.svg)

AWS Athena’s pay-per-query model makes it effortless to get started with big data analytics, but that same ease can lead to unwelcome surprises on your bill. We recall one team telling us that their Athena spend double in a single quarter, only to discover 70% of it came from repeatedly scanning the same data.
The good news: most Athena overspend comes from a few fixable patterns. By addressing these, teams have cut Athena costs without limiting their analysts’ queries. Quick overview of what to expect:
Even though “high cost” is relative, AWS Athena provides some yardsticks to help identify inefficient usage patterns. Before jumping into fixes, it’s important to audit your AWS Athena usage for these red flags:
| Scope | Rule of thumb threshold | Why it matters & How to check |
|---|---|---|
| Data scanned per dashboard refresh | >10 GB/query | Scan cost dominates at $5/TB. Use query_execution_ summary.bytes_scanned in CloudWatch to inspect. |
| Result-reuse hit rate | <70 % | Re-running identical SQL with 0% cache hit is expensive. Check QueryMetrics.Reused via the API or console toggle to check. |
| Unpartitioned table % | >20 % of total bytes | Full-table scans are one of the most common reasons for high cost/time. Run SHOW PARTITIONS <table> to check if rows are missing. |
| Workgroup byte-scan limit | “Unlimited” | A safety cap of 50–100 GB/day prevents unnecessary spending. You can configure it in Workgroup Settings → Data usage control. |
| Provisioned Capacity utilisation | < 40 % DPU usage over 7 days | Paying for idle DPUs increases costs unnecessarily. Monitor AthenaCapacityMetrics in CloudWatch. |
| Result files retained > 30 days | > 500 GB | Result objects cost storage and list-request fees. Use S3 Storage Lens or AthenaQueryResults/ bucket metrics. |
If several of these apply to your Athena usage, the following optimisations will help you a lot. But before that, think about which workload is driving most of your costs, because the optimizations will differ:
| Workload | Typical Pattern | Common Cost Risks |
|---|---|---|
| BI Dashboards | Dozens of repeat queries refreshing every n minutes | Re-scanning unchanged data, wide SELECT * queries, and high concurrency |
| Ad-hoc Analysis | Exploratory SQL by engineers/analysts | Trial-and-error large scans, forgotten output datasets, missing partitions |
| ETL / Pipelines | Scheduled CTAS/INSERT jobs populating datasets | Writing uncompressed CSV, re-reading “raw” data on each run, idle DPUs |
Dashboards often generate predictable, repetitive query patterns, and that makes them ripe for cost optimizations.
Many BI tools use Athena with identical queries every few minutes, even if the underlying data hasn’t changed. All that redundant scanning piles up costs.
For example, the Edge Delta team found that just 10 daily dashboard queries, each scanning ~0.55 TB, would rack up about $10K/year in Athena charges – and if those were hitting raw CSV data instead of optimized formats, it would have been over $30K/year.
How to implement –
For example, using the AWS CLI to update a workgroup’s settings, you would include a JSON configuration like:
{
"Enforced": true,
"ResultReuseByAgeConfiguration": { "MaxAgeInMinutes": 60 }
}
This ensures that if the same query text is executed again within 60 minutes (or whatever window you choose), Athena will skip the scan and return the cached results instantly (and for free).
Alternative –
If your dashboards can’t use Athena’s built-in reuse (for instance, if queries aren’t exactly identical each time), consider using materialized views. Create a materialized view that pre-computes the expensive query, refresh it nightly or hourly, and point the dashboard to that view. The view acts as a cache of the latest results without repeatedly scanning the base table.
Takeaway – Cache first; pay to scan only when the data actually changes.
Every Athena query is billed for scanning at least 10 MB of data, even if it returns only a few rows, which can lead to high costs. For instance, an interactive dashboard widget might let users run 30 quick queries in a row, each scanning 50 GB – that’s 1.5 TB scanned in minutes, or about $7.50 in cost before you blink.
Placing an upper limit on how much data a workgroup can scan per query (and per day) can safeguard your costs.
How to implement –
Alternative –
For more flexible alerting, you can complement (or substitute) hard limits with CloudWatch Alarms. Monitor the AthenaDataScanned CloudWatch metric and set an alarm to trigger if daily scanned bytes approach your budget.
Takeaway – Hard limits guardrails you against unnecessary large scan queries.
Traditional Hive-style partitioning (explicitly adding partitions to the Glue Catalog) can become a maintenance headache for large datasets, and if partitions are not added or updated in time, queries may end up scanning entire tables.
Partition Projection lets Athena auto-discover partitions based on filename patterns, eliminating manual “MSCK REPAIR” runs and ensuring queries only read relevant slices of data.
How to implement:
ALTER TABLE events
SET TBLPROPERTIES (
'projection.enabled'='true',
'projection.date.format'='yyyy/MM/dd',
'projection.date.range'='2024/01/01,NOW',
'projection.date.interval'='1',
'projection.date.unit'='DAY',
'storage.location.template'='s3://<your-bucket>/events/date=#{date}'
);
Alternative:
Takeaway: Partition Projection delivers the benefits of partition pruning with zero metastore upkeep, no more forgotten partitions or full-table scans by accident.
Athena’s query results are written to S3, and they can incur sneaky hidden costs if unmanaged.
How to implement:
<Rule>
<Prefix>AthenaQueryResults/</Prefix>
<Status>Enabled</Status>
<Expiration>
<Days>3</Days>
</Expiration>
</Rule>
Alternative:
Takeaway: Smaller, short-lived result files ensure S3 costs don’t end up out-billing your Athena queries.
Athena offers Provisioned Capacity dedicated DPUs) to handle high query volumes or concurrency beyond the on-demand limits. It costs $0.30 per DPU-hour (billed per minute), which can be cost-effective for heavy, constant workloads.
However, it’s easy to leave provisioned capacity running 24/7 even if only truly needed for a morning rush. For example, imagine you allocate 20 DPUs for your BI dashboards. That’s $6/hour, or ~$144/day. If those dashboards really hammer Athena only from 9 a.m. to 11 a.m. each day, the other 22 hours are mostly idle, potentially wasting over $100/day.
How to implement:
Allocate provisional capacity during known busy times and deallocate (scale to zero) when not needed. In the Athena console, you can pre-create a Capacity Reservation (e.g., 20 DPUs named “bi_capacity”). Then use a script or AWS SDK (boto3, etc.) to scale the allocated DPUs up or down.
Alternative:
Takeaway: Provision capacity when you need a feast of queries, but don’t pay for it 24/7.
Dashboard queries that have to sum or process millions of raw rows for each load are inherently expensive. If your dashboards frequently query very granular data (e.g., raw event logs) to compute higher-level metrics, you’re essentially redoing heavy computations and scans on each refresh.
How to implement:
Identify the “hot metrics” or common groupings your dashboards use (e.g., total sales by day). Create a scheduled job to run a CTAS (Create Table As Select) query that aggregates your raw data into a new table.
For instance:
-- Nightly batch job to aggregate yesterday’s events into summary table
CREATE TABLE bi_rollups
WITH (format = 'PARQUET', compression = 'SNAPPY') AS
SELECT date, country, SUM(sales) AS total_sales, COUNT(*) AS order_count
FROM raw_events
WHERE date = date '2025-01-15' -- or whatever date partition or range
GROUP BY date, country;
Alternative:
Athena now supports Materialized Views, which can achieve a similar result with potentially less manual orchestration.
You could create a materialized view like CREATE MATERIALIZED VIEW daily_sales AS SELECT date, country, SUM(sales) ... and have it refresh automatically or on a schedule. The view will maintain the pre-aggregated data for you.
Takeaway: Scan MBs, not TBs, on every dashboard render. By pre-computing common metrics, your dashboards read tiny summary files instead of entire raw datasets each time.
These one-off or iterative queries can be Athena’s greatest strength, but they also open the door to inadvertent inefficiencies – e.g., scanning a multi-terabyte table just to test a hypothesis, or running the same expensive join repeatedly during development.
Athena’s newer engine versions include a Cost-Based Optimizer that can dramatically improve query efficiency by making smarter decisions on join order, data scanning, and aggregation pushdown – if it has table statistics available.
AWS’s own benchmarks showed that enabling the CBO made some complex queries up to 2x faster, and overall query runtime dropped by ~11% on a standard TPC-DS workload.
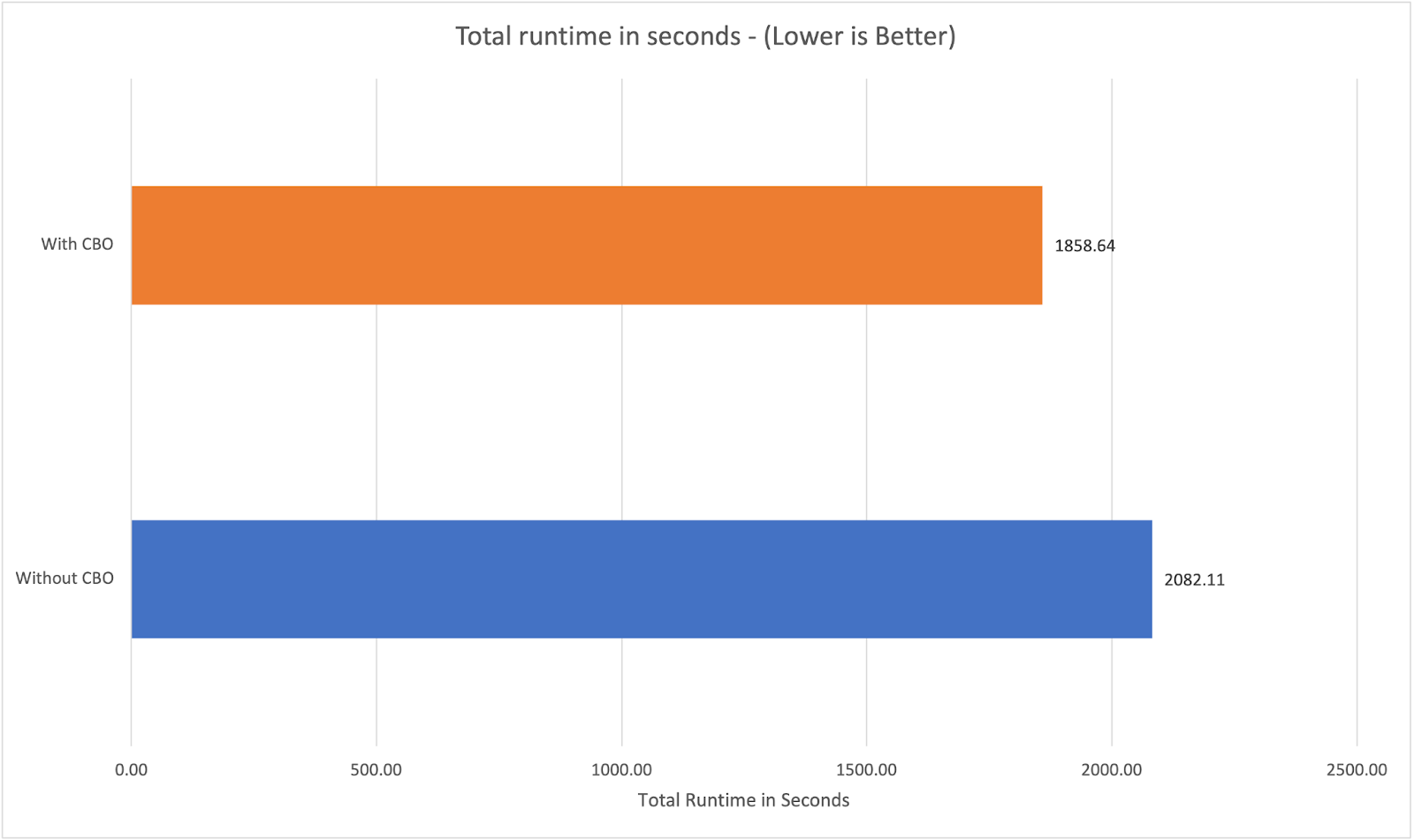
How to implement:
First, ensure you’re using Athena engine version 3 (which has CBO capabilities). Next, generate statistics for your frequently queried tables: in Athena, you do this by running the ANALYZE command. For example:
ANALYZE TABLE sales COMPUTE STATISTICS;
This tells Glue to compute column statistics (like min, max, NDV, etc.) for the sales table, which Athena’s optimizer will use for planning. Do this for your large or important tables (you can target specific columns or the whole table).
Athena’s CBO is automatically used when stats exist, but you can double-check or force it by setting a session property:
SET SESSION join_reordering_strategy = 'AUTOMATIC';
If you’re using JDBC/ODBC or notebooks, ensure this session property is on or use the equivalent toggle.
Alternative:
Takeaway: One ANALYZE today can mean perpetual savings thereafter. Investing in table stats and the CBO makes Athena automatically do less work for the same answers.
When analysts run queries interactively, they often focus only on the result, not realizing how much data was scanned. By making query cost visible for each query, you nudge users to be mindful.
How to implement:
Alternative:
For a quick solution, you can also leverage CloudWatch Logs Insights if you have Athena’s execution logs enabled. You could query Athena’s own logs to find queries and their scanned bytes, and then share a dashboard of that. It’s not real-time per query, but it can reveal trends.
Takeaway: Visible cost = mindful analysts. When users see the “price” of each query, they naturally learn to be more efficient.
When working on analyses, users often join the same large tables multiple times as they iterate. Each time, Athena scans those tables in full. A smarter approach for repetitive joins or complex subqueries is to do it once, store the result, and then query that instead.
How to implement:
Let’s say you’re repeatedly querying a combination of tables or applying the same complex filter criteria. Do it once and materialize the results. You can use a CTAS query in Athena to create a temporary table. For example:
CREATE TABLE scratch.joined_data
WITH (format = 'PARQUET', compression = 'SNAPPY') AS
SELECT a.user_id, a.event_time, b.purchase_amount, c.country
FROM raw_events a
JOIN purchases b ON a.event_id = b.event_id
JOIN users c ON a.user_id = c.user_id
WHERE a.event_time >= '2025-01-01'
AND b.purchase_amount > 0;
Alternative:
For quick one-off filtering of a single large file, consider Amazon S3 Select. If your data is in CSV/JSON and you want to retrieve a subset of columns or rows from one object, S3 Select can pull just that subset (reducing data transfer) without Athena overhead. It’s not suitable for joins or large multi-file operations, but for simple “select a few columns from this giant file” tasks, it can be cheaper and faster.
Takeaway: Pay once; read fast forever. Doing a heavy join or filter once and reusing the results means you pay the scan cost one time and then enjoy quick, cheap queries thereafter.
Athena’s performance (and cost) can degrade if too many queries contend for resources in one workgroup. Notably, long-running ETL or insert jobs can clog up the queue and slow down interactive queries. This way, an analyst isn’t waiting behind a huge batch job, and if needed, you can allocate separate capacity policies to each.
How to implement:
Athena Workgroups are your friend here:
Alternative:
For an even stronger isolation, some organizations create a dedicated AWS account for analysts and a different account for data engineering jobs. Athena’s cost is then isolated by account. Cross-account S3 access can let the analysts query the data without being impacted by the ETL account’s Athena usage at all. This is a heavier setup (requires managing two accounts and permissions), so using two workgroups is the simpler first step.
Takeaway: No more BI users queued behind nightly batch loads. Isolating workloads ensures a rogue ETL job can’t throttle your interactive queries (and vice-versa).
This might sound familiar from the BI section: ad-hoc queries also produce result files, and often even more chaotically. An analyst might run hundreds of throwaway queries in a day, generating hundreds of small S3 files. Over time, without cleanup, you accumulate potentially millions of objects consuming space and incurring request costs.
How to implement:
Alternative:
Instead of relying on S3 lifecycle alone, you could incorporate a cleanup step in your workflow. For instance, run a daily AWS Lambda that finds and deletes Athena result objects older than X days, or have users run queries in a scratch workgroup whose results bucket is periodically purged. This offers more control (you might skip deleting certain important query outputs), but it’s more work to maintain.
Takeaway: Treat Athena result sets as temporary scratch data – they shouldn’t outlive their usefulness.
SELECT * in Athena means scan every column of every row – you’ll pay to read all the data, even the columns you don’t actually use. An analyst might do SELECT * FROM large_table LIMIT 100 just to see the schema or a sample, but Athena will still scan potentially gigabytes or more, only to return 100 rows.
How to implement:
Encourage a culture (and provide tools) to select only needed columns. A practical way is to create safe, column-pruned views for commonly accessed tables. For example, if analysts only need a subset of columns from a raw events table, create a view that exposes just those:
CREATE VIEW safe_events AS
SELECT id, event_ts, country, device, ... -- (list only useful columns)
FROM raw_events;
Alternative:
Some teams leverage third-party tools or even custom Athena UDFs as a linter. Another approach is using Athena query federation to a proxy that can block certain patterns. These are complex solutions; a well-placed convention and view are usually sufficient.
Takeaway: By providing pre-defined, narrower views or simply instilling the habit of specifying columns, you can dramatically cut down scanned data (and costs).
Pipeline workloads can become one of the biggest cost drivers if not optimized: they might run on large raw datasets, produce multiple outputs, or use provisioned capacity for throughput.
The format you store your data in has an enormous impact on Athena costs. Text formats like CSV or JSON are bulky; Athena has to scan every byte of them. Columnar formats like Parquet or ORC, especially with compression, shrink the data to be scanned and allow Athena to skip irrelevant columns.
For ETL jobs that produce new tables, choosing Parquet+compression will make all downstream queries dramatically cheaper (and faster).
How to implement:
Whenever you have an Athena CTAS (Create Table As) or INSERT INTO that materializes data, specify a columnar format and compression. For example, in Athena SQL:
CREATE TABLE cleaned_data
WITH (format='PARQUET', compression='SNAPPY') AS
SELECT *
FROM staging_raw_data;
This reads staging_raw_data (perhaps in CSV or raw form) and writes it out as a new table cleaned_data, in Parquet format compressed with Snappy. Snappy is a good default compression for Parquet in Athena – it’s fast and gives decent compression. You could also use GZIP for higher compression at the cost of slower performance.
The key is not leaving data in plain text once it’s been processed. If you have existing pipelines writing to S3 via Glue jobs or Spark, configure those sinks to use Parquet or ORC. The one-time conversion cost pays for itself quickly in query savings.
Alternative:
Takeaway: Smaller files = faster scans = tinier bills. Use columnar formats and compression so Athena reads gigabytes instead of terabytes for the same data.
Partitioning is great for pruning large swaths of data, but if you partition on a very high-cardinality column (like user_id), you can end up with millions of tiny partitions, which hurts performance and incurs overhead. On the flip side, not partitioning that data means each query has to scan all the data for a given user.
The solution is bucketing: it groups data by a key into a fixed number of buckets (files) such that queries filtering on that key only scan a subset of buckets, not every file.
How to implement:
When creating tables in Athena, you can specify bucketing (also known as clustering in the CREATE TABLE syntax). Suppose we have a large transactions table of user events. We might partition it by date (daily partitions), but also bucket by user_id to distribute each day’s data into, say, 32 buckets by user. For example:
CREATE TABLE transactions_bucketed
PARTITIONED BY (dt string)
CLUSTERED BY (user_id) INTO 32 BUCKETS
AS
SELECT *
FROM transactions_raw;
This CTAS will reorganize the data such that for each dt partition, there are 32 files, each containing a range of user_id hash values. When Athena later queries transactions_bucketed for a specific user_id (or a small set of users), it can skip most of those buckets, scanning only 1/32 of the data (in this example).
Bucketing in Athena requires using the same number of buckets consistently, and queries use equality filtering on the bucket column to benefit. But when they do, it’s a big win.
Alternative:
Takeaway: Evenly sized files and buckets lead to consistent, efficient scans. Bucketing prevents the “too many tiny partitions” problem while still limiting scan scope for high-cardinality filters.
Athena traditionally works best with append-only, static datasets. If you have datasets that require updates, deletes, or frequent schema changes, using normal Glue tables means you often have to rewrite entire partitions or maintain complicated pipelines.
This can be costly – rewriting a whole partition just to change a few records means rescanning and rewriting a lot of data. Iceberg enables merge-on-read and hidden partitioning, meaning you can upsert or delete data in place without horrific reprocessing costs. With Iceberg, small incremental changes don’t require full table scans to be queryable.
How to implement:
Athena can create and query Iceberg tables natively (engine version 3). To convert or create a dataset as Iceberg, you use a CREATE TABLE statement with table_type='ICEBERG'. For example, say you have daily updates coming in for a sales table – rather than maintain a separate “delta” table and then merge it, you can do:
CREATE TABLE sales_iceberg
WITH (table_type='ICEBERG', format='PARQUET')
AS
SELECT *
FROM sales_updates;
This will create sales_iceberg as an Iceberg table (stored in Parquet under the hood) and import the data from sales_updates.
Going forward, you could use MERGE INTO or DELETE statements on sales_iceberg to apply changes. Iceberg handles versioning and only reads the portions of data necessary for queries via metadata. It also automatically tracks partitions (you can even partition by transformed keys, like year/month or truncate timestamps, without predefining folder paths).
Alternative:
Takeaway: By using modern table formats designed for mutability (like Iceberg), you avoid re-scanning or rewriting huge datasets for small changes, thereby saving tons of compute (and money).
Athena charges you for every byte scanned, regardless of S3 storage class. However, your S3 storage costs themselves can be optimized.
Many ETL pipelines produce data that is very hot when first created (queried often for recent reports), but then goes cold. Months or years of historical data might rarely be queried, yet you pay full price to store it in S3 Standard.
By tiering older data to Glacier Instant Retrieval (Glacier IR) or other archival storage, you cut storage costs by up to 90% – Glacier IR costs around $0.004 per GB-month (one-tenth of S3 Standard) and still allows direct Athena queries on the data when needed, with just a small per-query retrieval fee.
How to implement:
Alternative:
Takeaway: Storage tiers are the stealth lever in long-term TCO. By sliding your cold data into cheaper storage, you cut costs without affecting Athena’s ability to query the data when needed.
Athena is terrific for ad-hoc discovery, but some workloads simply need more horsepower or finer-grained cost control than $5 / TB scans can deliver. That’s where e6data’s compute engine can complement (or even replace) parts of your Athena stack:
.svg)
.svg)
.svg)
.png)

.svg)
.svg)
.svg)
.svg)
.svg)