.svg)
BigQuery's serverless architecture and automatic scaling deliver unmatched analytical performance, but that same flexibility can lead to unexpected cost spikes when teams optimize for speed without understanding the underlying slot-based pricing model. We've worked with dozens of data engineering teams running petabyte-scale analytics on BigQuery, and the pattern is consistent: costs often spiral when teams treat BigQuery as "pay-per-query" without considering slot utilization, data scanning patterns, and storage lifecycle management.
The reality? BigQuery's pricing complexity stems from its hybrid model: on-demand queries, reserved slots, storage tiers, and streaming inserts all follow different cost structures. Unlike traditional databases where you pay for fixed infrastructure, BigQuery charges for actual resource consumption, but optimizing that consumption requires understanding query execution patterns, data layout strategies, and workload classification.
This playbook focuses on practical optimizations that data engineering teams can implement immediately, organized by workload patterns that drive the highest costs. Each tactic includes runnable SQL configurations and BigQuery-specific monitoring queries, so you can start reducing costs without sacrificing the sub-second query performance your business users expect.
Before diving into optimizations, it's crucial to establish what qualifies as "high cost" in BigQuery. These benchmarks help identify inefficient usage patterns:
BigQuery costs primarily spike when one of three usage patterns dominates your workload. Understanding which pattern drives your highest expenses is crucial for targeted optimization:
Cost drivers: Repeated full-table scans, inefficient result caching, poor partitioning that doesn't match filter patterns, excessive slot allocation for peak concurrency, and materialized view maintenance overhead.
Optimization opportunities: Result caching eliminates duplicate computation, materialized views pre-aggregate frequent patterns, intelligent partitioning and clustering reduce scan volumes, and BI Engine acceleration delivers sub-second response times for small result sets.
Cost drivers: Full-table scans for hypothesis testing, lack of sampling strategies, inefficient JOIN operations, poor query complexity governance, and unnecessary precision in exploratory analysis that wastes compute resources.
Optimization opportunities: Intelligent data sampling reduces scan costs by 90%+ while maintaining statistical validity, approximate algorithms provide faster exploration, query complexity scoring prevents runaway costs, and federated queries minimize data movement expenses.
Cost drivers: Inefficient batch loading patterns, streaming insert frequency that exceeds business requirements, poor compression and storage layout choices, unnecessary cross-region data replication, and suboptimal scheduling that creates slot contention.
Optimization opportunities: Optimized batch sizing and compression reduce storage and compute costs, streaming insert consolidation eliminates unnecessary micro-batching, data lifecycle policies automatically manage storage tiers, and intelligent scheduling spreads resource usage across lower-cost time windows.
Typical cost pitfalls: Oversized slot allocation for peak concurrency, repeated full-table scans for dashboard refreshes, and poor result caching strategies that miss obvious optimization opportunities.
A retail analytics team was refreshing executive dashboards against a large transactions table every 15 minutes. Each refresh scanned substantial amounts of data, consuming significant query costs daily for identical aggregations across product categories, regions, and time periods. Dashboard queries repeatedly aggregate the same dimensions, but BigQuery rescans and re-aggregates unless you persist the results in materialized views that incrementally update.
Fix: Materialized view pipeline for dashboard queries (an example scenario). This turns heavy queries that scanned billions of bytes into lightweight queries scanning just a few megabytes of pre-computed data.
1-- Create base materialized view for daily sales aggregations
2CREATE MATERIALIZED VIEW `analytics.daily_sales_summary`
3PARTITION BY DATE(order_date)
4CLUSTER BY region, category
5AS
6SELECT
7 DATE(order_date) as order_date,
8 region,
9 category,
10 COUNT(*) as order_count,
11 SUM(amount) as total_revenue,
12 AVG(amount) as avg_order_value,
13 COUNT(DISTINCT customer_id) as unique_customers
14FROM `sales.transactions`
15WHERE order_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 365 DAY)
16GROUP BY 1, 2, 3;
17
18-- Dashboard query now scans KB instead of TB
19SELECT
20 region,
21 SUM(total_revenue) as revenue,
22 SUM(order_count) as orders,
23 AVG(avg_order_value) as avg_order_value
24FROM `analytics.daily_sales_summary`
25WHERE order_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
26GROUP BY region
27ORDER BY revenue DESC;
28
29-- Monitor materialized view efficiency
30SELECT
31 table_name,
32 last_refresh_time,
33 refresh_watermark,
34 size_bytes / 1e9 as size_gb
35FROM `analytics.INFORMATION_SCHEMA.MATERIALIZED_VIEWS`
36WHERE table_name = 'daily_sales_summary';Alternatives
A financial services dashboard was filtering a large customer events table by date ranges and account types, but the original partitioning strategy didn't match the dashboard filter patterns, forcing full partition scans across many date ranges.
Fix: Redesign partitioning strategy based on actual dashboard query patterns (an example scenario). In this case, partition by date (since every query uses a date range) and cluster by account_type (and perhaps event_type) so that queries which filter those fields will scan a much smaller subset of data.
1-- Analyze existing query patterns to optimize partitioning
2SELECT
3 REGEXP_EXTRACT(query, r'WHERE.*?(?=GROUP|ORDER|LIMIT|$)') as where_patterns,
4 COUNT(*) as frequency,
5 AVG(total_bytes_billed / 1e12) as avg_tb_scanned
6FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
7WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
8 AND query LIKE '%customer_events%'
9 AND statement_type = 'SELECT'
10GROUP BY where_patterns
11ORDER BY frequency DESC
12LIMIT 10;
13
14-- Create optimally partitioned table
15CREATE TABLE `analytics.customer_events_optimized` (
16 event_date DATE,
17 account_type STRING,
18 customer_id STRING,
19 event_type STRING,
20 event_value NUMERIC
21)
22PARTITION BY event_date
23CLUSTER BY account_type, event_type
24OPTIONS(
25 partition_expiration_days = 730,
26 require_partition_filter = true
27);
28
29-- Migrate data with optimal layout
30INSERT INTO `analytics.customer_events_optimized`
31SELECT * FROM `analytics.customer_events`
32WHERE event_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 730 DAY);
33
34-- Dashboard queries now skip irrelevant partitions
35SELECT
36 account_type,
37 COUNT(*) as events,
38 SUM(event_value) as total_value
39FROM `analytics.customer_events_optimized`
40WHERE event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE()
41 AND account_type IN ('premium', 'business')
42GROUP BY account_type;Alternatives
A marketing analytics platform ran the same complex cohort analysis queries many times daily across different dashboard users, with each query scanning large amounts of user behavior data and consuming significant costs per execution. There was no caching or reuse of results. Even though 90% of the logic was identical across these queries, BigQuery treated them as separate and scanned all the data each time. Small differences in the query SQL (like different literal values or slightly different SQL structure) meant the built-in cache wasn’t being hit.
Fix: Multi-level caching and query optimization strategy (an example scenario)
1-- Enable query result caching and optimize cache hit rates
2-- First, standardize query patterns to improve cache efficiency
3CREATE OR REPLACE VIEW `analytics.cohort_analysis_base` AS
4SELECT
5 DATE_TRUNC(first_purchase_date, WEEK) as cohort_week,
6 customer_id,
7 DATE_DIFF(purchase_date, first_purchase_date, WEEK) as weeks_since_first_purchase,
8 purchase_amount
9FROM `sales.customer_purchases`
10WHERE first_purchase_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 52 WEEK);
11
12-- Create cacheable cohort queries with consistent structure
13WITH cohort_base AS (
14 SELECT
15 cohort_week,
16 weeks_since_first_purchase,
17 COUNT(DISTINCT customer_id) as customers,
18 SUM(purchase_amount) as revenue
19 FROM `analytics.cohort_analysis_base`
20 WHERE cohort_week >= DATE_SUB(CURRENT_DATE(), INTERVAL 12 WEEK)
21 GROUP BY 1, 2
22),
23cohort_sizes AS (
24 SELECT
25 cohort_week,
26 COUNT(DISTINCT customer_id) as cohort_size
27 FROM `analytics.cohort_analysis_base`
28 WHERE weeks_since_first_purchase = 0
29 GROUP BY 1
30)
31SELECT
32 cb.cohort_week,
33 cb.weeks_since_first_purchase,
34 cb.customers,
35 cb.revenue,
36 cb.customers / cs.cohort_size as retention_rate
37FROM cohort_base cb
38JOIN cohort_sizes cs ON cb.cohort_week = cs.cohort_week
39ORDER BY cb.cohort_week, cb.weeks_since_first_purchase;
40
41-- Monitor cache hit rates and optimize queries for caching
42SELECT
43 job_id,
44 query,
45 cache_hit,
46 total_bytes_billed / 1e9 as gb_billed,
47 total_slot_ms / 1000 as slot_seconds
48FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
49WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
50 AND statement_type = 'SELECT'
51ORDER BY total_bytes_billed DESC;Alternatives
A business intelligence team was paying for substantial reserved slots to handle peak dashboard loads during business hours, but utilization dropped significantly outside business hours and on weekends, wasting considerable monthly costs on idle capacity. If you allocate, say, 500 slots to guarantee low latency at peak, those slots cost the same 24/7. Without autoscaling or workload isolation, you either waste money or, if you try to go on-demand to save cost, you risk slowdowns at peak.
Fix: Implement autoscaling reservations with workload isolation (an example scenario)
1-- Create separate reservations for different workload classes
2-- Production dashboards: guaranteed capacity
3CREATE RESERVATION `dashboard_production`
4OPTIONS (
5 slot_capacity = 500,
6 location = 'US',
7 edition = 'STANDARD'
8);
9
10-- Analytical workloads: flex slots for variable demand
11CREATE RESERVATION `analytics_flex`
12OPTIONS (
13 slot_capacity = 100,
14 location = 'US',
15 edition = 'STANDARD',
16 autoscale_max_slots = 1000
17);
18
19-- Assign projects to appropriate reservations
20CREATE ASSIGNMENT `dashboard_assignment`
21OPTIONS (
22 assignee_type = 'PROJECT',
23 assignee_id = 'dashboard-prod-project',
24 job_type = 'QUERY',
25 reservation = 'projects/your-project/locations/US/reservations/dashboard_production'
26);
27
28-- Monitor slot utilization and optimize reservation sizing
29SELECT
30 reservation_name,
31 slot_capacity,
32 APPROX_QUANTILES(total_slots, 4)[OFFSET(2)] as median_slots_used,
33 AVG(total_slots) as avg_slots_used,
34 MAX(total_slots) as peak_slots_used
35FROM `region-us.INFORMATION_SCHEMA.RESERVATION_TIMELINE_BY_PROJECT`
36WHERE start_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)
37GROUP BY reservation_name, slot_capacity
38ORDER BY reservation_name;
39
40-- Implement time-based slot scaling
41CREATE OR REPLACE PROCEDURE `analytics.scale_slots`(target_slots INT64)
42BEGIN
43 EXECUTE IMMEDIATE FORMAT("""
44 ALTER RESERVATION `analytics_flex`
45 SET OPTIONS (slot_capacity = %d)
46 """, target_slots);
47END;Alternatives
A customer support dashboard displaying real-time metrics was experiencing 5-15 second load times despite optimized queries, causing user frustration and reducing dashboard adoption across the support organization.
Fix: BI Engine configuration for accelerated dashboard performance (an example scenario)
1-- Enable BI Engine for critical dashboard tables
2ALTER TABLE `analytics.daily_sales_summary`
3SET OPTIONS (
4 max_staleness = INTERVAL '1' HOUR
5);
6
7-- Monitor BI Engine efficiency and cache hit rates
8SELECT
9 table_name,
10 bi_engine_statistics.bi_engine_mode,
11 bi_engine_statistics.bi_engine_reasons,
12 total_logical_bytes / 1e9 as logical_gb,
13 total_physical_bytes / 1e9 as physical_gb,
14 bi_engine_statistics.bi_engine_acceleration.bi_engine_mode as acceleration_mode
15FROM `analytics.INFORMATION_SCHEMA.TABLE_STORAGE_BY_PROJECT`
16WHERE bi_engine_statistics.bi_engine_mode IS NOT NULL
17 AND table_name IN ('daily_sales_summary', 'customer_metrics', 'support_tickets');
18
19-- Optimize queries for BI Engine acceleration
20-- Keep result sets under 100GB for optimal acceleration
21SELECT
22 support_agent,
23 ticket_status,
24 COUNT(*) as ticket_count,
25 AVG(resolution_time_hours) as avg_resolution_time
26FROM `support.tickets_summary`
27WHERE created_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
28 AND created_date <= CURRENT_DATE()
29GROUP BY support_agent, ticket_status
30HAVING ticket_count >= 5
31ORDER BY ticket_count DESC
32LIMIT 100;
33
34-- Create BI Engine optimized views for common dashboard patterns
35CREATE OR REPLACE VIEW `analytics.realtime_kpis` AS
36SELECT
37 DATE(event_timestamp) as event_date,
38 EXTRACT(HOUR FROM event_timestamp) as event_hour,
39 event_type,
40 COUNT(*) as event_count,
41 COUNT(DISTINCT user_id) as unique_users
42FROM `events.user_interactions`
43WHERE DATE(event_timestamp) >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
44GROUP BY 1, 2, 3;Alternatives
Typical cost pitfalls: Full-table scans for exploratory queries, lack of intelligent sampling strategies, and poor query complexity governance that allows runaway costs.
A data science team was running full-table scans on their large customer behavior dataset to test simple hypotheses like "conversion rates by traffic source" or "seasonal patterns in user engagement." Each exploratory query was consuming substantial memory and generating significant costs per execution.
Full-table exploration wastes compute when representative samples provide equally valid statistical insights for hypothesis testing and pattern discovery.
Fix: Multi-level sampling strategy for cost-effective exploration (an example scenario)
1-- Systematic sampling for representative analysis
2SELECT
3 traffic_source,
4 COUNT(*) as total_users,
5 COUNT(CASE WHEN converted = true THEN 1 END) as conversions,
6 COUNT(CASE WHEN converted = true THEN 1 END) / COUNT(*) as conversion_rate
7FROM `analytics.customer_journey` TABLESAMPLE SYSTEM (1 PERCENT)
8WHERE visit_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 90 DAY)
9GROUP BY traffic_source
10ORDER BY conversion_rate DESC;
11
12-- Reservoir sampling for exact sample sizes regardless of table growth
13SELECT
14 device_type,
15 session_duration_minutes,
16 pages_viewed,
17 purchase_amount
18FROM `analytics.user_sessions` TABLESAMPLE RESERVOIR (10000 ROWS)
19WHERE session_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY);
20
21-- Stratified sampling for balanced representation across segments
22WITH segment_samples AS (
23 SELECT *, ROW_NUMBER() OVER (PARTITION BY user_segment ORDER BY RAND()) as rn
24 FROM `analytics.user_profiles`
25 WHERE last_active_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 180 DAY)
26)
27SELECT
28 user_segment,
29 avg_monthly_spend,
30 total_sessions,
31 account_tenure_months
32FROM segment_samples
33WHERE rn <= 1000 -- 1000 users per segment
34ORDER BY user_segment, avg_monthly_spend DESC;
35
36-- Monitor sampling accuracy vs full table results
37SELECT
38 'full_table' as method,
39 COUNT(*) as total_rows,
40 AVG(session_duration) as avg_duration,
41 STDDEV(session_duration) as duration_stddev
42FROM `analytics.user_sessions`
43WHERE session_date = CURRENT_DATE()
44
45UNION ALL
46
47SELECT
48 'sampled_1pct' as method,
49 COUNT(*) * 100 as extrapolated_total, -- Scale up sample
50 AVG(session_duration) as avg_duration,
51 STDDEV(session_duration) as duration_stddev
52FROM `analytics.user_sessions` TABLESAMPLE SYSTEM (1 PERCENT)
53WHERE session_date = CURRENT_DATE();Alternatives
A marketing analytics team needed quick approximations of unique users, funnel conversion rates, and customer lifetime value across large datasets, but exact calculations were taking substantial time per query and consuming significant slot resources.
Exact computations on very large data (especially COUNT(DISTINCT), medians, 95th percentiles, top-k elements, etc.) require scanning and shuffling a lot of data. For example, counting distinct users over a big dataset can’t be easily broken down and usually triggers a large shuffle in BigQuery. Similarly, calculating precise percentiles can be heavy. Doing this frequently (say daily or ad-hoc) incurs big costs and might not be timely.
Fix: Approximate algorithm optimization for exploratory analytics (an example scenario)
1-- Replace exact unique counts with HyperLogLog approximation
2SELECT
3 campaign_id,
4 event_date,
5 HLL_COUNT.MERGE(user_hll) as approx_unique_users,
6 COUNT(*) as total_events,
7 SUM(event_value) as total_value
8FROM (
9 SELECT
10 campaign_id,
11 event_date,
12 HLL_COUNT.INIT(user_id) as user_hll,
13 COUNT(*) as events,
14 SUM(purchase_amount) as event_value
15 FROM `marketing.campaign_events`
16 WHERE event_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
17 GROUP BY 1, 2
18)
19GROUP BY campaign_id, event_date
20ORDER BY approx_unique_users DESC;
21
22-- Use approximate quantiles for percentile analysis
23SELECT
24 product_category,
25 APPROX_QUANTILES(price, 100)[OFFSET(25)] as p25_price,
26 APPROX_QUANTILES(price, 100)[OFFSET(50)] as median_price,
27 APPROX_QUANTILES(price, 100)[OFFSET(75)] as p75_price,
28 APPROX_QUANTILES(price, 100)[OFFSET(95)] as p95_price
29FROM `sales.product_purchases`
30WHERE purchase_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 90 DAY)
31GROUP BY product_category;
32
33-- Approximate top-K analysis for trending insights
34SELECT
35 APPROX_TOP_COUNT(search_query, 20) as top_searches,
36 APPROX_TOP_SUM(search_query, clicks, 15) as top_searches_by_clicks
37FROM `search.query_logs`
38WHERE search_date = CURRENT_DATE();
39
40-- Compare approximate vs exact for accuracy validation
41WITH exact_results AS (
42 SELECT
43 COUNT(DISTINCT user_id) as exact_users,
44 PERCENTILE_CONT(session_duration, 0.5) OVER() as exact_median
45 FROM `analytics.sessions`
46 WHERE DATE(session_start) = CURRENT_DATE()
47),
48approx_results AS (
49 SELECT
50 HLL_COUNT.INIT(user_id) as approx_users_hll,
51 APPROX_QUANTILES(session_duration, 100)[OFFSET(50)] as approx_median
52 FROM `analytics.sessions`
53 WHERE DATE(session_start) = CURRENT_DATE()
54)
55SELECT
56 HLL_COUNT.EXTRACT(approx_users_hll) as approx_users,
57 exact_users,
58 ABS(HLL_COUNT.EXTRACT(approx_users_hll) - exact_users) / exact_users as user_error_pct,
59 approx_median,
60 exact_median,
61 ABS(approx_median - exact_median) / exact_median as median_error_pct
62FROM exact_results, approx_results;Alternatives
A data science team had multiple expensive surprise bills when analysts accidentally created cartesian products or inefficient window functions across large tables, running for extended periods before manual intervention.
There was no proactive check on query complexity or cost before execution. BigQuery will let you run a 100TB join if you have the quota, and while you can set project-level quotas, sometimes these were broad. The team needed a way to catch obviously complex or potentially costly queries before they ran too long, or at least stop them quickly and inform the user.
Fix: Automated query complexity analysis and cost prevention (an example scenario)
1-- Create query complexity analysis function
2CREATE OR REPLACE FUNCTION `analytics.estimate_query_cost`(query_text STRING)
3RETURNS STRUCT<
4 estimated_tb_scanned FLOAT64,
5 estimated_cost_usd FLOAT64,
6 complexity_score INT64,
7 risk_level STRING
8>
9LANGUAGE js AS """
10 // Simple heuristic-based cost estimation
11 var cost_per_tb = 5.0;
12 var complexity_score = 0;
13 var estimated_tb = 0.1; // Base estimate
14
15 // Increase estimates based on query patterns
16 if (query_text.includes('SELECT *')) complexity_score += 3;
17 if (query_text.includes('CROSS JOIN')) complexity_score += 5;
18 if (query_text.includes('WINDOW')) complexity_score += 2;
19 if ((query_text.match(/JOIN/g) || []).length > 3) complexity_score += 2;
20
21 // Estimate TB scanned based on complexity
22 estimated_tb = Math.pow(1.5, complexity_score) * 0.1;
23
24 var risk_level = complexity_score < 3 ? 'LOW' :
25 complexity_score < 6 ? 'MEDIUM' : 'HIGH';
26
27 return {
28 estimated_tb_scanned: estimated_tb,
29 estimated_cost_usd: estimated_tb * cost_per_tb,
30 complexity_score: complexity_score,
31 risk_level: risk_level
32 };
33""";
34
35-- Monitor and analyze expensive queries
36CREATE OR REPLACE VIEW `analytics.query_cost_analysis` AS
37WITH query_stats AS (
38 SELECT
39 job_id,
40 user_email,
41 query,
42 total_bytes_billed / 1e12 as tb_billed,
43 (total_bytes_billed / 1e12) * 5.0 as estimated_cost_usd,
44 total_slot_ms / 1000 as slot_seconds,
45 TIMESTAMP_DIFF(end_time, start_time, SECOND) as duration_seconds,
46 creation_time
47 FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
48 WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)
49 AND state = 'DONE'
50 AND statement_type = 'SELECT'
51)
52SELECT
53 *,
54 analytics.estimate_query_cost(query) as complexity_analysis,
55 CASE
56 WHEN estimated_cost_usd > 50 THEN 'EXPENSIVE'
57 WHEN estimated_cost_usd > 10 THEN 'MODERATE'
58 ELSE 'CHEAP'
59 END as cost_category
60FROM query_stats
61WHERE tb_billed > 0.1 -- Focus on queries that scan >100GB
62ORDER BY estimated_cost_usd DESC;
63
64-- Create cost alerts and query governance
65CREATE OR REPLACE PROCEDURE `analytics.check_query_cost_alerts`()
66BEGIN
67 DECLARE alert_threshold FLOAT64 DEFAULT 25.0; -- $25 threshold
68
69 CREATE TEMP TABLE recent_expensive_queries AS
70 SELECT
71 job_id,
72 user_email,
73 estimated_cost_usd,
74 query,
75 creation_time
76 FROM `analytics.query_cost_analysis`
77 WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR)
78 AND estimated_cost_usd > alert_threshold;
79
80 -- Alert logic would integrate with notification systems
81 SELECT
82 CONCAT('COST ALERT: Query ', job_id, ' by ', user_email,
83 ' cost $', ROUND(estimated_cost_usd, 2)) as alert_message,
84 query,
85 creation_time
86 FROM recent_expensive_queries;
87END;Alternatives
A business intelligence team was running multi-table analytical queries across large fact tables and dimension tables, consuming substantial memory per query and taking considerable time to complete.
Joining a huge fact table with multiple dimensions at full granularity can be very expensive if you only ultimately needed an aggregated result. Similarly, if you join two huge tables and then filter, it’s often better to filter first or pre-aggregate to reduce data. The default join order or type might not be optimal for every scenario (though the query planner does a decent job).
Fix: Advanced JOIN optimization and query restructuring (example scenario)
1-- Optimize join order and use appropriate join types
2-- First, analyze table cardinalities to inform join strategy
3SELECT
4 table_name,
5 row_count,
6 size_bytes / 1e9 as size_gb,
7 partitioning_type,
8 clustering_fields
9FROM `analytics.INFORMATION_SCHEMA.TABLE_STORAGE_BY_PROJECT`
10WHERE table_name IN ('customer_orders', 'products', 'customers', 'stores')
11ORDER BY row_count DESC;
12
13-- Use broadcast joins for small dimension tables
14SELECT
15 o.order_id,
16 c.customer_segment,
17 p.product_category,
18 s.store_region,
19 o.order_amount
20FROM `sales.customer_orders` o
21LEFT JOIN `reference.customers` c ON o.customer_id = c.customer_id
22LEFT JOIN `reference.products` p ON o.product_id = p.product_id
23LEFT JOIN `reference.stores` s ON o.store_id = s.store_id
24WHERE o.order_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY);
25
26-- Pre-aggregate before expensive joins
27WITH daily_sales AS (
28 SELECT
29 order_date,
30 customer_id,
31 store_id,
32 COUNT(*) as order_count,
33 SUM(order_amount) as daily_amount,
34 AVG(order_amount) as avg_order_value
35 FROM `sales.customer_orders`
36 WHERE order_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 90 DAY)
37 GROUP BY 1, 2, 3
38),
39customer_metrics AS (
40 SELECT
41 customer_id,
42 COUNT(DISTINCT order_date) as active_days,
43 SUM(daily_amount) as total_spent,
44 AVG(avg_order_value) as avg_order_value
45 FROM daily_sales
46 GROUP BY customer_id
47)
48SELECT
49 cm.customer_id,
50 c.customer_segment,
51 cm.active_days,
52 cm.total_spent,
53 cm.avg_order_value
54FROM customer_metrics cm
55JOIN `reference.customers` c ON cm.customer_id = c.customer_id
56WHERE cm.total_spent >= 1000
57ORDER BY cm.total_spent DESC;
58
59-- Use window functions efficiently to avoid self-joins
60SELECT
61 customer_id,
62 order_date,
63 order_amount,
64 -- Calculate running totals and rankings in single pass
65 SUM(order_amount) OVER (
66 PARTITION BY customer_id
67 ORDER BY order_date
68 ROWS UNBOUNDED PRECEDING
69 ) as running_total,
70 ROW_NUMBER() OVER (
71 PARTITION BY customer_id
72 ORDER BY order_amount DESC
73 ) as amount_rank,
74 LAG(order_amount) OVER (
75 PARTITION BY customer_id
76 ORDER BY order_date
77 ) as previous_order_amount
78FROM `sales.customer_orders`
79WHERE order_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 365 DAY)
80QUALIFY amount_rank <= 5; -- Top 5 orders per customer
81
82-- Monitor join performance and optimization opportunities
83SELECT
84 job_id,
85 query,
86 total_slot_ms / 1000 as slot_seconds,
87 max_slots_utilized,
88 total_bytes_processed / 1e9 as gb_processed,
89 TIMESTAMP_DIFF(end_time, start_time, SECOND) as duration_seconds
90FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
91WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
92 AND query LIKE '%JOIN%'
93 AND total_slot_ms > 60000 -- Queries using >60 slot-seconds
94ORDER BY total_slot_ms DESC;A data science team was running experimental queries and model development directly in production BigQuery, leading to unpredictable costs and resource contention with business-critical dashboards.
Solution: Create cost-optimized sandbox environments – for example, a separate BigQuery project (or projects per team) specifically for exploratory analysis. In these sandbox projects, implement stricter cost controls: smaller slot reservations or purely on-demand budgeted usage, lower or custom query quotas, and perhaps limited accessible data (maybe only views that sample the main data). By giving data scientists a “playground” that has guardrails, they can explore freely without the risk of runaway costs impacting production. Additionally, using separate projects allows clear attribution: you can see exactly how much is spent on ad-hoc exploration vs production dashboards vs ETL, etc.
Fix: Isolate and govern ad-hoc exploration with separate project & quotas
Alternatives
Typical cost pitfalls: Inefficient batch loading patterns, excessive streaming insert costs, and poor data lifecycle management that accumulates storage costs over time.
A financial data pipeline was loading substantial transaction data daily using basic INSERT statements, resulting in poor compression, inefficient clustering, and high query costs due to frequent full table scans.
Inefficient batch loading creates suboptimal data layout that impacts both storage costs and query performance throughout the table's lifetime. If you append data without partitions, queries pay to scan everything. If you don’t cluster on common query fields, BigQuery can’t skip data internally, and compression might not be as effective if data isn’t sorted. Also, loading data without using recommended methods (like using LOAD DATA for files or streaming API for large batches) can be slower and potentially costlier.
Fix: Optimized batch loading pipeline with intelligent clustering (example scenario)
1-- Create optimally structured table for batch loading
2CREATE OR REPLACE TABLE `finance.transactions_optimized` (
3 transaction_date DATE,
4 account_id STRING,
5 transaction_type STRING,
6 amount NUMERIC(15,2),
7 merchant_category STRING,
8 region STRING,
9 transaction_id STRING
10)
11PARTITION BY transaction_date
12CLUSTER BY account_id, transaction_type, merchant_category
13OPTIONS(
14 partition_expiration_days = 2555, -- 7 years retention
15 require_partition_filter = true
16);
17
18-- Optimized batch loading with proper ordering and compression
19INSERT INTO `finance.transactions_optimized`
20SELECT
21 DATE(transaction_timestamp) as transaction_date,
22 account_id,
23 transaction_type,
24 ROUND(amount, 2) as amount,
25 merchant_category,
26 region,
27 transaction_id
28FROM `staging.raw_transactions`
29WHERE processing_date = CURRENT_DATE()
30ORDER BY account_id, transaction_type, merchant_category; -- Match clustering key
31
32-- Use LOAD DATA for large CSV files with optimal format
33LOAD DATA INTO `finance.transactions_optimized`
34FROM FILES (
35 format = 'CSV',
36 uris = ['gs://your-bucket/transactions/*.csv'],
37 skip_leading_rows = 1,
38 field_delimiter = ',',
39 null_marker = '',
40 allow_quoted_newlines = false
41);
42
43-- Monitor loading efficiency and table optimization
44SELECT
45 table_name,
46 partition_id,
47 total_rows,
48 total_logical_bytes / 1e9 as logical_gb,
49 total_physical_bytes / 1e9 as physical_gb,
50 total_physical_bytes / total_logical_bytes as compression_ratio
51FROM `finance.INFORMATION_SCHEMA.PARTITIONS_META`
52WHERE table_name = 'transactions_optimized'
53 AND partition_id >= FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY))
54ORDER BY partition_id DESC;
55
56-- Optimize existing tables with clustering
57CREATE OR REPLACE TABLE `finance.transactions_reclustered` AS
58SELECT * FROM `finance.transactions_original`
59ORDER BY account_id, transaction_type, merchant_category;Alternatives
A real-time analytics platform was streaming substantial individual events per minute to BigQuery, generating significant daily streaming insert costs due to inefficient batching and unnecessary insertion frequency. BigQuery charges for streaming by rows, so sending one row at a time is the priciest way to do it. Plus, not partitioning the target table meant queries scanning it grew more expensive over time. And without clustering or architecture for real-time, query performance on live data was suboptimal.
Solution:
Alternatives
An e-commerce analytics platform was storing substantial granular event data with most queries only accessing recent data, while retaining everything at the same storage tier for regulatory compliance.
BigQuery does automatically drop storage costs by ~50% for data that’s not edited for 90 days (long-term storage pricing), but even that may not justify keeping huge volumes of stale data online. There’s also a performance overhead to extremely large tables (metadata load, partition count limits, etc.). Additionally, if compliance requires keeping data, it might be better stored in aggregated form or an external archive rather than raw detail in BigQuery.
Solution: Implement a tiered data architecture within BigQuery and automate the movement/expiration of data between tiers. Example scenario:
1-- Hot tier table: holds recent 30 days of detailed events for fast access
2CREATE OR REPLACE TABLE `analytics.events_hot` (
3 event_date DATE,
4 user_id STRING,
5 event_type STRING,
6 event_data JSON,
7 revenue NUMERIC
8)
9PARTITION BY event_date
10CLUSTER BY user_id, event_type
11OPTIONS(
12 partition_expiration_days = 30, -- keep 30 days in this table
13 description = 'Hot tier: Last 30 days of detailed events'
14);
15
16-- Warm tier table: holds the next 60 days of events (months 2-3) for less frequent analysis
17CREATE OR REPLACE TABLE `analytics.events_warm` (
18 event_date DATE,
19 user_id STRING,
20 event_type STRING,
21 event_data JSON,
22 revenue NUMERIC
23)
24PARTITION BY event_date
25CLUSTER BY event_type, event_date
26OPTIONS(
27 partition_expiration_days = 60, -- data here expires after additional 60 days (total 90 from original event)
28 description = 'Warm tier: Days 31-90 of events for occasional analysis'
29);
30
31-- Cold tier summary: after 90 days, we only keep aggregated info (no user-level detail for example)
32CREATE OR REPLACE TABLE `analytics.events_cold_summary` (
33 event_date DATE,
34 event_type STRING,
35 user_segment STRING,
36 event_count INT64,
37 total_revenue NUMERIC,
38 unique_users INT64
39)
40PARTITION BY event_date
41OPTIONS(
42 partition_expiration_days = 2555, -- e.g., ~7 years retention for compliance
43 description = 'Cold tier: Aggregated historical data (post-90 days)'
44);
45
46-- Stored Procedure to run daily that moves data from Hot -> Warm -> Cold and cleans up
47CREATE OR REPLACE PROCEDURE `analytics.manage_data_lifecycle`()
48BEGIN
49 -- Move data that just transitioned from hot to warm tier (e.g., data 31 days old)
50 INSERT INTO `analytics.events_warm`
51 SELECT * FROM `analytics.events_hot`
52 WHERE event_date = DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY);
53
54 -- Aggregate and archive data that just transitioned out of warm (e.g., data 91 days old)
55 INSERT INTO `analytics.events_cold_summary`
56 SELECT
57 event_date,
58 event_type,
59 CASE
60 WHEN revenue > 100 THEN 'high_value'
61 WHEN revenue > 10 THEN 'medium_value'
62 ELSE 'low_value'
63 END AS user_segment,
64 COUNT(*) AS event_count,
65 SUM(revenue) AS total_revenue,
66 COUNT(DISTINCT user_id) AS unique_users
67 FROM `analytics.events_warm`
68 WHERE event_date = DATE_SUB(CURRENT_DATE(), INTERVAL 90 DAY)
69 GROUP BY 1, 2, 3;
70
71 -- (Note: Above, we bucket users into segments by revenue, as an example of summarization)
72
73 -- The events_warm table has partition_expiration_days=60, so it will automatically drop partitions older than 60 days.
74 -- The events_hot table partitions older than 30 days drop off automatically as well.
75 -- The cold_summary will retain aggregated data for 7 years (or whatever is set).
76END;
77
78-- (You would schedule this procedure daily via Cloud Scheduler or an AppEngine cron, etc.)
79
80-- Monitoring storage across tiers to verify distribution
81SELECT
82 table_name,
83 SUM(size_bytes)/1e9 AS size_gb,
84 COUNT(DISTINCT partition_id) AS partition_count,
85 MIN(DATE(PARSE_DATETIME('%Y%m%d', partition_id))) AS oldest_data,
86 MAX(DATE(PARSE_DATETIME('%Y%m%d', partition_id))) AS newest_data
87FROM `analytics.INFORMATION_SCHEMA.TABLE_STORAGE_BY_PROJECT`
88WHERE table_name LIKE 'events_%'
89GROUP BY table_name
90ORDER BY size_gb DESC;Alternatives
A global analytics platform was replicating substantial data daily across multiple regions for disaster recovery and local access, generating significant monthly cross-region transfer costs that could be optimized.
Unneeded cross-region data transfer is expensive (BigQuery egress to other continents can be $0.12/GB or more). If you're duplicating petabytes without carefully evaluating need, costs skyrocket.
Use a smarter data localization strategy. Identify what data truly needs to be in each region and replicate only that. Perhaps keep full detail in one primary region and push aggregated or filtered subsets to other regions. Use federated queries (BigQuery can query across region via external query if needed) for occasional access instead of full copies. In cases of compliance (like EU user data must stay in EU), separate the data by region at ingestion (store EU user data in EU region from the start, US in US). Additionally, use scheduled queries or Data Transfer Service to copy only incremental changes or only the slices needed, instead of full snapshots daily. Essentially: minimize egress by localizing storage of new data, and by avoiding copying large datasets unnecessarily.
Alternatives
A data engineering team was running batch ETL jobs during business hours, competing with interactive dashboards for slot capacity and paying premium rates for peak-time compute resources.
Fix: Optimized scheduling with resource-aware job management
1-- Create resource usage analysis for optimal scheduling
2CREATE OR REPLACE VIEW `scheduling.resource_utilization` AS
3SELECT
4 EXTRACT(HOUR FROM creation_time) as hour_of_day,
5 EXTRACT(DAYOFWEEK FROM creation_time) as day_of_week,
6 COUNT(*) as job_count,
7 SUM(total_slot_ms) / 1000 / 3600 as total_slot_hours,
8 AVG(total_slot_ms) / 1000 as avg_slot_seconds,
9 SUM(total_bytes_billed) / 1e12 as total_tb_billed
10FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
11WHERE creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
12 AND statement_type IN ('INSERT', 'UPDATE', 'DELETE', 'CREATE_TABLE_AS_SELECT')
13GROUP BY 1, 2
14ORDER BY 1, 2;
15
16-- Implement priority-based job scheduling
17CREATE OR REPLACE TABLE `scheduling.job_queue` (
18 job_id STRING,
19 job_type STRING,
20 priority INT64, -- 1=highest, 5=lowest
21 estimated_slot_hours FLOAT64,
22 scheduled_time TIMESTAMP,
23 dependencies ARRAY<STRING>,
24 status STRING DEFAULT 'QUEUED'
25);
26
27-- Create adaptive scheduling procedure
28CREATE OR REPLACE PROCEDURE `scheduling.schedule_etl_jobs`()
29BEGIN
30 DECLARE current_hour INT64;
31 DECLARE is_business_hours BOOL;
32 DECLARE available_slots INT64;
33
34 SET current_hour = EXTRACT(HOUR FROM CURRENT_TIMESTAMP());
35 SET is_business_hours = current_hour BETWEEN 8 AND 18;
36
37 -- Adjust available slots based on time of day
38 SET available_slots = CASE
39 WHEN is_business_hours THEN 200 -- Reserve capacity for dashboards
40 ELSE 1000 -- Full capacity during off-hours
41 END;
42
43 -- Schedule high-priority jobs first
44 UPDATE `scheduling.job_queue`
45 SET
46 scheduled_time = CURRENT_TIMESTAMP(),
47 status = 'SCHEDULED'
48 WHERE status = 'QUEUED'
49 AND priority <= 2 -- High priority jobs
50 AND estimated_slot_hours <= available_slots
51 ORDER BY priority ASC, scheduled_time ASC
52 LIMIT 10;
53
54 -- Schedule batch jobs during off-peak hours
55 UPDATE `scheduling.job_queue`
56 SET
57 scheduled_time = CASE
58 WHEN is_business_hours THEN
59 TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL (20 - current_hour) HOUR)
60 ELSE CURRENT_TIMESTAMP()
61 END,
62 status = 'SCHEDULED'
63 WHERE status = 'QUEUED'
64 AND priority >= 3 -- Lower priority batch jobs
65 AND NOT is_business_hours
66 ORDER BY priority ASC
67 LIMIT 5;
68END;
69
70-- Create cost-optimized ETL patterns
71-- Use incremental processing to reduce resource consumption
72CREATE OR REPLACE PROCEDURE `etl.process_daily_increments`(processing_date DATE)
73BEGIN
74 -- Process only new/changed data
75 CREATE OR REPLACE TABLE `analytics.customer_metrics_temp` AS
76 SELECT
77 customer_id,
78 processing_date,
79 COUNT(*) as daily_transactions,
80 SUM(amount) as daily_spend,
81 MAX(transaction_timestamp) as last_transaction
82 FROM `raw.transactions`
83 WHERE DATE(transaction_timestamp) = processing_date
84 GROUP BY 1, 2;
85
86 -- Merge with existing data
87 MERGE `analytics.customer_metrics` T
88 USING `analytics.customer_metrics_temp` S
89 ON T.customer_id = S.customer_id AND T.processing_date = S.processing_date
90 WHEN MATCHED THEN
91 UPDATE SET
92 daily_transactions = S.daily_transactions,
93 daily_spend = S.daily_spend,
94 last_transaction = S.last_transaction
95 WHEN NOT MATCHED THEN
96 INSERT (customer_id, processing_date, daily_transactions, daily_spend, last_transaction)
97 VALUES (S.customer_id, S.processing_date, S.daily_transactions, S.daily_spend, S.last_transaction);
98
99 DROP TABLE `analytics.customer_metrics_temp`;
100END;
101
102-- Monitor scheduling efficiency and cost optimization
103SELECT
104 DATE(scheduled_time) as schedule_date,
105 EXTRACT(HOUR FROM scheduled_time) as schedule_hour,
106 job_type,
107 COUNT(*) as jobs_scheduled,
108 SUM(estimated_slot_hours) as total_slot_hours,
109 AVG(estimated_slot_hours) as avg_slot_hours_per_job
110FROM `scheduling.job_queue`
111WHERE scheduled_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)
112 AND status = 'COMPLETED'
113GROUP BY 1, 2, 3
114ORDER BY 1, 2;Alternatives
While BigQuery optimization dramatically reduces costs, some analytical workloads encounter efficiency limits due to slot-based resource allocation and single-engine constraints. e6data's compute engine provides complementary capabilities that address remaining cost inefficiencies:
Granular resource control: e6data's per-vCPU billing eliminates the slot allocation overhead that creates cost inefficiencies for variable analytical workloads, particularly during off-peak periods and exploratory data science work.
Cross-format query optimization: Unlike BigQuery's columnar focus, e6data's vectorized engine delivers comparable performance across Parquet, Delta, Iceberg, and CSV formats without requiring data conversion or format-specific optimization.
Automatic cost optimization: e6data's adaptive query engine automatically implements sampling, caching, and execution plan optimization without manual configuration, reducing the operational overhead of maintaining cost-efficient BigQuery deployments.
Hybrid deployment efficiency: Teams use e6data for cost-sensitive analytical workloads while maintaining BigQuery for real-time dashboards and streaming analytics, optimizing each workload with the most suitable engine rather than forcing all analytics through a single platform.
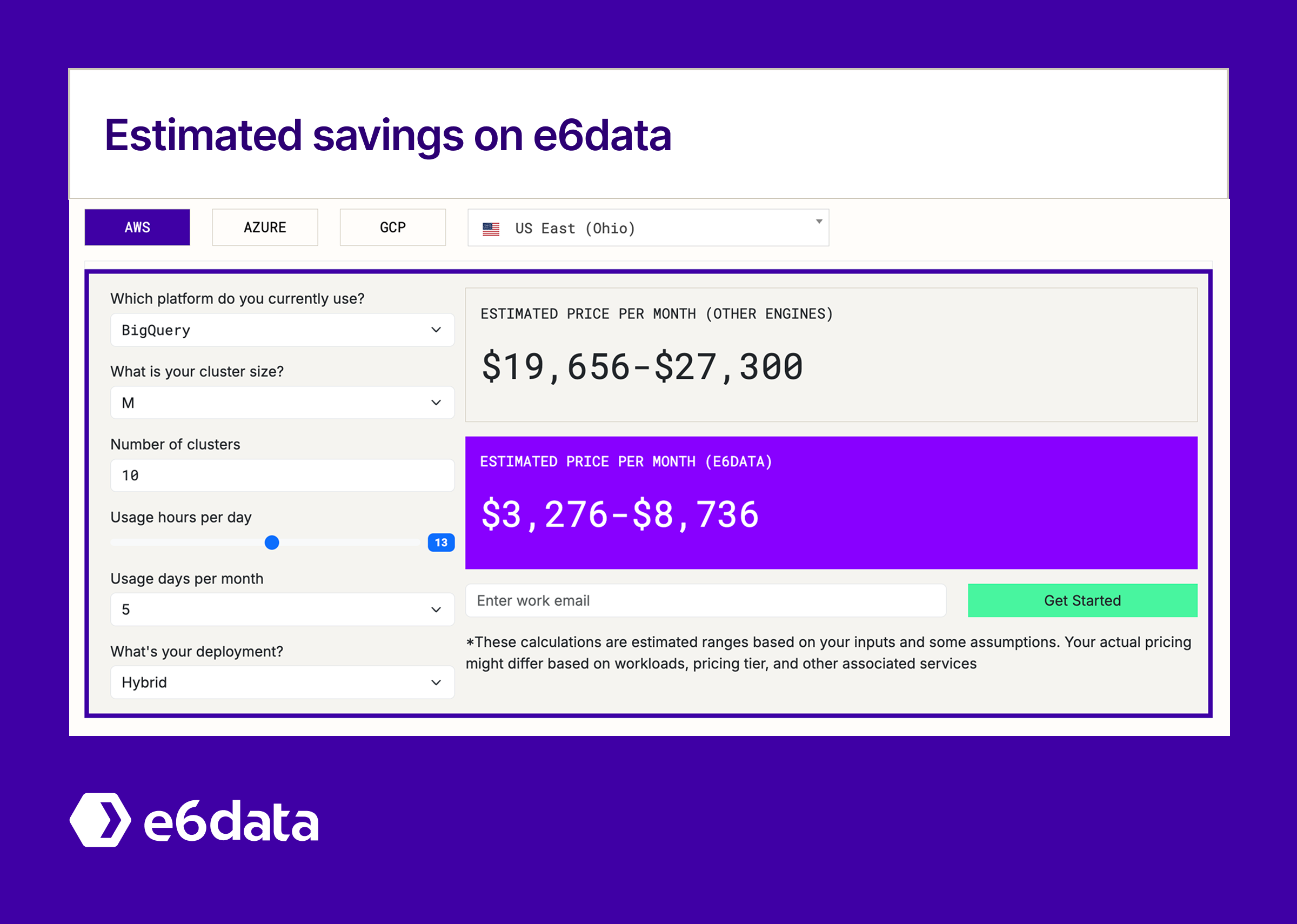
Implement BigQuery optimization tactics to capture immediate substantial cost savings, then evaluate e6data for variable analytical workloads where per-vCPU billing and automated optimization provide additional cost reductions. Leading data teams use this hybrid approach to maximize both performance and cost efficiency across their entire analytical stack.
➡️ Interested in exploring this? Start a free trial of e6data and see how it compares on your own workloads.
.svg)
.svg)
.svg)
.png)

.svg)
.svg)
.svg)
.svg)
.svg)