.svg)

ClickHouse's columnar architecture and blazing-fast query performance make it the go-to choice for real-time analytics at scale, but that same power can lead to unexpected costs if not properly managed. We've worked with dozens of teams running ClickHouse clusters processing terabytes daily, and the pattern is consistent: costs often spiral when teams optimize for query speed without considering resource efficiency, leading to oversized clusters, inefficient data layouts, and unnecessary data retention.
The good news? ClickHouse's granular control over storage, compute, and memory means every optimization directly translates to cost savings. Unlike black-box analytics platforms, ClickHouse gives you complete visibility into resource consumption at the table, partition, and query level. Whether you're running real-time dashboards, analytical workloads, or high-volume ETL pipelines, the key is leveraging ClickHouse's advanced features like TTLs, materialized views, and adaptive indexing to match resource usage to actual business needs.
This playbook focuses on practical optimizations that data engineering teams can implement immediately, organized by workload patterns. Each tactic includes runnable SQL configurations and ClickHouse-specific tuning parameters, so you can start reducing costs without sacrificing the sub-second query performance your users expect.
Before diving into optimizations, it's crucial to establish what qualifies as "high cost" in ClickHouse. These yardsticks help identify inefficient usage patterns:
ClickHouse costs primarily spike when one of three usage patterns dominates:
Typical cost pitfalls: Oversized clusters for peak concurrency and inefficient query patterns that don't leverage ClickHouse's materialized views and projection optimization
Real-time dashboards often re-run the same aggregations on large tables (tens of millions of rows), wasting CPU and GBs of RAM each refresh. ClickHouse will scan and aggregate the source on every query unless the results are persisted.
The solution is to create a materialized view that pre-computes those common aggregates on ingestion. In the example below, we create a summing MergeTree MV to aggregate daily transaction metrics (count, sum, uniques) by date, merchant, type. The dashboard queries then hit this pre-aggregated view (hundreds of rows) instead of the raw table (50M rows):
Materialized view optimization architecture:
1-- Create materialized view for common dashboard aggregations
2CREATE MATERIALIZED VIEW daily_transaction_metrics
3ENGINE = SummingMergeTree()
4PARTITION BY toYYYYMM(date)
5ORDER BY (date, merchant_id, transaction_type)
6AS SELECT
7 toDate(timestamp) as date,
8 merchant_id,
9 transaction_type,
10 count() as transaction_count,
11 sum(amount) as total_amount,
12 uniqExact(user_id) as unique_users
13FROM transactions
14GROUP BY date, merchant_id, transaction_type;
15
16-- Dashboard queries now hit the fast materialized view
17SELECT date, sum(total_amount) as daily_revenue
18FROM daily_transaction_metrics
19WHERE date >= today() - 30
20GROUP BY date
21ORDER BY date;Alternatives:
TTL to drop stale partitionsIf your table’s primary sort key doesn’t align with common query filters, ClickHouse will end up scanning many unnecessary parts. For example, an events table (200 GB) sorted by time might be frequently queried by category or region, forcing full scans because the data isn’t sorted to match those filters.
Add multiple projections to pre-sort and aggregate the data by those other dimensions. Projections are like materialized secondary indices: they store another sorted copy of your data (or aggregated data) that ClickHouse’s optimizer can automatically use for queries that match the projection’s sort key. Here we add two projections on a product_events table – one by category, one by region – then materialize them:
Fix: targeted projections
1ALTER TABLE product_events
2ADD PROJECTION proj_by_category (
3 SELECT category, product_id, device_type, sum(revenue)
4 GROUP BY category, product_id, device_type
5 ORDER BY category, product_id);
6
7ALTER TABLE product_events
8ADD PROJECTION proj_by_region (
9 SELECT region, date, count(), sum(revenue)
10 GROUP BY region, date
11 ORDER BY region, date);
12
13ALTER TABLE product_events MATERIALIZE PROJECTION proj_by_category;
14ALTER TABLE product_events MATERIALIZE PROJECTION proj_by_region;Alternatives:
You’re paying premium SSD rates to keep 18 months of detailed events hot even though about 90% of queries only touch the last 30 days. Storage keeps growing, merges and backups slow down, cache churn increases, and restore times stretch out. This sets you up for out-of-space incidents, throttling under load, and missed dashboard SLOs during peak hours.
Fix: tiered TTL
ALTER TABLE user_events MODIFY TTL
event_date + INTERVAL 30 DAY TO DISK 'cold_storage',
event_date + INTERVAL 90 DAY TO VOLUME 'archive',
event_date + INTERVAL 365 DAY DELETE;Guardrails:
cold_storage/archive map to cheaper disks or object-backed volumes.system.parts to watch move progress.Alternatives:
In many BI environments, users unknowingly issue hundreds of identical queries (e.g. the same dashboard refresh) per minute during business hours. For instance, if 50 users open the same dashboard around 9 AM, that could trigger the same heavy query 50 times. This hammers the database with duplicate work – CPU spikes and query queues build up even though the underlying data hasn’t changed. The result is wasted compute credits and slower performance for everyone.
To fix this, enable the built-in query result cache. ClickHouse’s query cache can store the result set of a query so that subsequent identical queries (with the same SQL text) can be served from cache instantly, without scanning or computation. It’s disabled by default, but simply toggling these settings can yield big savings:
Fix: router-level cache
1SET use_query_cache = 1;
2SET query_cache_ttl = 300; -- five-minute windowAlternatives:
ClickHouse performs best with batch inserts, but many real-time use cases (metrics, event feeds) send a stream of single-row or small-row inserts. For example, producers sending thousands of tiny inserts per second will create a huge number of small parts on disk. This triggers “merge storms” – constant background merges that spike I/O and CPU, and can even slow down read queries due to the fragmented data. In short, row-at-a-time writes are easy for producers but very expensive for ClickHouse.
By turning on async_insert, the ClickHouse server will accumulate incoming inserts in memory and flush them as larger batches. This essentially auto-batches small inserts without requiring changes on the client side. Key settings include:
Fix: async insert batching
1SET async_insert = 1;
2SET wait_for_async_insert = 0;
3SET async_insert_max_data_size = 1048576; -- 1 MB batchesAlternatives:
Buffer table engine which temporarily buffers incoming data in memory and periodically flushes to a MergeTree. This achieves a similar batching effect automatically.A common source of inefficiency is mixing heterogeneous workloads on the same cluster. For instance, low-latency dashboards and heavy ad-hoc analytical queries might share the same pool of resources. A single long-running analytical join can hog CPU or memory and make real-time dashboard queries slow or timeout. Conversely, a spike of dashboard queries could starve an analyst’s large query. Without isolation, everything competes, leading to missed SLAs and frustrated users.
ClickHouse allows setting resource limits per user or profile. We can create different profiles for, say, “dashboard_users” vs “analytics_users” and enforce separate quotas. In the configuration snippet below, we set stricter limits for the dashboard profile (e.g. lower memory and timeout) and higher limits for the analytics profile:
Fix: resource-isolated user profiles
1<users>
2 <dashboard_users>
3 <max_memory_usage>4000000000</max_memory_usage>
4 <max_execution_time>30</max_execution_time>
5 </dashboard_users>
6 <analytics_users>
7 <max_memory_usage>32000000000</max_memory_usage>
8 <max_execution_time>1800</max_execution_time>
9 </analytics_users>
10</users>Alternatives:
Typical cost pitfalls: Exploratory queries that scan entire tables and inefficient data sampling strategies that don't leverage ClickHouse's built-in optimization features
Data scientists and analysts often run ad-hoc queries to test hypotheses (e.g. “what’s the conversion rate by traffic source?”) on very large tables. Scanning an entire 500 GB events table for each hypothesis test can take minutes and gigabytes of CPU/memory. However, in many cases approximate answers from a sample would suffice during exploration.
ClickHouse’s TABLESAMPLE clause allows querying a random sample of the table’s data. You can specify a percentage or an absolute number of rows. For exploration, try sampling 1% or 0.1% of the table – this cuts scan size ~100×. For example:
Intelligent sampling architecture:
1-- Create stratified samples for common exploration patterns
2SELECT *
3FROM customer_events
4SAMPLE 0.01 -- 1% random sample
5WHERE event_date >= today() - 30;
6
7-- Reservoir sampling for more accurate representation
8SELECT *
9FROM customer_events
10SAMPLE 10000 -- Exactly 10K rows regardless of table size
11WHERE traffic_source IN ('google', 'facebook', 'organic');
12
13-- Deterministic sampling for reproducible analysis
14SELECT *
15FROM customer_events
16SAMPLE 0.1 OFFSET 0.5 -- 10% sample starting at 50% offset
17WHERE user_id % 100 = 42; -- Consistent user subsetAlternatives:
Joins in ClickHouse, while fast, can become expensive when a large fact table joins with a very large dimension table on each query. For example, joining a transactions fact with a 50 million–row product_catalog dimension to get product names can use 8–12 GB of memory per query. Traditional join processing will repeatedly scan the big dimension and build hash tables, etc., consuming a lot of CPU and RAM.
ClickHouse dictionaries allow you to load a dimension table (like product data) into memory (or on demand) and then use the dictGet() function to do key-value lookups, instead of a SQL join. This is much more efficient for high-frequency lookups. For instance, we can create a dictionary from the product_catalog table:
Dictionary-based lookup architecture:
1-- Create external dictionary from product catalog
2CREATE DICTIONARY product_dict (
3 product_id UInt64,
4 product_name String,
5 category String,
6 price Decimal64(2)
7)
8PRIMARY KEY product_id
9SOURCE(CLICKHOUSE(
10 HOST 'localhost'
11 PORT 9000
12 USER 'default'
13 TABLE 'product_catalog'
14 DB 'reference_data'
15))
16LAYOUT(HASHED())
17LIFETIME(3600); -- Refresh every hour
18
19-- Replace expensive JOINs with dictionary lookups
20SELECT
21 dictGet('product_dict', 'product_name', product_id) as product_name,
22 dictGet('product_dict', 'category', product_id) as category,
23 sum(quantity) as total_sold
24FROM transactions
25WHERE transaction_date = today()
26GROUP BY product_id, product_name, category;Alternatives:
Some analytical queries can “explode” in cost – e.g. a join with no selective filter or a cartesian product by mistake – and consume enormous resources (10+ GB RAM, hours of CPU) without the user realizing. In a pay-per-use environment, a single runaway query can rack up a big bill or impact other workloads.
One strategy is to use the system.query_log to identify patterns of heavy queries and then enforce rules. For example, you can detect queries that used >10 GB memory or ran >5 minutes in the last hour and flag them:
Query complexity analysis architecture:
1-- Analyze query complexity before execution
2SELECT
3 query,
4 type,
5 query_duration_ms,
6 memory_usage,
7 read_bytes,
8 read_rows,
9 result_rows
10FROM system.query_log
11WHERE event_time >= now() - INTERVAL 1 HOUR
12 AND (memory_usage > 10000000000 OR query_duration_ms > 300000) -- >10GB or >5min
13ORDER BY memory_usage DESC;
14
15-- Create query pattern analysis
16WITH query_patterns AS (
17 SELECT
18 replaceRegexpAll(query, '[0-9]+', 'N') as query_pattern,
19 avg(memory_usage) as avg_memory,
20 avg(query_duration_ms) as avg_duration,
21 count() as frequency
22 FROM system.query_log
23 WHERE event_time >= now() - INTERVAL 7 DAY
24 AND type = 'QueryFinish'
25 GROUP BY query_pattern
26)
27SELECT query_pattern, avg_memory, avg_duration, frequency
28FROM query_patterns
29WHERE avg_memory > 5000000000 -- Queries using >5GB on average
30ORDER BY avg_memory DESC;Alternatives:
When dealing with billions of rows, exact computations (exact COUNT(DISTINCT), medians, top-K, etc.) can be slow and costly. Often for exploratory analysis or dashboards, an approximate result (with error <1–2%) is good enough and can be obtained in a fraction of the time. For instance, calculating exact distinct user counts or exact medians on 1B+ events might take 10–20 minutes, whereas approximate methods yield almost the same insight in seconds.
ClickHouse offers approximate algorithms like uniq() (HyperLogLog-based) for distinct counts, quantile() and quantileTDigest() for percentiles, and topK() for top-K frequency estimation. These trade a tiny error for big speed gains. Example:
Approximate algorithm optimization:
1-- Replace exact unique counts with HyperLogLog approximation
2SELECT
3 category,
4 uniqExact(user_id) as exact_users, -- Slow: full precision
5 uniq(user_id) as approx_users, -- Fast: ~2% error
6 uniqHLL12(user_id) as hll_users -- Fastest: ~1.6% error
7FROM product_events
8WHERE event_date >= today() - 30
9GROUP BY category;
10
11-- Use approximate quantiles for percentile analysis
12SELECT
13 product_id,
14 quantileExact(0.5)(price) as exact_median, -- Slow: exact median
15 quantile(0.5)(price) as approx_median, -- Fast: approximate median
16 quantileTDigest(0.5)(price) as tdigest_median -- Memory-efficient
17FROM purchases
18WHERE purchase_date >= today() - 90
19GROUP BY product_id;
20
21-- Approximate top-K for trending analysis
22SELECT
23 topK(10)(product_id) as top_products, -- Approximate top 10
24 topKWeighted(10)(product_id, revenue) as top_by_revenue -- Weighted top 10
25FROM sales_events
26WHERE event_date = today();Alternatives:
Iterative feature engineering workflows repeatedly loaded the same 200 GB dataset, spending 15-20 minutes on data loading before each analysis iteration. Iterative analysis workflows reload the same base datasets repeatedly, wasting time and compute resources on redundant I/O operations.
Progressive loading and caching architecture:
1-- Create base dataset with intelligent partitioning
2CREATE TABLE analysis_base_cached AS
3SELECT * FROM transactions
4WHERE transaction_date >= today() - 365
5ORDER BY transaction_date, user_id;
6
7-- Use materialized views for common transformations
8CREATE MATERIALIZED VIEW user_features_mv
9ENGINE = AggregatingMergeTree()
10PARTITION BY toYYYYMM(transaction_date)
11ORDER BY (user_id, transaction_date)
12AS SELECT
13 user_id,
14 transaction_date,
15 count() as daily_transactions,
16 sum(amount) as daily_spend,
17 uniq(merchant_id) as unique_merchants,
18 avgState(amount) as avg_amount_state -- Use AggregateFunction for incremental updates
19FROM analysis_base_cached
20GROUP BY user_id, transaction_date;
21
22-- Incremental feature engineering
23SELECT
24 user_id,
25 avgMerge(avg_amount_state) as avg_transaction_amount,
26 sum(daily_spend) as total_spend,
27 sum(daily_transactions) as total_transactions
28FROM user_features_mv
29WHERE transaction_date >= today() - 30
30GROUP BY user_id;Alternatives: Use external caching systems like Redis for intermediate results or implement custom checkpointing with cloud storage.
Complex multi-table joins (e.g. joining a 500M+ row fact table with multiple 10M+ dimension tables) can consume tens of GBs of memory and run slowly if not executed with the ideal strategy. ClickHouse has different join algorithms (hash, merge, broadcast, etc.) and the query planner’s default choice might not be best for large-scale joins.
ClickHouse join performance depends heavily on join order, join algorithms, and data distribution, but default strategies often aren't optimal for large analytical workloads.
Sample Join optimization architecture:
1-- Use appropriate join algorithms based on table sizes
2SELECT
3 u.user_id,
4 u.user_type,
5 p.product_name,
6 sum(o.amount) as total_spent
7FROM orders o
8ANY LEFT JOIN users u ON o.user_id = u.user_id -- Use ANY for 1:1 joins
9ANY LEFT JOIN products p ON o.product_id = p.product_id
10WHERE o.order_date >= today() - 30
11GROUP BY u.user_id, u.user_type, p.product_name
12SETTINGS join_algorithm = 'parallel_hash'; -- Force parallel hash join
13
14-- Optimize join order with query hints
15SELECT
16 d.dimension_name,
17 sum(f.metric_value) as total_value
18FROM large_fact_table f
19GLOBAL ANY LEFT JOIN small_dimension_table d ON f.dimension_id = d.id -- Global join for distributed queries
20WHERE f.date_partition >= today() - 7
21GROUP BY d.dimension_name;Alternatives:
Typical cost pitfalls: Inefficient data ingestion patterns, excessive replication overhead, and poor partitioning strategies that lead to merge storms and degraded query performance
Inserting 50K small batches per hour into ClickHouse created thousands of tiny parts that consumed 60% of cluster CPU in constant background merges, slowing queries and inflating costs. Frequent small inserts create excessive part files that trigger constant background merging, consuming CPU resources and degrading overall cluster performance.
Optimal batch sizing architecture:
1-- Configure merge settings to handle your insert patterns
2ALTER TABLE tracking_events MODIFY SETTING
3 parts_to_delay_insert = 150,
4 parts_to_throw_insert = 300,
5 max_parts_in_total = 500,
6 merge_with_ttl_timeout = 86400;
7
8-- Monitor part count and merge activity
9SELECT
10 table,
11 count() as active_parts,
12 sum(bytes_on_disk) as total_bytes,
13 avg(bytes_on_disk) as avg_part_size
14FROM system.parts
15WHERE active = 1
16 AND database = 'production'
17GROUP BY table
18ORDER BY active_parts DESC;
19
20-- Optimize insert batch sizes based on data volume
21INSERT INTO tracking_events
22SELECT * FROM staging_events
23WHERE batch_id = getCurrentBatchId()
24 AND rowNumberInAllBlocks() <= 1000000; -- 1M rows per batchAlternatives:
Use Buffer engine for automatic batching, implement application-level buffering with periodic bulk inserts, or use e6data's auto-scaling compute for variable batch workloads with granular cost control.
By default, replicating data across many nodes can incur huge costs in both network and storage. For instance, one team was replicating ~5TB of new data daily across 6 nodes (for high availability), resulting in ~30TB/day of network traffic and 6× storage usage – much of it unnecessary. If your high availability (HA) needs are over-provisioned, you are paying a lot for little gain. Each extra replica multiplies the storage (and hence cost, if on cloud) and uses cluster bandwidth to sync data.
Sample Optimized replication architecture:
1-- Use ReplicatedMergeTree with minimal replicas
2CREATE TABLE trades_replicated (
3 trade_time DateTime,
4 symbol String,
5 price Decimal64(4),
6 volume UInt64,
7 trade_id String
8) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/trades', '{replica}')
9PARTITION BY toYYYYMMDD(trade_time)
10ORDER BY (symbol, trade_time, trade_id)
11SETTINGS
12 replicated_fetches_pool_size = 8, -- Parallel replication
13 max_replicated_fetches_network_bandwidth = 104857600, -- 100MB/s limit
14 replicated_max_parallel_sends = 4;
15
16-- Configure async replication for non-critical data
17ALTER TABLE logs_replicated MODIFY SETTING
18 replicated_log_to_table = 0, -- Reduce replication log overhead
19 replicated_sends_throttle = 1000, -- Throttle network usage
20 replicated_fetches_throttle = 1000;Alternatives:
Many ClickHouse deployments retain huge volumes of historical data “just in case,” even though the vast majority of queries only hit recent data. For example, 50 TB of device telemetry logs might be kept for 2 years, but 95% of queries only ever touch the last 30 days. Keeping all that data on fast SSD storage and constantly merging it is extremely costly and unnecessary.
ClickHouse’s TTL feature can automatically move partitions to different disks/volumes or delete data once it’s older than a certain threshold. By defining a tiered retention policy, you ensure recent data stays on fast (expensive) storage for quick access, while older data moves to cheaper storage, and really old data is dropped entirely.
Automated data lifecycle architecture:
1-- Implement multi-tier TTL policies
2ALTER TABLE device_telemetry MODIFY TTL
3 event_time + INTERVAL 7 DAY TO DISK 'ssd_disk', -- Hot: 7 days on SSD
4 event_time + INTERVAL 30 DAY TO DISK 'hdd_disk', -- Warm: 30 days on HDD
5 event_time + INTERVAL 90 DAY TO VOLUME 'cold_volume', -- Cold: 90 days on cold storage
6 event_time + INTERVAL 2 YEAR DELETE; -- Purge after 2 years
7
8-- Column-level TTL for granular control
9ALTER TABLE user_profiles MODIFY COLUMN
10 detailed_activity_log TTL created_at + INTERVAL 90 DAY, -- Delete sensitive columns early
11 session_history TTL created_at + INTERVAL 1 YEAR;
12
13-- Conditional TTL based on data characteristics
14ALTER TABLE logs MODIFY TTL
15 log_time + INTERVAL 30 DAY DELETE WHERE log_level = 'DEBUG',
16 log_time + INTERVAL 1 YEAR DELETE WHERE log_level = 'INFO',
17 log_time + INTERVAL 3 YEAR DELETE WHERE log_level = 'ERROR';Alternatives:
Inefficient partitioning can be very costly. For example, daily ETL jobs that needed only the last day of data ended up scanning entire tables because the tables were partitioned by month instead of day. This led to multi-hour processing windows and high I/O bills. Partitioning that doesn’t match query patterns means ClickHouse reads lots of partitions (parts) that could be skipped.
Analyze your query patterns to choose a partition key that filters data as much as possible. Time-based partitioning is common, but pick the appropriate interval (daily vs monthly, etc.). You can also partition by an additional key like region, category, etc., if many queries filter by those.
Example Query-optimized partitioning architecture:
1-- Analyze actual query patterns to optimize partitioning
2SELECT
3 extract(query, 'WHERE.*?(?=GROUP|ORDER|LIMIT|$)') as where_clause,
4 count() as frequency,
5 avg(read_bytes) as avg_bytes_scanned
6FROM system.query_log
7WHERE event_time >= now() - INTERVAL 30 DAY
8 AND query LIKE '%property_events%'
9 AND type = 'QueryFinish'
10GROUP BY where_clause
11ORDER BY frequency DESC;
12
13-- Re-partition based on dominant query patterns
14CREATE TABLE property_events_optimized (
15 event_time DateTime,
16 property_id UInt64,
17 city String,
18 event_type String,
19 price UInt64
20) ENGINE = MergeTree()
21PARTITION BY (toYYYYMM(event_time), city) -- Compound partitioning
22ORDER BY (property_id, event_time)
23SETTINGS index_granularity = 8192;
24
25-- Migrate data with optimal partitioning
26INSERT INTO property_events_optimized
27SELECT * FROM property_events
28WHERE event_time >= '2024-01-01'
29ORDER BY property_id, event_time;Alternatives:
Streaming 100K events per second directly into ClickHouse overwhelmed the cluster with constant small inserts and caused query performance degradation. High-frequency streaming inserts create excessive merge overhead and can destabilize cluster performance if not properly buffered.
Streaming optimization architecture:
1-- Use Kafka engine for efficient streaming ingestion
2CREATE TABLE kafka_events (
3 event_time DateTime,
4 user_id UInt64,
5 ad_id UInt64,
6 event_type String,
7 bid_amount Decimal64(4)
8) ENGINE = Kafka()
9SETTINGS
10 kafka_broker_list = 'kafka1:9092,kafka2:9092',
11 kafka_topic_list = 'ad_events',
12 kafka_group_name = 'clickhouse_consumer',
13 kafka_format = 'JSONEachRow',
14 kafka_num_consumers = 8, -- Parallel consumers
15 kafka_max_block_size = 1048576; -- 1MB blocks
16
17-- Create materialized view for automatic processing
18CREATE MATERIALIZED VIEW ad_events_mv TO ad_events_optimized AS
19SELECT
20 event_time,
21 user_id,
22 ad_id,
23 event_type,
24 bid_amount
25FROM kafka_events
26WHERE event_type IN ('impression', 'click', 'conversion'); -- Filter unwanted eventsAlternatives:
While ClickHouse optimization can dramatically reduce costs, some workloads demand even more granular resource control and cross-engine flexibility than any single platform can provide. That's where e6data's compute engine becomes a strategic complement for cost-conscious data teams.
Why teams are adding e6data alongside ClickHouse:
per-vCPU pricing: Instead of paying for entire ClickHouse clusters during low-utilization periods, e6data scales per-vCPU based on actual query demand. A recent customer reduced their analytical workload costs by 55% by moving variable-load queries to e6data while keeping real-time dashboards on ClickHouse.
Cross-format query optimization: While ClickHouse excels with columnar data, e6data's vectorized engine delivers comparable performance on mixed file formats (Parquet, Delta, even CSV) without requiring data migration. One media company eliminated their ETL preprocessing entirely, saving 4 hours of pipeline time daily.
Hybrid deployment flexibility: e6data queries the same data that ClickHouse uses, with no vendor lock-in. Teams use e6data for cost-sensitive batch analytics while keeping ClickHouse for low-latency operational queries, optimizing each workload independently.
Zero infrastructure overhead: Unlike ClickHouse cluster management, e6data provides fully managed compute that auto-scales from zero. You focus on queries, not infrastructure tuning.
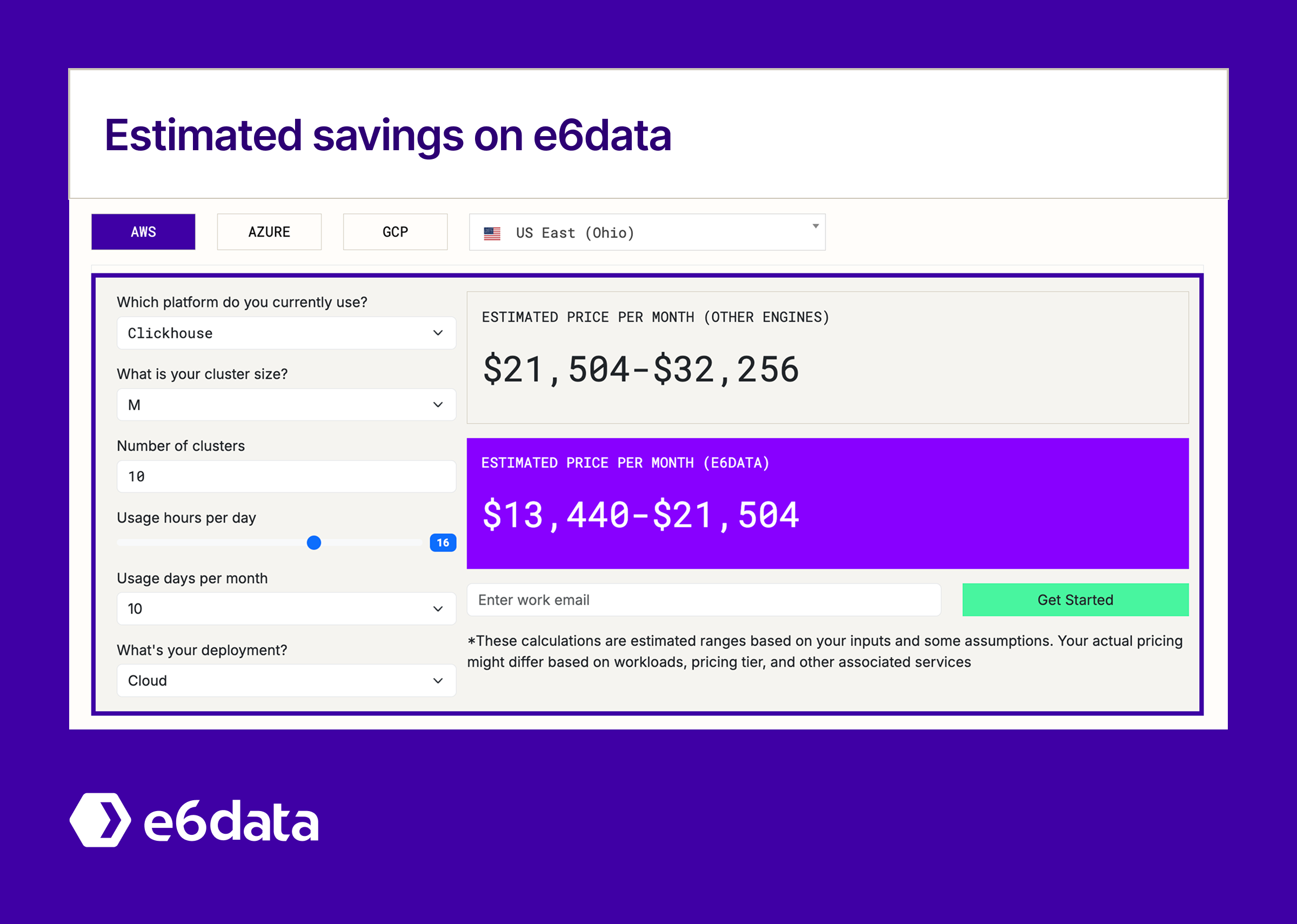
Ready to compare? Run your most resource-intensive ClickHouse queries on a free e6data trial. Most teams see immediate cost improvements on variable analytical workloads while keeping ClickHouse for what it does best.
.svg)
.svg)
.svg)
.png)

.svg)
.svg)
.svg)
.svg)
.svg)