.svg)
.svg)
.svg)
Subscribe to our newsletter - Data Engineering ACID
Share this article
.svg)
.svg)
Iceberg Catalogs 2025: A Deep Dive into Emerging Catalogs and Modern Metadata Management
June 27, 2025
/
Engineering

In June 2025, the Snowflake Summit 2025 and the Databricks Data+AI Summit 2025 shared many interesting developments and thoughts, which made me realize that the catalog war is still on.
The competition for Apache Iceberg catalogs certainly remains fierce and relevant. Several new catalogs have emerged in recent times, including Apache Polaris™ (incubating), Apache Gravitino, Lakekeeper, and Project Nessie, among others.
Databricks’ recent launch of Unity Catalog GA support for Apache Iceberg has introduced an exciting new facet to its ecosystem.
At the same time, the DuckDB announcement of DuckLake is equally important and has caught my attention. DuckLake streamlines lakehouses by employing a standard SQL database for metadata management, eliminating the need for complicated file-based systems while storing data in open formats like Parquet. This approach enhances reliability, speed, and manageability.
As a data engineer, these developments made me very interested and fascinated at the same time. But most of the developer community still banks on “classic” catalogs, such as Hadoop Catalog, Hive Metastore, and AWS Glue, but the landscape is expanding rapidly.
In this blog, I will explain the real meaning of a catalog, starting from the basics and then assessing where traditional options struggle. I’ll then get into what the newer catalogs bring to the table.
What is a Catalog in Apache Iceberg?
It’s the central metadata repository that every query engine consults to know what an Iceberg table looks like and where to find its data.
Simply put, an Iceberg catalog is a metadata store that tracks all your Iceberg tables.
It’s the bookkeeper for table information, including schema, partition layout, the latest snapshot, and the location of the root metadata file (e.g., v1.metadata.json), along with its manifest list and manifest files.
Apache Iceberg organizes data into three layers:
- Data layer: Raw data files & delete files. Mostly, data & delete files are Parquet file formats. Sometimes in ORC or AVRO.
- Metadata layer: Information about the Table metadata. It stores this information in the manifest files, manifest lists, and the root metadata.json that describes every file and snapshot.
- Catalog layer: The “phone book” that tells every engine where the latest root metadata.json lives. It is primarily an external service that tracks tables and their metadata.
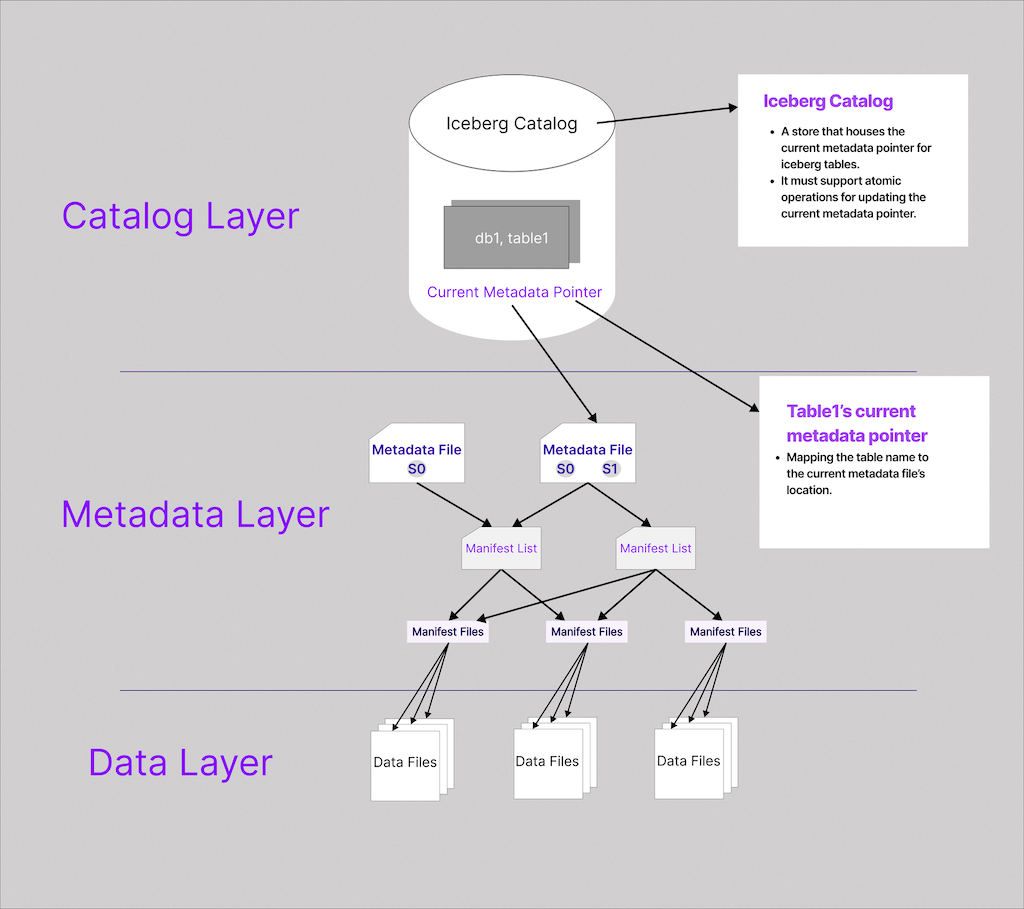
Without a catalog, an Iceberg table would just be a bunch of files in storage with no easy way to know which files make up the current table. The catalog provides a central pointer to the table’s current metadata, which in turn points to the current snapshot of the table’s data. This mechanism allows Iceberg to provide ACID guarantees and atomic commits on a data lake. Essentially, the catalog serves as the source of truth for the table’s state.
- In practice, whenever you create, update, or drop an Iceberg table, it’s the catalog that records those changes.
- For example, adding a new batch of data will create a new metadata JSON file for the table, and the catalog updates the pointer to reference this new metadata (so readers will see the new data in one consistent snapshot).
- In a similar vein, dropping a table will remove its entry from the catalog. By handling these operations consistently, the catalog prevents orphaned metadata and keeps tables in a clean, correct state.
- The catalog also enables multi-engine access because it behaves as a neutral store of metadata; multiple processing engines (e6data, Spark, Flink, and Trino) can concurrently read and write to Iceberg tables through the same catalog without stepping on each other’s toes.
- Some catalog implementations even support transaction locking or other mechanisms to coordinate multiple writers.
Iceberg is flexible about where this catalog lives. Broadly, there are two categories of catalogs in use today :
- File-based catalogs – The simplest approach: using a filesystem or object store to keep track of tables. The built-in Hadoop Catalog falls in this category. It doesn’t require any separate service – metadata is stored in files on disk.
- Service-based catalogs – These use an external service or database to store table metadata. Examples include using a Hive Metastore, AWS Glue Data Catalog, a JDBC database (such as PostgreSQL or MySQL), or newer, purpose-built services like Project Nessie. They usually add richer features (transaction coordination, security hooks, branching, or cross-table commits) and are the go-to choice for production. Many of the emerging catalogs are trying to follow the Iceberg REST specification.
Here are two of our existing blogs to understand more about catalogs.
- Why catalogs matter: The book-keeping of Apache Iceberg
- Relevance of low-level metadata catalogs in lakehouses
With this, you should now have a basic understanding of the catalog in Apache Iceberg. Let’s explore the traditional catalogs available in the market and discuss the reasons why new types of catalogs are being introduced into the Apache Iceberg ecosystem.
Why is a Traditional Catalog Not Enough?
If you’re deep in the Iceberg, you’re probably using Hadoop, AWS Glue, or Hive Metastore. But it’s no secret that these catalogs have their shortcomings. As someone who has used all these catalogs, I have identified some of the reasons why using traditional catalogs is bothersome.

Hadoop Catalog
Hive Metastore
AWS Glue Data Catalog
Which are the Exciting New Age Catalogs?
Hadoop Catalog, HMS, and Glue all satisfy Iceberg’s minimum contract: “keep a table-name → metadata pointer and swap it atomically.” But they stop there. They don’t speak Git-style branching, nor do they have coordinated multi-table commits, nor have they built-in governance. That gap is exactly what the newer catalogs, such as Project Nessie, Apache Polaris, Gravitino, Lakekeeper, and now Unity Catalog, are aiming to close.
Project Nessie
Project Nessie is an open-source transactional catalog for Iceberg that brings Git-style branches, tags, and commit history to data lakes. This lets you experiment on an isolated branch and then merge (or roll back) when you’re satisfied, exactly as the workflow developers are familiar with from the source code.
This introduces a bunch of features for data management:
- You can isolate experimental changes on a branch (e.g., dev or staging branches for a dataset).
- Confidently test these changes.
- Only merge the changes to the main branch when ready, while retaining the ability to time-travel or revert as the commit history is tracked.
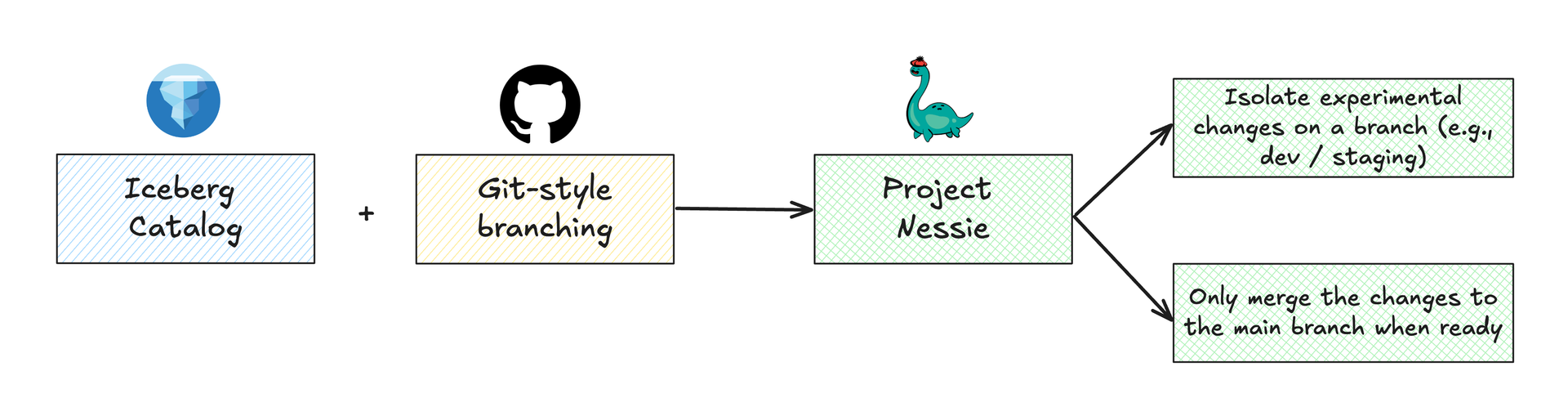
In the initial days, Nessie had its own gRPC/REST API and clients to manage commits. However, it has evolved and now supports the standard Iceberg REST Catalog spec, which enables any Iceberg-aware engine to communicate with Nessie natively.
Internally, the server keeps a “version store” commit log in a pluggable backend (in-memory, JDBC/Postgres, RocksDB, Cassandra, MongoDB, DynamoDB, etc.). When e6data, Spark, Flink, Trino, Dremio, or another engine writes through Nessie, each change is recorded as a commit in that log. And, a single commit can touch multiple tables, giving you true cross-table atomicity. This capability is either difficult or impossible to implement in Hive Metastore or AWS Glue.
As a matter of fact, Nessie enables cross-table transactions by design because a single commit in Nessie can include changes to multiple table pointers, making it possible to coordinate changes to several tables in one operation (all landing as one commit ID). This is a major advantage for data lakes that need consistent upgrades of multiple tables together.
So, How Does Nessie Work?
- Branches and tags are just references: Nessie is “Git for data.” Each branch (e.g., main, feature_x) is nothing more than a pointer to a specific commit, giving you an isolated view of every Iceberg table. When you insert data on feature_x, Nessie writes a new Iceberg metadata file and records a commit on that branch—the pointer on main stays unchanged until you merge.
- Commits are metadata-only. An INSERT writes a new Iceberg metadata file, then Nessie moves the branch pointer to that file in one optimistic-concurrency step.
- Back-ends are pluggable. For local trials, you can run the default in-memory or JDBC store; for prod, you might choose Postgres (as in the Docker compose above) or RocksDB/Cassandra for distributed scale
- Standard APIs. Because Nessie now speaks the Iceberg REST protocol, any engine or library that implements that spec—Spark 3.5, Flink 1.19, Trino 448, PyIceberg, even DuckDB, can point at http://<nessie-server-address>:19120/api/v2 and work.
What are Nessie’s Key Features?
Enough of theory. Let’s install it in our local system and play with it to understand more.
Hands-on with Project Nessie
Now that you’ve read about Nessie and what it can do, let’s get hands-on and get a real-world run with Nessie.
docker-compose.yaml
version: "3.9"
volumes:
warehouse:
nessie-db:
networks:
demo: {}
services:
# 1️⃣ Postgres 14 – Nessie commit log
nessie-db:
image: postgres:14
environment:
POSTGRES_DB: nessie
POSTGRES_USER: nessie
POSTGRES_PASSWORD: nessie
volumes: [ nessie-db:/var/lib/postgresql/data ]
healthcheck:
test: ["CMD", "pg_isready", "-U", "nessie"]
interval: 10s
retries: 5
networks: [ demo ]
# 2️⃣ Nessie server
nessie:
image: ghcr.io/projectnessie/nessie:0.104.1
# platform: linux/amd64 # ← uncomment on Apple-silicon
depends_on:
nessie-db:
condition: service_healthy
environment:
QUARKUS_HTTP_PORT: 19120
NESSIE_VERSION_STORE_TYPE: JDBC2
QUARKUS_DATASOURCE_JDBC_URL: jdbc:postgresql://nessie-db:5432/nessie
QUARKUS_DATASOURCE_USERNAME: nessie
QUARKUS_DATASOURCE_PASSWORD: nessie
ports: [ "19120:19120" ]
networks: [ demo ]
# 3️⃣ Spark 3.5 + Iceberg 1.9 + Jupyter
spark:
image: tabulario/spark-iceberg
depends_on: [ nessie ]
ports:
- "8888:8888" # Jupyter
- "4040:4040" # Spark UI
volumes:
- warehouse:/opt/warehouse
- ./conf/spark-defaults.conf:/opt/spark/conf/spark-defaults.conf:ro
- ./notebooks:/home/iceberg/notebooks:rw # ← notebooks persist
environment:
SPARK_DRIVER_MEMORY: 1G
networks: [ demo ]
Run this code for a hands-on application of what we’ve done so far. Don’t forget to refer to my comments in the code.
# ── Boot a Spark-SQL session that already knows the Iceberg + Nessie extensions
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# ── 1. Create a demo namespace + table on the *main* branch
spark.sql("CREATE NAMESPACE IF NOT EXISTS demo")
spark.sql("""
CREATE TABLE demo.sales (
id INT,
amt DOUBLE
) USING iceberg
""") # ⇒ metadata-00000.json
# insert one row on main → commit A
spark.sql("INSERT INTO demo.sales VALUES (1, 9.99)")
spark.sql("SELECT * FROM demo.sales").show() # 1 row
# ── 2. Fork the catalog state
spark.sql("CREATE BRANCH dev IN nessie") # pointer dev → commit A
spark.sql("USE REFERENCE dev IN nessie") # work on the branch
# add a second row on dev → commit B
spark.sql("INSERT INTO demo.sales VALUES (2, 19.95)")
spark.sql("SELECT * FROM demo.sales").show() # 2 rows (dev only)
# ── 3. Switch back to production and verify isolation
spark.sql("USE REFERENCE main IN nessie")
spark.sql("SELECT * FROM demo.sales").show() # still 1 row
# ── 4. Merge the dev work into main
spark.sql("MERGE BRANCH dev INTO main IN nessie") # fast-forward main → B
spark.sql("REFRESH TABLE demo.sales") # force Spark to reload metadata
spark.sql("SELECT * FROM demo.sales").show() # main now shows 2 rows
Apache Gravitino
Apache Gravitino (incubating) takes an amplified view of the catalog problem. It is described as a “high-performance, geo-distributed, and federated metadata lake.” In simpler terms, Gravitino is a unified metadata and governance platform that acts as an Iceberg table catalog and federates metadata from many different sources and regions.
It was developed (and open-sourced) by the company Datastrato, and it aims to let you manage metadata and govern data across all your data sources, including cloud storage systems (data lakes), relational databases, streaming systems, and more, under one umbrella. This means Gravitino isn’t limited to just Iceberg or just one kind of data; it’s built to be a single source of truth for metadata in a large, heterogeneous data environment.
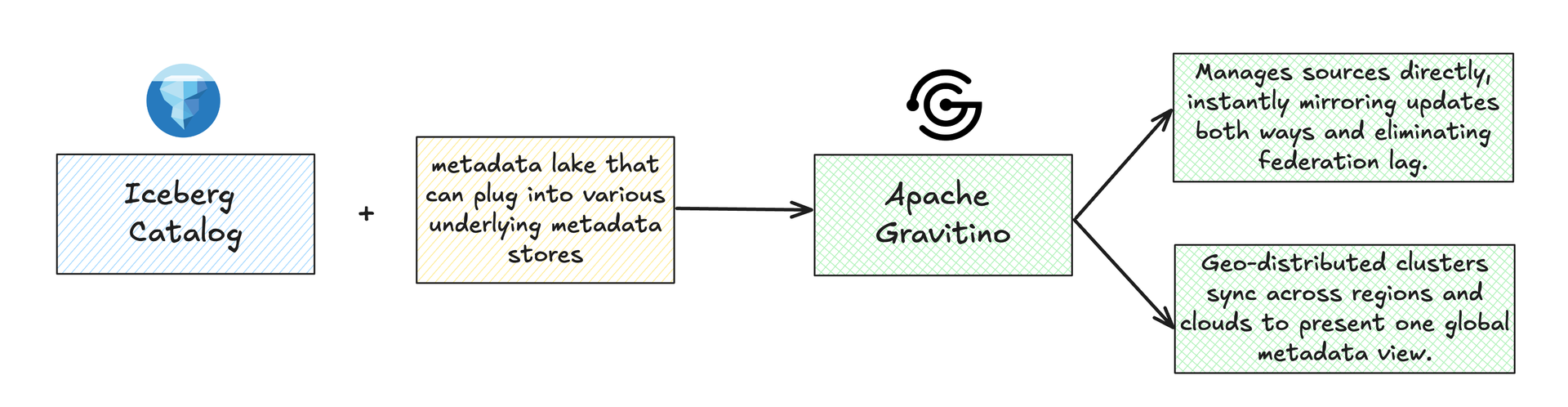
How Does Apache Gravitino Work?
- Provides a technical data catalog and metadata lake that plug into multiple underlying metadata stores through extensible connectors.
- Can pull in or directly manage metadata from sources such as Hive Metastore, relational database catalogs, and file systems, exposing everything through a unified API.
- Manages these systems directly, so updates in Gravitino or in an underlying source are reflected immediately in the other, eliminating lag or mismatches common in periodic-sync catalogs.
- Features a geo-distributed architecture: instances deployed in different regions or clouds coordinate to share metadata, giving users a global, continuously synchronized catalog across data centers.
- Builds on Apache Iceberg’s table format and REST catalog concepts, with plans to extend support to other formats like Hudi and Delta Lake.
- Strives to act as a universal metadata hub for varied table formats and AI/ML assets.
What are Gravitino's Key Features?
Apache Polaris
Apache Polaris (incubating) is an open-source, fully-featured catalog for Apache Iceberg tables. It was originally developed by Snowflake and contributed to Apache, with the goal of being a vendor-neutral Iceberg catalog. Polaris implements Iceberg’s standard REST API for interoperability across many engines (e6data, Spark, Flink, Trino, Dremio, StarRocks, Apache Doris, etc.) and allows them all to create, update, and manage Iceberg tables through a single service.
Essentially, Polaris decouples table metadata from any one compute platform. You can run Polaris as a centralized Iceberg catalog on your own infrastructure (or hosted in Snowflake’s cloud) and have different analytics engines use it concurrently without each needing its own metastore. The incredible bit is that this avoids siloed metadata and duplication of data for different tools.
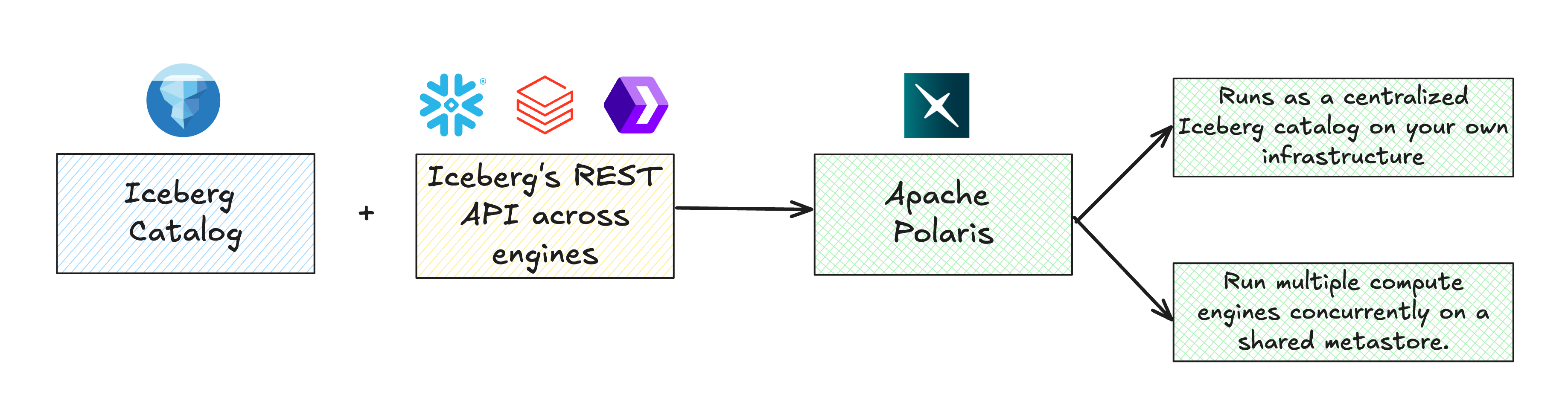
How Does Polaris Work?
- Acts as a RESTful server that tracks Iceberg table metadata and schema definitions.
- Client engines (e.g., Spark, Trino) interact with Polaris through REST API calls to read or write Iceberg tables.
- Applies metadata changes atomically (such as committing new snapshots) ensuring ACID guarantees for table operations.
- Designed for vendor neutrality: data can reside on any cloud object storage (S3, GCS, Azure Blob, etc.), with an abstraction layer that hides metadata location and format from engines.
- Supports namespaces and catalogs to organize tables logically; a single deployment can host multiple catalogs.
- Operates in two table modes:
- Internal tables: fully managed by Polaris with full read/write access.
- External tables: managed by another catalog (e.g., Hive, Glue); Polaris treats them as read-only mirrors.
- Federation capability lets you gradually migrate from other metastores (e.g., start with Glue or Snowflake in read-only mode, then shift management to Polaris).
- Enables hybrid deployments and avoids forcing an all-or-nothing migration path.
What are Apache Polaris’ Key Features?
Lakekeeper
Lakekeeper is another open-source Iceberg catalog but with a different philosophy. It emphasizes simplicity, performance, and security. It is described as “a secure, fast, and user-friendly Apache Iceberg REST Catalog built with Rust” and aims to be a lean and efficient catalog service that is easy to deploy and integrate.
Lakekeeper was started by independent contributors (with a growing community around it) and is released under the Apache License. While Apache Polaris and Gravitino are large-scale projects with backing from big companies, Lakekeeper represents a more lightweight approach: it’s written in Rust (for performance and safety) and distributes as a single binary you can run anywhere (no heavy dependencies like a JVM or big database required).
Despite its lighter footprint, Lakekeeper fully implements the standard Iceberg REST API, meaning it can be used by any engine that speaks that API, similar to Polaris and Gravitino.
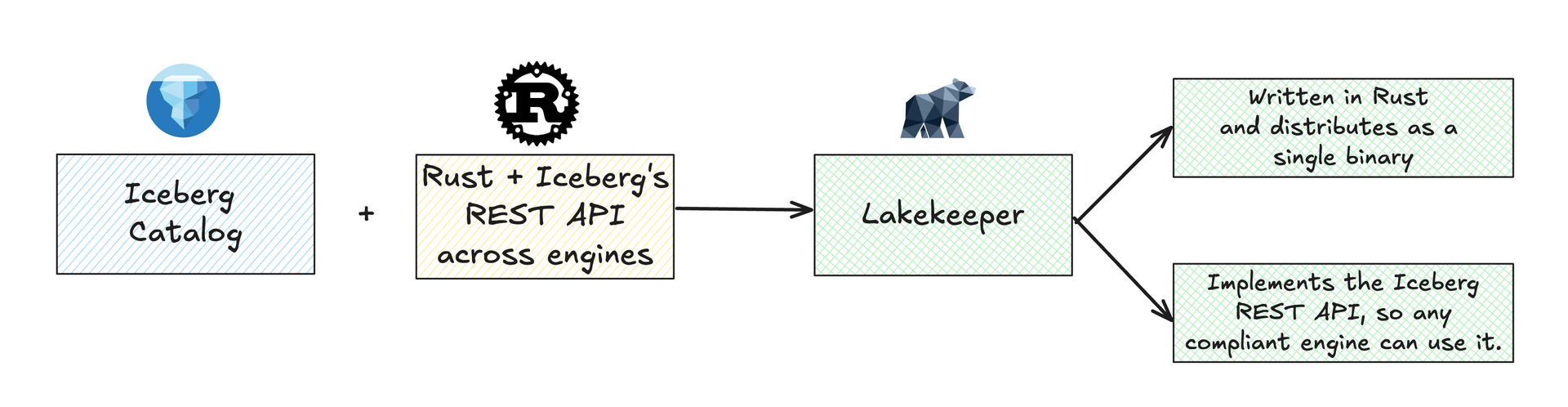
How Does Lakekeeper Work?
- Architecture mirrors other Iceberg REST catalogs, featuring a server component that clients register with.
- Spark or Flink jobs invoke Lakekeeper REST endpoints to create or update Iceberg tables; Lakekeeper manages commit logic and metadata storage.
- Internally, metadata is stored in a relational (normalized) database—either an embedded store or an external SQL database.
- This design lets Lakekeeper query and update metadata efficiently and add capabilities (e.g., metadata analytics) without scanning object-storage metadata files.
- Compared with a pure “on-file” catalog like Hadoop Catalog, Lakekeeper can more easily provide global statistics, fast lookups, and multi-table transactions.
- Server-side commits run inside a single database transaction, enabling true atomic commits that span multiple tables—something traditional metastore catalogs (e.g., Hive) lack.
- Distributed as one compiled binary, so it deploys smoothly on a laptop for local tests or in Kubernetes for production.
- Includes a web UI and a Helm chart for Kubernetes, simplifying initial setup.
What are Lakekeeper's Key Features?
Databricks Unity Catalog
Databricks Unity Catalog is a bit different from the other catalogs discussed, as it originated as a proprietary offering from Databricks rather than an Apache open-source project. Unity Catalog is essentially Databricks’ unified governance solution for data and AI assets across the lakehouse.
Unity Catalog was introduced to provide Databricks customers with a single interface to manage all their tables, files, and machine learning assets (models, etc.) with fine-grained governance. The big news, however, is that in mid-2024, Databricks open-sourced Unity Catalog under the Apache 2.0 license, aiming to make it the industry’s first truly open universal catalog for data and AI.
The project is now hosted under the Linux Foundation (LF AI & Data) rather than Apache, but it’s developed in the open with an API-first approach. Unity Catalog’s importance lies in bridging the gap between traditional data governance (for tables/files) and AI governance (for ML models and more), all while supporting multiple data formats and execution engines.
How Does Unity Catalog Work?
Unity Catalog supplies a central metadata and permission store unified along three dimensions: multi-format, multi-engine, and multimodal.
- Multi-format
- Catalogs data in Delta Lake (Databricks’ native table format) as well as Apache Iceberg, Parquet, CSV, and others.
- Introduces UniForm, which presents Delta tables in an Iceberg-compatible way so Iceberg clients can read Delta files, achieving interoperability between formerly competing standards.
- Multi-engine
- Exposes open interfaces such as a Hive Metastore-compatible API and the Iceberg REST API, enabling many processing engines to use Unity Catalog as their catalog.
- Allows tools like Trino clusters or PyIceberg notebooks to query data governed by Unity Catalog, not just Databricks Spark clusters.
- Targets becoming a universal data-access layer instead of being tied only to Databricks runtimes.
- Multimodal
- Governs traditional tabular data, unstructured files, machine-learning models, ML experiment tracking, and even AI “functions” or tools as first-class entities.
- Provides a single namespace where all these asset types can be registered side by side and have access controlled consistently.
What are the Key Features of Unity Catalog?
In Conclusion
I reiterate that the catalog war is still alive. Through the course of this blog, we traced how Iceberg’s classic catalogs (Hadoop, Hive, and Glue) provide essential features: a pointer swap, leaving gaps around branching, cross-table consistency, and governance.
To go beyond this and add features that data engineers need is where modern catalogs such as Nessie, Polaris, Gravitino, Lakekeeper, and Unity make the cut. They speak the Iceberg REST dialect while layering Git-style version control, federated views, fine-grained policies, and multi-engine freedom.
Together, these emerging catalogs prove that a catalog is no longer just a phone book but a contract that lets every engine collaborate confidently on the same lake, with safeguards baked in and silos designed out. Whether you prize immutable histories, geo-scalable metadata, or a lean Rust binary you can run anywhere, the toolbox now exists, and the next move is yours. Choose boldly, experiment early, and let your lakehouse flourish!
Listen to the full podcast
Share this article
FAQs
What is an Apache Iceberg catalog, and why do I need one?
It’s the external metadata store that tracks every Iceberg table’s schema, partitioning, and current snapshot. The catalog keeps a single pointer to the latest `metadata.json`, letting any engine (Spark, Trino, Flink, etc.) read or write the table with ACID guarantees and time-travel. Without it, the lake is just files.
Why are traditional catalogs insufficient for modern lakehouses?
Lakehouses now demand Git-style branching, multi-table atomic commits, multi-cloud deployments, and fine-grained RBAC. Classic catalogs weren’t built for these needs, so teams face data-loss risk, slow directory scans, S3 rename quirks, and limited transaction scope—prompting the rise of newer REST catalogs that fill those gaps.
Which emerging catalog should I choose for cross-table transactions?
If you need guaranteed cross-table atomicity, choose catalogs designed for it—Project Nessie and Lakekeeper both wrap multiple table updates in a single commit. Traditional Hadoop, Hive Metastore, and AWS Glue can only commit one table at a time, risking partial state when ETL touches several tables.
What unique features does Project Nessie add to Iceberg cataloging?
Project Nessie layers Git-like branches and tags over Iceberg. Every change is stored as a commit in a pluggable backend, and a single commit can touch many tables. That lets you experiment on an isolated branch, merge when ready, and guarantees cross-table atomicity missing from HMS or Glue.
.svg)
.svg)
.svg)
.svg)
Available at
.png)

.svg)