })
41 .whenNotMatchedInsert(values={
42 "transaction_id": F.col("source.transaction_id"),
43 "account_id": F.col("source.account_id"),
44 "amount": F.col("source.amount"),
45 "status": F.col("source.status"),
46 "created_timestamp": F.current_timestamp(),
47 "updated_timestamp": F.current_timestamp()
48 })
49 .execute()
50 )
51
52 # Trigger compaction for every 10th batch to manage file size
53 if epoch_id % 10 == 0:
54 spark.sql(f"OPTIMIZE '{target_table_path}' ZORDER BY (account_id, transaction_date)")
55 print(f"Triggered optimization for batch {epoch_id}")
56
57# Streaming source configuration with optimized batching
58streaming_source = (spark
59 .readStream
60 .format("kafka")
61 .option("kafka.bootstrap.servers", "localhost:9092")
62 .option("subscribe", "financial_transactions")
63 .option("startingOffsets", "latest")
64 .option("maxOffsetsPerTrigger", "50000") # Control batch size
65 .load()
66)Alternatives:
A data engineering team was running 6 dedicated Spark clusters 24/7 for varying ETL workloads, resulting in $8,900 monthly costs with 35% average utilization. Peak processing periods required maximum capacity while off-hours left clusters mostly idle.
The team switched to using Spark compute pools with autoscaling in Fabric. Spark pools allow specifying a min and max number of nodes, and Fabric can auto-scale the pool based on load. They configured each pool according to its workload pattern (e.g., a “batch ETL” pool that can scale to many nodes during nightly jobs, a smaller “ad-hoc” pool with lower max, etc.).
Alternatives:
A retail data engineering team ran a daily pipeline to copy 850 GB of sales data from various sources into their lakehouse. Originally, they did this in a largely sequential manner- reading from one source table at a time and then moving to the next, due to dependencies in the pipeline. This resulted in an 8-hour copy process each day and about $2,800/month in Data Factory data movement costs. During peak season, the long sequential copy became a bottleneck that delayed downstream processing.
They reworked the pipeline to maximize parallelism in the copy operations. The new approach involved: (a) partitioning the source data so it could be read in parallel chunks, and (b) increasing the Data Integration Units (DIUs) and using the parallelCopies setting of the Copy activity to perform simultaneous transfers.
In addition to configuring a single Copy activity for high throughput, they sometimes needed to orchestrate multiple copies in parallel when data came from multiple source tables or partitions. They leveraged a parameterized pipeline that could spawn copies for each partition.
Data Partitioning Strategy: On the source side, they also ensured the source database was partitioned appropriately to help with parallel extraction. For instance, if the source was SQL Server, they partitioned the sales_data table by date (or some key) so that reading different partitions in parallel wouldn’t contend on the same I/O. For example:
1-- SQL: Partition the source table by month (for example)
2CREATE PARTITION FUNCTION sales_data_partition_func (DATE)
3AS RANGE RIGHT FOR VALUES
4 ('2024-01-01', '2024-02-01', ..., '2024-12-01');
5CREATE PARTITION SCHEME sales_data_partition_scheme
6AS PARTITION sales_data_partition_func
7TO (sales_data_fg1, sales_data_fg2, ..., sales_data_fg12);
8-- (Where sales_data_fg1...fg12 are filegroups or storage for each partition range)
9
10-- Verify partition row distribution (to ensure even workload spread)
11SELECT partition_number, rows, total_pages, avg_fragmentation_in_percent
12FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('sales_data'), NULL, NULL, 'DETAILED');Alternatives:
A team was storing 12TB of clinical data monthly in uncompressed JSON format, resulting in $4,200 storage costs and slow query performance. Data transfer between systems consumed additional $1,800 monthly in egress charges.
The team undertook a comprehensive format and compression optimization project. The goal was to convert the raw data into an optimized format (like Parquet or Delta), apply compression to shrink size, and prune any unnecessary data at the source. They also looked at optimizing data types to reduce footprint (for example, storing integers in smaller types when possible).
They used Snappy compression for Parquet (which is splittable and fast to decompress). They also set a large Parquet block size (256 MB) to ensure each Parquet file is relatively large and sequential, which is good for scanning performance, and a page size of 1 MB to improve compression ratio on highly repetitive data.
Additionally, they implemented logic to optimize data types: for example, if an integer column only contains values that fit in 2 bytes, cast it to SMALLINT (which cuts that column’s storage by 75%). For string columns, they looked at max length to decide if any optimizations (like using dictionary encoding) would naturally happen.
They didn’t stop at one setting, different datasets got different treatments. For example, they defined compression strategies for different data types:
Even after you’ve squeezed out waste in Fabric and right-sized Spark, tuned refreshes, compacted files, some BI/SQL workloads still pay the “cluster tax.” That’s where e6data comes in.
What it is: e6data is a lakehouse query engine with per-vCPU pricing. It atomically scales compute to each query’s needs (by the second), so you don’t size or babysit clusters. It runs directly on your existing Delta, Parquet, CSV, JSON, so no data migration, no model rewrites. Many teams keep Fabric platform for collaborative dev and ML, and offload cost-sensitive BI/SQL to e6data for extra savings.
Key benefits of the e6data approach
➡️ Interested in exploring this? Start a free trial of e6data and see how it compares on your own workloads.
.svg)
.svg)
.svg)
.png)

.svg)
.svg)
.svg)
.svg)
.svg)